
SpideyX - A Web Reconnaissance Penetration Testing tool for Penetration Testers and Ethical Hackers that included with multiple mode with asynchronous concurrne performance. Spideyx is a tool that have 3 seperate modes and each mode are used for different approach and different methods, Spideyx is one tool but it equal to 3 tools because it have ability to crawling, Jsscraping, parameter fuzzing.
Install using pip:
pip install git+https://github.com/RevoltSecurities/SpideyX.gitInstall using pipx
pipx install spideyxInstall using git
git clone https://github.com/RevoltSecurities/SpideyX
cd Spideyx
pip install .these are methods that install spideyx succesfully into your machiene and ready to execute, but how to use the spideyx
spideyx -h _ __ _ __
_____ ____ (_) ____/ / ___ __ __ | |/ /
/ ___/ / __ \ / / / __ / / _ \ / / / / | /
(__ ) / /_/ / / / / /_/ / / __/ / /_/ / / |
/____/ / .___/ /_/ \__,_/ \___/ \__, / /_/|_|
/_/ /____/
@RevoltSecurities
[DESCRIPTION]: spideyX - An asynchronous concurrent web penetration testing multipurpose tool
[MODES]:
- crawler : spideyX asynchronous crawler mode to crawl urls with more user controllables settings.
- paramfuzzer : spideyX pramfuzzer mode , a faster mode to fuzz hidden parameters.
- jsscrapy : spideyX jsscrapy mode, included with asynchronous concurrency and find hidden endpoint and secrets using yaml template based regex.
- update : spideyX update mode to update and get latest update logs of spideyX
[FLAGS]:
-h, --help : Shows this help message and exits.
[Usage]:
spideyx [commands]
Available Commands:
- crawler : Executes web crawling mode of spideyX.
- paramfuzzer : Excecutes paramfuzzer bruteforcing mode of spideyX.
- jsscrapy : Executes jscrawl mode of spideyX to crawl js hidden endpoints & credentials using template based regex.
- update : Executes the update mode of spideyX
Help Commands:
- crawler : spideyx crawler -h
- paramfuzzer : spideyx paramfuzzer -h
- jsscrapy : spideyx jsscrapy -h
- update : spideyx update -hSpideyX have 3 different mode that used for 3 different purposes and thse are the modes of SpideX:
- crawler
- jsscrapy
- paramfuzzer
