This repository is part of the solutions for the course Computational Intelligence Lab at ETH Zurich, Spring Semester 2021. Our solution achieved first place on the leaderboard for Collaborative Filtering.
Abstract: Collaborative filtering methods for recommender systems find their application in a wide variety of areas. In this work we consider several neural-based and standard matrix-factorization-based models, placing our focus on Bayesian Factorization Machines. We extended these by adding additional features such as implicit user/item information, multiple user similarity measures, item distance metrics, as well as unsupervised-learned clusters and report results in an extensive benchmark.
Contains the following algorithms:
- Singular Value Decomposition
- Non-Negative Matrix Factorization
- Autoencoder
- Autorec
- Neural Collaborative Filtering
- Kernel Net
- Bayesian Factorization Machine
Validation RMSE for different Matrix-Factorization-based Approaches:
![]()
Validation RMSE for different rank values. NMF performs best with a rank of 24 while others peak around 8 to 12.
Validation RMSE for different Neural-based Approaches:

Validation RMSE for different epochs. AutoRec and NCF diverge after a few epochs while KernelNet and AE show the opposite behaviour.
Heatmap of Bayesian Factorization Machine:
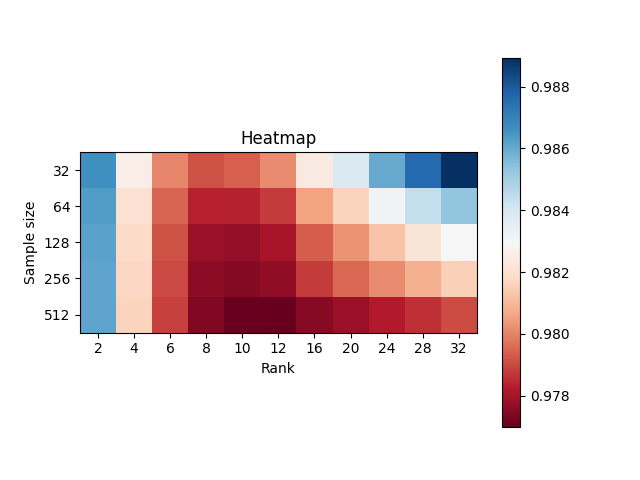
Validation RMSE for different values of sample size and rank. We conduct the hyperparameter search on our second best model, BMF SVD++ flipped, due to the high computational burden of our best. Low-rank approximations of 8 to 12 with high sampling sizes perform best.
Use Python version 3.7.4
conda create --name collaborative-filtering python=3.7.4
conda activate collaborative-filtering
pip install --user -r requirements.txt
python main.py
This will reproduce the best submitted Kaggle result. However, note that this may take up to 2 days to finish.
python cv_experiments.py
This will reproduce the results used for generating the plots of the report.
python movie_clustering.py
python movie_distance.py
This will create the matrices used for movie features in the Bayesian Factorization Machine model. Note that Jaccard indices will only be calculated on the fly, if not downloaded beforehand. The Jaccard indices can be downloaded from Polybox and put them into data/features.
In order to reproduce plots one needs to download the cross-validation results from Polybox or run
the cross validation explained above to get the files.
The files that need to be downloaded are: bfm.hkl, bfm_svdpp.hkl, bfm_svdpp_flipped.hkl, svd.hkl. These files need to be put into the root directory.
For reproducing the data for the validation plot one can either run the experiments from scratch or download from Polybox the following files:
autoencoder.npy, autorec.npy, kernel_net.npy, ncf.npy and put them into the root directory.
This will create plots
python plot_generator.py
To build the report, simply call:
cd report
bash build-paper.sh