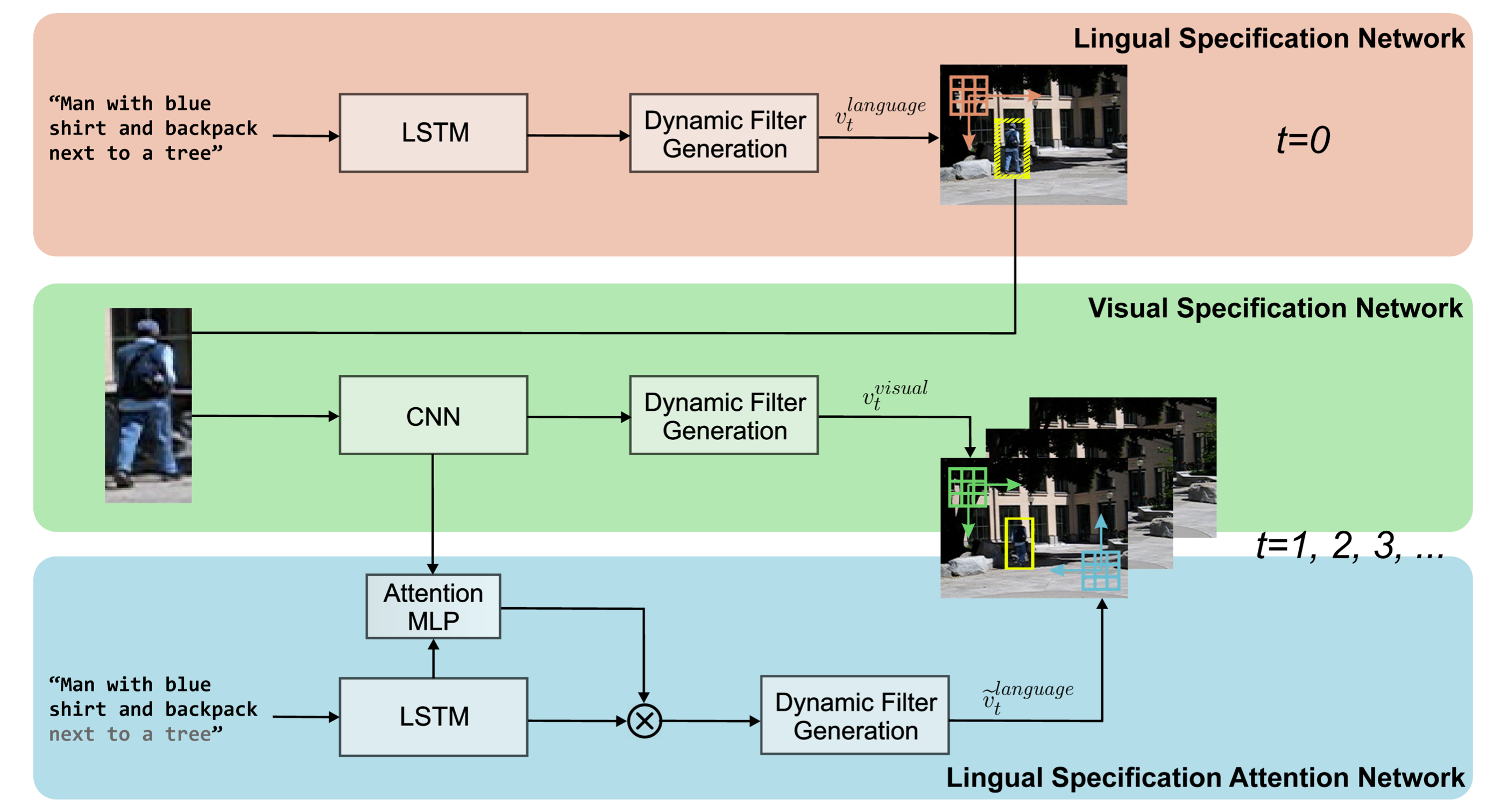
This repository contains the code for the following paper:
- Z. Li, R. Tao, E. Gavves, C. G. M. Snoek, A. W. M. Smeulders, Tracking by Natural Language Specification, in Computer Vision and Pattern Recognition (CVPR), 2017 (PDF)
@article{li2017cvpr,
title={Tracking by Natural Language Specification},
author={Li, Zhenyang and Tao, Ran and Gavves, Efstratios and Snoek, Cees G. M. and Smeulders, Arnold W. M.},
journal={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
Lingual Lingual OTB99 Sentences
Lingual ImageNet Sentences
Please note that we use all the frames from original OTB100 dataset in our OTB99 videos, while for ImageNet videos we may only select a subsequence (see start/end frames we selected for each video in train.txt or test.txt).
- Caffe branch here (Note:
langtrackV3branch notmasterbranch) - Compile Caffe with option
WITH_PYTHON_LAYER = 1
-
Download natural language segmentation model caffemodel and copy to
MAIN_PATH/snapshots/lang_high_res_seg/_iter_25000.caffemodel -
Download tracking model caffemodel and copy to
MAIN_PATH/VGG16.v2.caffemodel
Here we first demostrate how the model II in the paper works with example videos:
- Given an image and a natural language query, how to identify a target (applied on the first query frame of a video only)
demo/lang_seg_demo.ipynb
- Given a visual target (a box identified from step 1) and a sequence of frames, how to track the object in all the frames
demo/lang_track_demo.ipynb