SpideyX Crawler Mode is more than just another web crawling tool. It provides advanced capabilities for both active and passive crawling of web applications. Whether you need to explore URLs recursively with a specified depth or perform comprehensive passive crawling using various external resources, SpideyX has you covered.
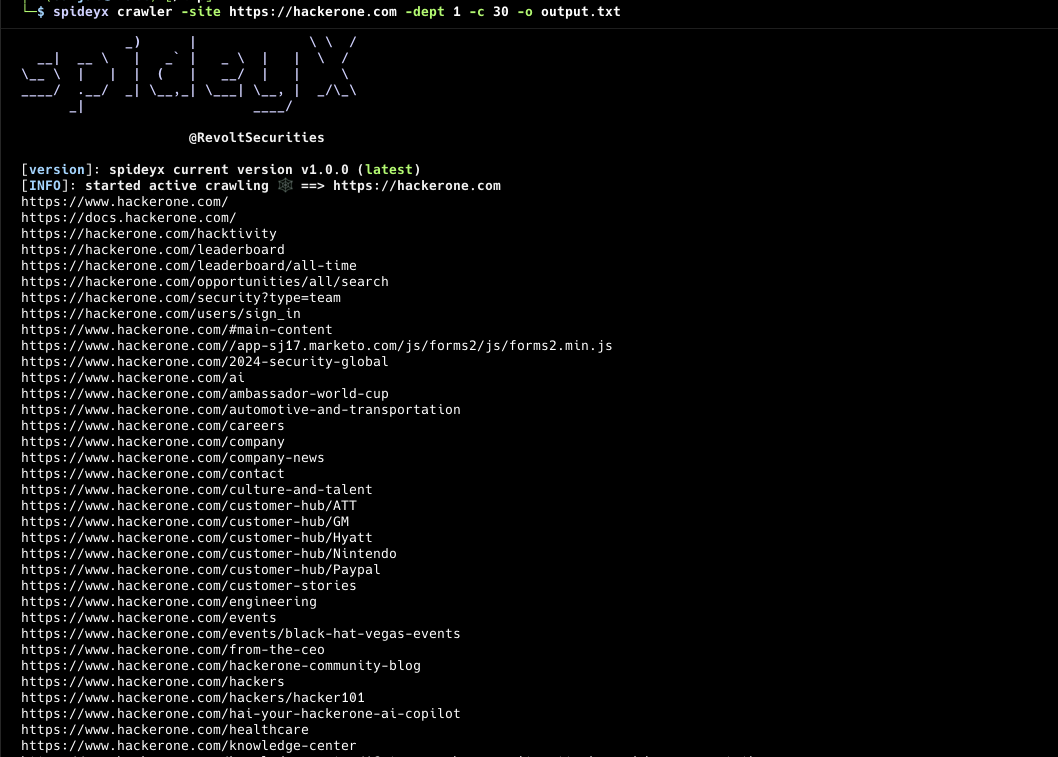
- Customizable crawl scope
- Customization output filtering,matching,regex,hosts
- Concurrent dept recursion crawling
- Customizable html tags & attributes for crawling
- Authenticated active crawling
- HTTP/2 supported
- Active & Passive crawling supported
- Input: stdin, url, file
- Output: file, stdout
- Random useragent for each crawling request
spideyx crawler -h .__ .___
____________ |__| __| _/ ____ ___.__.___ ___
/ ___/\____ \ | | / __ | _/ __ \ < | |\ \/ /
\___ \ | |_> >| |/ /_/ | \ ___/ \___ | > <
/____ >| __/ |__|\____ | \___ > / ____|/__/\_ \
\/ |__| \/ \/ \/ \/
@RevoltSecurities
[MODE]: spideyX crawler mode!
[Usage]:
spidey crawler [options]
Options for crawler mode:
[input]:
-site, --site : target url for spideyX to crawl
-sties, --sites : target urls for spideyX to crawl
stdin/stdout : target urls for spideyX using stdin
[configurations]:
-tgs, --tags-attrs : spideyx crawling tags can be configured using this flags you can control spideyx crawling (ex: -tgs 'a:href,link:src,src:script')
-dept, --dept : dept value to crawl for urls by spideyx (info: only in active crawling) (default: 1)
-X, --method : request method for crawling (default: get) (choices: "get", "post", "head", "put", "delete", "patch", "trace", "connect", "options")
-H, --headers : custom headers & cookies to send in http request for authenticated or custom header crawling
-ra, --random-agent : use random user agents for each request in crawling urls instead of using default user-agent of spideyx
-to , --timeout : timeout values for each request in crawling urls (default: 15)
-px, --proxy : http proxy url to send request via proxy
-ar, --allow-redirect : follow redirects for each http request
-mr, --max-redirect : values for max redirection to follow
-mxr, --max-redirection : specify maximum value for maximum redirection to be followed when making requests.
