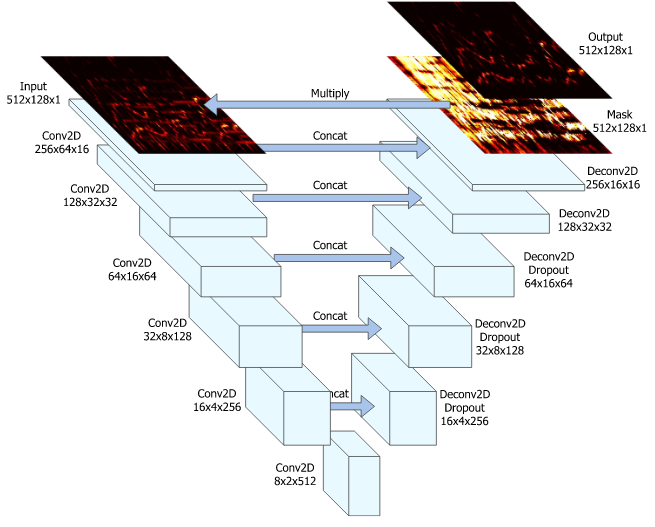
In this repository, we try to use U-Net to deal with the singing voice separation problem. The name of original paper is Singing Voice Separation with Deep U-net Convolutional Networks. Since there is no other PyTorch implementation of this paper, we try to re-write with PyTorch. Specially, we use MUSDB18 as the training dataset. We also prepare the pre-trained data that you can demix the singing voice for any song ON THE FLY!!
We prepare the pre-trained model here [door]. For the pre-trained model, we train for around 80000 epoch. First, download the model and place into the current folder. Next, since the model can only deal with spectrogram, you should convert the song step-by-step:
- Convert the whole song as spectrogram for the specific folder:
python3 data.py --src <SONG_FOLDER> --tar test_data
- Seperate the song by the pre-trained model:
python3 inference.py --mixture_folder test_data/mixture --tar test_magnitude --model_path svs_unet.pth
- Merge the phase and transform back into time domain. You should notice that the phase should be assigned since STFT will use the phase to reconstruct the wave. The
mixturefolder should be pointed to get the phase you want to recover.
python3 data.py --src test_magnitude --phase test_data/mixture/ --tar <RECON_FOLDER> --direction to_wave
- Go to
RECON_FOLDERand listen the splited result.
You can also train the model from scratch or fine-tune the model. Same as the testing procedure, you should convert as spectrogram first. Here is the steps:
- Convert the whole training song as spectrogram:
python3 data.py --src <SONG_FOLDER> --tar train_data
- Train for 1000 epoch!
python3 train.py --train_folder train_data/ --load_path svn_unet.pth --save_path svn_unet_tune.pth --epoch 1000
- Now you can get the fine-tune model
svn_unet_tune.pth.
Since the markdown cannot put the audio, we place the result in the folder. The song we choose is A Little Happiness which is performed by Hebe Tien. Rather than the English song, A Little Happiness is a Chinese song and it's not in the training set of MusDB18. The result demonstrates that the vocal intensity decrease in some level. But the separation performance is not good enough.