The ping-pong benchmark test of evpp against Boost.Asio
Boost.Asio is a cross-platform C++ library for network and low-level I/O programming that provides developers with a consistent asynchronous model using a modern C++ approach.
- evpp-v0.2.4 based on libevent-2.0.21
- asio-1.10.8
- Linux CentOS 6.2, 2.6.32-220.7.1.el6.x86_64
- Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
- gcc version 4.8.2 20140120 (Red Hat 4.8.2-15) (GCC)
The benchmark test in benchmark_throughput_vs_asio.md used the fixed size message to do the ping-pong protocol benchmark.
This test we use the message whose length is increasing by 1 every time to test the ping pong protocol. Every message consists of a header and a body. The header is defined as bellow:
#pragma pack(push,1)
struct Header {
uint32_t body_size; // net order
uint32_t packet_count; // net order
};
#pragma pack(pop)At the very begining we set Header.packet_count=1 and Header.body_size=100. When the client establishes a connection with the server, the client send to server the first message #1 which is a 108 bytes length. After the server receives the message, the server increases the packet count, which sets Header.packet_count=2 and Header.body_size=100, and send to client a new message #2 which is a 108 bytes length. And then the client receives the message #2, and increases the packet count and body size, which sets Header.packet_count=3 and Header.body_size=101, and send to server a new message #3 which is a 109 bytes length. And so on ... . Until we the packet_count grows up to a total_count which is passed by the command line argument parameter.
The test code of evpp is at the source code benchmark/throughput_header_body/evpp, and at here https://github.com/Qihoo360/evpp/tree/master/benchmark/throughput_header_body/evpp. We use tools/benchmark-build.sh to compile it. The test script is m3.sh.
The test code of asio is at https://github.com/huyuguang/asio_benchmark using commits 21fc1357d59644400e72a164627c1be5327fbe3d and the client3.cpp, server3.cpp test code. The test script is m3.sh. It is:
killall asio_test.exe
totalcount=${totalcount:-8192}
#Usage: asio_test server3 <address> <port> <threads> <totalcount>
#Usage: asio_test client3 <host> <port> <threads> <totalcount> <sessions>
for nosessions in 100 1000 10000; do
for nothreads in 1 2 3 4 6 8; do
echo "======================> (test1) TotalCount: $totalcount Threads: $nothreads Sessions: $nosessions"
sleep 1
./asio_test.exe server3 127.0.0.1 33333 $nothreads $totalcount & srvpid=$!
sleep 1
./asio_test.exe client3 127.0.0.1 33333 $nothreads $totalcount $nosessions
sleep 1
kill -9 $srvpid
sleep 5
done
doneWe have done a benchmark with following parameters
- Thread number is 1/2/3/4/6/8
- The number of concurrent connections is 100/1000/10000
- The total_count is 8192
- In almost all the cases, the benchmark data shows evpp's performance is better than asio
- In most cases, evpp's performance is about 5%~20% higher than asio
For details, please see the charts below. The horizontal axis is the number of thread count. The vertical axis is the time spent, the lower is the better.