-cp, --config-path : configuration file path for spideyX
--http2, --http2 : use http2 protocol to give request and crawl urls, endpoints
[scope]:
-hic, --host-include : specify hosts to include urls of it and show in results with comma seperated values (ex: -hc api.google.com,admin.google.com)
-hex, --host-exclude : speify hosts to exclude urls of it and show in results with comma seperated values (ex: -hex class.google.com,nothing.google.com)
-cs, --crawl-scope : specify the inscope url to be crawled by spideyx (ex: -cs /api/products or -cs inscope.txt)
-cos, --crawl-out-scope : specify the outscope url to be not crawled by spideyx (ex: -cos /api/products or -cos outscope.txt)
[filters]:
-em, --extension-match : extensions to blacklist and avoid including in output with comma seperated values (ex: -wl php,asp,jspx,html)
-ef, --extension-filter : extensions to whitelist and include in output with comma seperated values (ex: -bl jpg,css,woff)
-mr, --match-regex : sepcify a regex or list of regex to match in output by spideyx
-fr, --filter-regex : specify a regex or list of regex to exclude in output by spideyx
[passive]:
-ps, --passive : use passive resources for crawling (alienvault, commoncrawl, virustotal)
-pss, --passive-source : passive sources to use for finding endpoints with comma seperated values (ex: -pss alienvault,virustotal)
[rate-limits]:
-c, --concurrency : no of concurrency values for concurrent crawling (default: 50)
-pl, --parallelism : no of parallelism values for parallel crawling for urls (default: 2)
-delay, --delay : specify a delay value between each concurrent requests (default: 0.1)
[output]:
-o, --output : output file to store results of spideyX
[debug]:
-s, --silent : display only output to console
-vr, --verbose : increase the verbosity of the outputFile Input:
spideyx crawler -sites urls.txtUrl Input:
spideyx crawler -site https://hackerone.comStdin Input:
cat urls.txt | spideyx crawler -dept 5subdominator -d hackerone.com | subprober -nc | spideyx crawlerAuthenticated Crawling:
Using the -H or --headers flag, spideyx enables crawling of protected endpoints that require authentication. By including headers such as Authorization: Bearer or Cookie: sessionid=, spideyx crawler mode simulates an authenticated user session. This grants access to sections of the website that are not available to unauthenticated crawlers, such as user profiles, dashboards, or admin areas. This feature helps ensure that the crawling process explores all available resources, providing a more comprehensive security assessment.
echo https://target.com | spideyx crawler -dept 5 -H Authorization eyhweiowuaohbdabodua.cauogodaibeajbikrba.wuogasugiuagdi -H X-Bugbounty-User user@wearehackerone.comDept Crawling:
-
Controlled Exploration Depth: The -dept flag defines how deep the crawler should go into a website's structure, limiting or expanding exploration based on levels of linked pages from the starting URL.
-
Efficient Resource Management: By setting a depth limit, users can prevent the crawler from going too deep into the site, reducing resource consumption and focusing on more relevant sections of the web application.
Filters & Matching:
SpideyX can filter and match your output using extensions, regex, hosts, regex and for that you can use flags -em ,--extentsion-match to match the desired extensions in the urls
spideyx crawler -site https://hackerone.com -em .js,.jsp,.asp,.apsx,.phpand you can filter extension using falgs: -ef, --extension-filters or spideyx have predefined blacklist of extensions not to crawl or include in output.
spideyx crawler -site https://hackerone.com -ef .css,.woff,.woff2,.mp3,.mp4,.pdf
Sometimes you dont want to include some subdomains of your target to not to crawl and here spideyx can also include and exclude host using flag: -hic, --host-include these can be used to match hosts you want to include.
spideyx crawler -site https://hackerone.com -hic developer.hackerone.com,www.hackerone.com,hackerone.comSpideyx can also exclude the hosts to not include in crawling scope and you can use these flags: -hex, --host-exclude
spideyx crawler -site https://hackerone.com -hex www.hackerone.com,hackerone.comTag and Attribute Configuration:
-tgs, --tags-attrs
Configure which HTML tags and attributes SpideyX should crawl. This flag allows you to control the crawling behavior by specifying tags and attributes of interest.
Example: -tgs 'a:href,link:src,src:script'
Description: This option tells SpideyX to look for and extract URLs from href attributes in tags, src attributes in tags, and src attributes in <script> tags. Custom configurations help focus the crawling on specific parts of web pages, enhancing the relevance of the data collected.
spideyx crawler -site https://hackerone.com -tgs 'a:href,link:src'Regex Filtering & Matching:
Spideyx can crawl and include the output the regex you define to it and these can done using flags: -mr,--match-regex, -fr, --filter-regex
Regex Matching:
Using the falgs: -mr,--match-regex will help you to define your regex and add it to crawl
spideyx crawler -site https://hackerone.com -mr 'https://support.hackerone.com/*'Regex Matching:
To filter your results using regex you can use flags: -fr, --filter-regex
spideyx crawler -site https://hackerone.com -fr 'https://developer.hackerone.com/*'Defining you own scope when crawling help you to crawl only desired endpoint to crawl with maximum dept and this helps your crawling to be more accurate with desired endpoints you need.
Defining your crawl scope:
Controlling your scope with SpideyX is very easy using: -cs & --crawl-scope
spideyx crawler -site https://random.hackerone.com -cs /wp-adminand for multiple inscope deinition you can pass the file scope.txt
cat scope.txt
/admin/api/v1
/wp-admin/
/user/api/v1spideyx crawler -site https://random.hackerone.com -cs scope.txtDefining crawling out of scope:
Controlling your scope with SpideyX is very easy using: -cos & --crawl-out-scope
spideyx crawler -site https://random.hackerone.com -cos /logoutspideyx crawler -site https://random.hackerone.com -cos outscope.txtSpidex concurrency can be controlled to instruct spidey how much concurrent, delay and paralellism to used when crawling and this can be done easily in spideyx crawl mode!
This flag enables passive crawling, where Spideyx gathers data from external sources like AlienVault, VirusTotal, and CommonCrawl.
Example:
spideyx crawler -site https://example.com --passiveYou can specify which passive sources to use for gathering endpoint information.
Example:
spideyx crawler -site https://example.com --passive-source alienvault,commoncrawlThis flag allows you to control the number of concurrent requests Spideyx makes during crawling. The default value is 50.
Example:
spideyx crawler -site https://example.com --concurrency 20You can specify how many parallel tasks Spideyx should run. This is useful when crawling with large list of urls and crawl concurrently
Example:
spideyx crawler -sites urls.txt --parallelism 5To avoid overwhelming the target server, you can set a delay between concurrent requests.
Example:
spideyx crawler -site https://example.com --delay 1This flag specifies the output file where the crawl results will be saved.
Example:
spideyx crawler -site https://example.com --output results.txtIn silent mode, only the output is shown on the console, suppressing additional information.
Example:
spideyx crawler -site https://example.com --silentVerbose mode increases the level of detail in the output, which is useful for debugging.
Example:
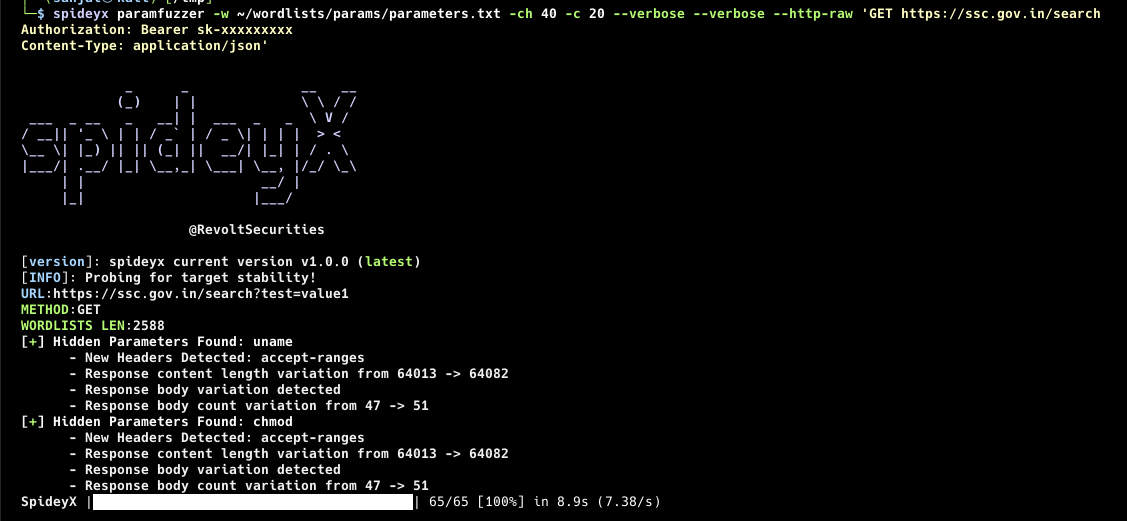
spideyx crawler -site https://example.com --verboseSpideyX Paramfuzzer Mode allows you to efficiently fuzz parameters for a target URL using wordlists. With highly customizable configurations, you can fine-tune your requests, whether through headers, body data, or request methods. This mode supports concurrent fuzzing and can handle authenticated fuzzing sessions with headers and cookies and provide more controls than other existing tools.