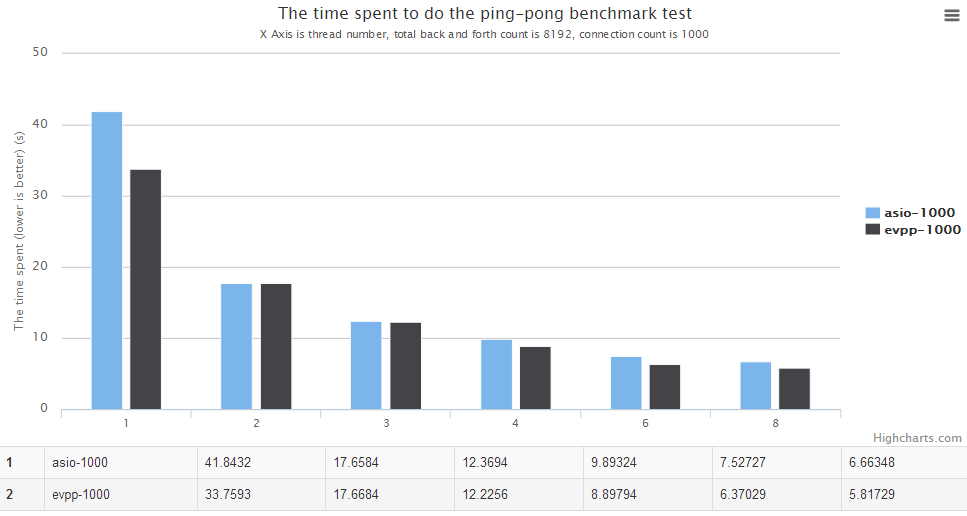
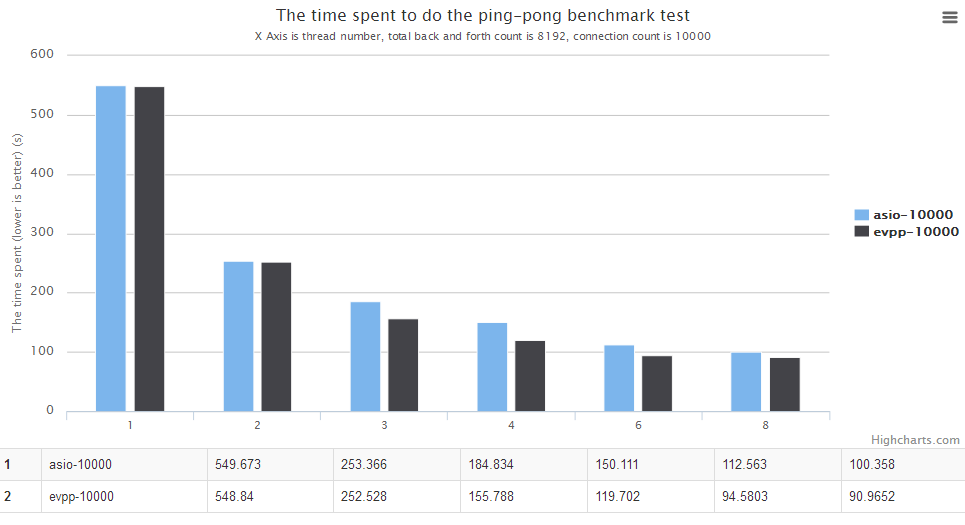
In this ping pong benchmark test, the asio's logic is :
- Firstly reads the 8 bytes of header
- And reads the body data according to header->body_size
This will do the recv system call twice at least for every single message.
In the mean time, evpp is reactor model, it will try to read data as much as possible, maybe it does the recv system call only one time for every single message. That's the key point why evpp is faster than asio in this scenario. And this scenario is the most common in the real world applications. So we can say evpp's performance is a little bit higher than asio, at least not bad to asio.
The IO Event performance benchmark against Boost.Asio : evpp is higher than asio about 20%~50% in this case
The ping-pong benchmark against Boost.Asio : evpp is higher than asio about 5%~20% in this case
The throughput benchmark against libevent2 : evpp is higher than libevent about 17%~130% in this case
The performance benchmark of queue with std::mutex against boost::lockfree::queue and moodycamel::ConcurrentQueue : moodycamel::ConcurrentQueue is the best, the average is higher than boost::lockfree::queue about 25%~100% and higher than queue with std::mutex about 100%~500%
The throughput benchmark against Boost.Asio : evpp and asio have the similar performance in this case
The throughput benchmark against Boost.Asio(中文) : evpp and asio have the similar performance in this case
The throughput benchmark against muduo(中文) : evpp and muduo have the similar performance in this case
The beautiful chart is rendered by gochart. Thanks for your reading this report. Please feel free to discuss with us for the benchmark test.