SpideyX also provides rate-limiting controls and the ability to handle multiple parameters at once by sending requests in chunks, improving the overall fuzzing performance.
- Customizable headers & cookies for authenticated parameter fuzzing - Body data fuzzing with dynamic parameter insertion - Supports raw HTTP request fuzzing - Concurrent fuzzing with customizable chunks of parameters - Input and output options for flexibility in integration with other tools - Rate-limiting and request delay controls - Random user-agent support for each fuzzing request
spideyx paramfuzzer -h .__ .___
____________ |__| __| _/ ____ ___.__.___ ___
/ ___/\____ \ | | / __ | _/ __ \ < | |\ \/ /
\___ \ | |_> >| |/ /_/ | \ ___/ \___ | > <
/____ >| __/ |__|\____ | \___ > / ____|/__/\_ \
\/ |__| \/ \/ \/ \/
@RevoltSecurities
[MODE]: spideyX paramfuzzer mode!
[Usage]:
spidey paramfuzzer [options]
Options for paramfuzzer mode:
[input]:
-site, --site : target URL for spideyX to paramfuzz
-sites, --sites : target URLs for spideyX to paramfuzz
-w, --wordlist : wordlist file that contains parameters for fuzzing
stdin/stdout : use stdin or stdout for target URLs
[configurations]:
-H, --header : custom headers & cookies to include in the requests for authenticated or custom header parameter fuzzing
-X, --method : HTTP request method for parameter fuzzing (default: GET) (choices: "get", "post", "head", "put", "delete", "patch", "trace", "connect", "options")
-to , --timeout : timeout value for each request (default: 15 seconds)
-px, --proxy : HTTP proxy URL to send requests via a proxy
-dr, --disable-redirect : disable following redirects for each HTTP request
-ch, --chunks : send parameters in chunks from the wordlist (default: 100)
-body, --body : specify a request body with the $pideyx placeholder to be replaced by chunked parameters (ex: `-body '{"user":"admin", "$pideyx"}' -fmt json`)
-fmt, --format : specify the format of the body content (choices: "json", "xml", "html")
--http-raw : pass a raw HTTP request for fuzzing parameters (see documentation for details)
-ra, --random-agent : use random user agents for each fuzzing request
[rate-limits]:
-c, --concurrency : specify the number of concurrent requests (default: 5)
-delay, --delay : specify the delay between concurrent requests (default: 0.1 seconds)
[output]:
-o, --output : specify the output file for storing the fuzzing results
[debug]:
-s, --silent : display only output to the console
-vr, --verbose : increase verbosity of the outputFile Input:
spideyx paramfuzzer -sites urls.txt -w wordlist.txtUrl Input:
spideyx paramfuzzer -site https://example.com -w params.txtStdin Input:
cat urls.txt | spideyx paramfuzzer -w params.txtAuthenticated Param Fuzzing:
Using the -H or --header flag, you can perform authenticated fuzzing by including custom headers such as Authorization or Cookie.
spideyx paramfuzzer -site https://target.com -w params.txt -H 'Authorization: Bearer <token>' -H 'X-Bugbounty-User: user@hackerone.com'Spideyx allows fuzzing within the body of a request using the $pideyx placeholder, which is replaced by chunked parameters during fuzzing.
Example:
spideyx paramfuzzer -site https://target.com -w params.txt -body '{"username":"admin", "password":"$pideyx"}' -fmt jsonControl how many concurrent requests are sent, as well as the delay between requests, to prevent overwhelming the target.
Concurrency Example:
spideyx paramfuzzer -site https://example.com -w params.txt --concurrency 10Delay Example:
spideyx paramfuzzer -site https://example.com -w params.txt --delay 0.5You can store the results of the fuzzing session in a file using the -o or --output flag.
Example:
spideyx paramfuzzer -site https://example.com -w params.txt --output results.txtIncrease verbosity with the --verbose flag for detailed output, or suppress unnecessary information using the --silent flag.
Verbose Example:
spideyx paramfuzzer -site https://example.com -w params.txt --verboseSilent Mode:
spideyx paramfuzzer -site https://example.com -w params.txt --silentThe --http-raw flag allows you to pass a complete raw HTTP request for parameter fuzzing. This feature is useful for scenarios where you need precise control over the entire HTTP request, including custom headers and bodies. SpideyX will replace the placeholder $pideyx in your raw request with parameters from your wordlist during the fuzzing process.
Usage:
- Enclose the raw HTTP request in single quotes (
') to treat it as a single argument. - Use the placeholder
$pideyxto indicate where parameters should be inserted in the request body.
Examples:
-
JSON Body:
spideyx paramfuzzer --http-raw 'POST https://target.com/api/login Content-Type: application/json Content-Length: $length {"username":"admin", $pideyx}' -w params.txt
- This example sends a JSON payload where
$pideyxis replaced with each parameter from the wordlist.
- This example sends a JSON payload where
-
XML Body:
spideyx paramfuzzer --http-raw 'POST https://target.com/api/update Content-Type: application/xml Content-Length: $length <user><username>admin</username>$pideyx' -w params.txt
- In this example, the XML body contains the
$pideyxplaceholder for fuzzing password parameters.
- In this example, the XML body contains the
-
HTML Form Body:
spideyx paramfuzzer --http-raw 'POST https://target.com/submit-form Content-Type: application/x-www-form-urlencoded Content-Length: $length username=admin&$pideyx' -w params.txt
- This example demonstrates fuzzing HTML form parameters, where
$pideyxis used in thepasswordfield.
- This example demonstrates fuzzing HTML form parameters, where
- Ensure the placeholder
$pideyxis correctly placed in the body where you want parameters to be injected. - The
--http-rawflag takes precedence over other body-related flags such as-bodyand-fmt. If you use--http-raw, these flags will be ignored. - The request body should be formatted correctly for JSON, XML, or HTML form submissions to ensure proper fuzzing and accurate results.
SpideyX Jsscrapy mode is designed for in-depth analysis and scraping of JavaScript files to uncover hidden endpoints and secrets. It parses JavaScript files from specified URLs or lists, utilizing user-defined regex patterns to search for and extract valuable information. This mode is particularly useful for discovering hidden functionalities and assets within web applications by analyzing their JavaScript code.
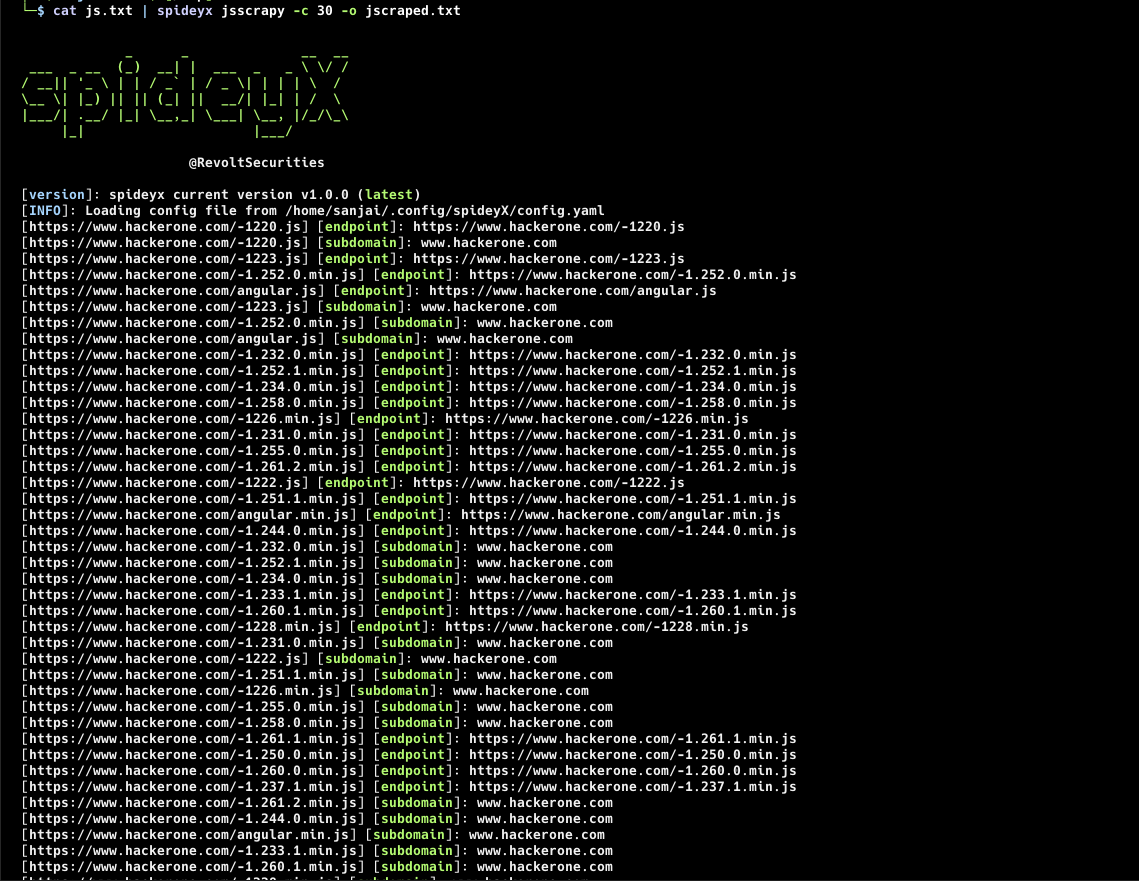
-
JavaScript File Parsing: Efficiently parses and scrapes JavaScript files to uncover hidden endpoints and secrets.
-
Custom Regex Support: Utilizes user-defined regex patterns from a YAML configuration file to target specific data or patterns within JavaScript files.
-
Cloud Service Discovery: Includes built-in regex patterns for discovering endpoints related to popular cloud services such as AWS S3, Google Cloud Storage, and Azure Blob Storage.
-
Concurrent Crawling: Supports concurrent crawling to accelerate the discovery process, with configurable concurrency levels to balance load and performance.
-
Custom Header Support: Allows for authenticated scraping by including custom headers and cookies, enabling access to protected or restricted resources.
-
Configurable Timeout and Proxies: Offers options to set request timeouts and use proxies for enhanced control and anonymity during scraping.
JavaScript URL Input:
-
Single URL:
spideyx jsscrapy --site https://example.com/add/hello.js
-
Multiple URLs:
spideyx jsscrapy --sites https://example.com/add/hello.js,https://example.com/script.js
-
Stdin Input:
cat urls.txt | spideyx jsscrapy
Authenticated JavaScript Scraping:
Use the -H or --header flag to include custom headers or cookies for authenticated JavaScript scraping.
spideyx jsscrapy --site https://target.com/add/hello.js -H 'Authorization: Bearer <token>' -H 'X-Custom-Header: value'Default Configuration:
SpideyX Jsscrapy mode uses the configuration file located at ~/.config/spideyx/config.yaml to define regex patterns for scraping JavaScript files.
Example YAML Configuration:
JsRegex:
- regex:
- (?i)[a-zA-Z0-9-]+\.
type: subdomain
- regex:
- (?i)(?:https?://)?[\w\-]+\.cloudfront\.net
- (?i)(?:https?://)?[\w\-]+\.appspot\.com
- (?i)(?:https?://)?s3[\w\-]*\.amazonaws\.com/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.s3[\w\-]*\.amazonaws\.com/?
- (?i)(?:https?://)?[\w\-]+\.digitaloceanspaces\.com/?[\w\-]*
- (?i)(?:https?://)?storage\.cloud\.google\.com/[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.storage\.googleapis\.com/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.storage-download\.googleapis\.com/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.content-storage-upload\.googleapis\.com/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.content-storage-download\.googleapis\.com/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.1drv\.com/?[\w\-]*
- (?i)(?:https?://)?onedrive\.live\.com/[\w\.\-]+
- (?i)(?:https?://)?[\w\-]+\.blob\.core\.windows\.net/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.rackcdn\.com/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.objects\.cdn\.dream\.io/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.objects-us-west-1\.dream\.io/?[\w\-]*
- (?i)(?:https?://)?[\w\-]+\.firebaseio\.com
type: cloud-services
- regex:
- (https?:\/\/[^\s"'>]+)
- (?i)(https?:\/\/[^\s"'>]+)
- (?i)(?<![a-zA-Z0-9\/s])[\/][\w\-]+(?:/[\w\-./?&%#=]*)?
type: endpointCustom Regex Definitions:
Users can define their own regex patterns and types in the YAML file:
JsRegex:
- regex:
- regex1
- regex2
type: myregex
- regex:
- regex1
- regex2
type: MysecretRegexregex: List of regex patterns to apply.type: Custom type for categorizing the regex.
Usage with Custom YAML Configuration:
Specify a custom YAML configuration file using the -cp flag:
spideyx jsscrapy --site https://example.com/add/hello.js -cp /path/to/custom-config.yamlControl the number of concurrent requests and the delay between requests to manage load.
Concurrency Example:
spideyx jsscrapy --site https://example.com/add/hello.js --concurrency 10Delay Example:
spideyx jsscrapy --site https://example.com/add/hello.js --delay 0.5Store the results of the JavaScript scraping session in a file using the -o or --output flag.
Example:
spideyx jsscrapy --site https://example.com/add/hello.js --output results.txtIncrease verbosity with the --verbose flag for detailed output, or use the --silent flag to suppress unnecessary information.
Verbose Example:
spideyx jsscrapy --site https://example.com/add/hello.js --verboseSilent Mode:
spideyx jsscrapy --site https://example.com/add/hello.js --silentSpideyX is a robust and secure tool designed with the highest standards of safety in mind. It is crafted to ensure that it does not pose any threats to users or security researchers. SpideyX operates transparently, respecting user permissions and will not update itself without explicit consent. We encourage the community to contribute to SpideyX by reporting issues and suggesting improvements. Your feedback is invaluable in helping us maintain and enhance the tool’s security and functionality.
SpideyX is developed by the dedicated team at RevoltSecurities with ❤️. We are committed to continuous improvement and appreciate the support from our users. Community contributions are always welcome and play a vital role in the evolution of SpideyX. If you find SpideyX valuable, please show your support by giving it a ⭐ and engaging with our community to help make SpideyX even better.