Scene-to-Image Prompt Layering System #1179
Conversation
…ing Sygil-Dev#947. Also fixes bug in image display when using masked image restoration with RealESRGAN. When the image is upscaled using RealESRGAN the image restoration can not use the original image because it has wrong resolution. In this case the image restoration will restore the non-regenerated parts of the image with an RealESRGAN upscaled version of the original input image. Modifications from GFPGAN or color correction in (un)masked parts are also restored to the original image by mask blending.
Scene is going to be described by a prompt scene description language. Prompts and image generation parameters can be specified in code. Scene is based on image layers that are blended to a final image. Layers can be recursive. Layer content can be generated from txt2img prompts, or other user content. Layer blending can be common blending methods (like additive, multiplicative, etc.) and (optionally) together with img2img. Other user content could be retrieved from urls or we could provide a few code accessible gradio image slots where use can upload and manipulate images.
# Conflicts: # scripts/webui.py
this allows deep trees while avoiding growing number of '#' by just using '#> example title' headings. sections after this will have their depth bumped by number matched '>'.
… size it uses default size from img2img_defaults
now allows the common pattern where you can toggle which of two sections should be out-commented. Example "Section A" is active, "Section B" is in comment: //* Section A /*/ Section B //*/ Example "Section B" is active, "Section A" is in comment: /* Section A /*/ Section B //*/
cache is stored in ram not in vram. it will get automatically cleared when generating with different seed in frontend.
this allows automatically mask objects, foreground or background in generated images. depth image is estimated from images using monocular-depth-estimation: https://huggingface.co/keras-io/monocular-depth-estimation https://huggingface.co/spaces/atsantiago/Monocular_Depth_Filter
headings in format "#< title" will reduce following section depth by number of "<" useful to get out of high depth bump due to usage of "#> title". bug fix in scn2img function argument definitions
- fix missing intermediates output - variation=0 will not modify seed - improved caching by using hash function with explicit contents instead of relying on str(obj) as hash - move function kwarg preparation out of render functions into seperate functions
`None` attribute key is excluded from hash because it only contains free text (like newlines) of the corresponding scn2img-prompt section
seed generators can be initialized with "initial_seed" and will be used for this section and its children. they can recursively used, i.e. children can do the same and the seed generator will only apply to them and their children. the first seed generator is initialized with the seed argument supplied to scn2img function. this makes it possible to save initial seeds in scn2img-prompt and reuse prompts with (nearly) deterministic results.
… mask value mask generation will now also work directly on txt2img and img2img output (previously only in image sections). new options in sections: - mask_invert - mask_value - mask_by_color # reference color as RGB tuple. sets mask to 0 where image color is too different - mask_by_color_space # specifies in which colorspace to use for selection (defaults to LAB) - mask_by_color_threshold # threshold to use for color selection (defaults to 15)
…morphological operations new arguments: - mask_by_color_at - mask_open - mask_close - mask_grow - mask_shrink - mask_blur
tensorflow is for depth from image estimation, used for automatic mask selection in scn2img. tensorflow needs einops>=0.3.0 otherwise, "AttributeError: module 'keras.backend' has no attribute 'is_tensor'" is thrown when loading keras model.
now uses the same code for parameter copy as txt2img and scn2img.
scn2img needs some functions,variables,etc. from webui.py. to avoid circular import, the scn2img function is wrapped with get_scn2img. it takes the necessary variables as arguments and returns a usable scn2img function. monocular depth estimation model loading is now delayed until it is actually used by used scn2img.
Gives better results for depth most of the time, so it is used by default. adds new dependency "timm" of (Unofficial) PyTorch Image Models, which is used by MiDaS add new scn2img arguments: - mask_depth_normalize: bool // normalizes depth between 0 and 1 (by default on) - mask_is_depth : bool // directly use the depth as mask, rescaling depth at mask_depth_min to mask=0 and mask_depth_max to mask=255 - mask_depth_model: int // 0=monocular depth estimation, 1=MiDaS (default)
image depth is estimated, which gives the distance of each image pixel in 3d space. the transformed image is taken from another camera position and orientation. new scn2img arguments to transform output of image, txt2img and img2img: Enable it with - transform3d : bool Only draw pixels where mask is in these bounds: - transform3d_min_mask: int - transform3d_max_mask: int Select depth estimation model and scale - transform3d_depth_model: int // 0 = monocular depth estimation, 1 = MiDaS depth estimation (default) - transform3d_depth_scale: float // camera position must reflect this scale Camera parameters of from where input image was taken - transform3d_from_hfov: float // horizontal field of view in degree, default 45 - transform3d_from_pose: int_tuple // x,y,z,rotatex,rotatey,rotatez in degree; default 0,0,0 , 0,0,0 Camera parameters to where we want to transform the image - transform3d_to_hfov: float - transform3d_to_pose: tuple Invert mask of unknown pixels due to 3d transformation - transform3d_mask_invert: bool // default is False Enable inpainting with cv2.inpaint, by default it is enabled. - transform3d_inpaint: bool - transform3d_inpaint_radius: int - transform3d_inpaint_method: int // 0=cv2.INPAINT_TELEA, 1=cv2.INPAINT_NS - transform3d_inpaint_restore_mask: bool // restore mask of unknown pixels due to transformation after inpainting
# Conflicts: # environment.yaml
new scn2img argument: `blend` `blend` is one of alpha, mask, add, add_modulo, darker, difference, lighter, logical_and, logical_or, logical_xor, multiply, soft_light, hard_light, overlay, screen, subtract, subtract_modulo alpha & mask are both the default alpha compositing the other ones are blend operations from PIL.ImageChops
|
@codedealer I added output info and batch view progress. @hlky I moved the code, pinned the dependency versions and reverted changes to not scn2img-related code (save_sample). For the remaining changes, i.e. the added default values for img2img and txt2img, I think my #1179 (comment) explains the reasoning. @Dekker3D Images can now be blended in other modes (full list) like |

add new scn2img argument: - transform3d_depth_near: float // specifies how near the closest pixel is, i.e. the distance corresponding to depth=0 without this pixels with very low depth previously where strongly distorted after transformation.
There was a problem hiding this comment.
Couple points:
- @hlky this currently pulls pickles from github for MiDaS into pytorch's cache. Should we pack them inside repo instead?
- @xaedes During intermediate renders you call webui's save_sample with
skip_metadataset toFalsehardcoded. In your example with the waterfall scene when saving empty masks this results in a warning thrown in console:
Couldn't find metadata on image
It's not critical but can we do something about it?
* added front matter * fixed links * logo is removed until further consideration
|
Note the approved files. I haven't tested this yet, but I have resolved the conflicts in @codedealer @xaedes what is the status of this? |
|
@hlky Tested it and it does work with the updated environments.yaml. requirements.txt also looks good, but at my machine I can't test if it works with Docker. @codedealer I will do something about the image metadata. |
Following metadata is written: - "prompt" contains the representation of the SceneObject corresponding to the intermediate image - "seed" contains the seed at the start of the function that generated this intermediate image - "width" and "height" contain the size of the image. To get the seed at the start of the render function without using it, a class SeedGenerator is added and used instead of the python generator functions. Fixes warning thrown in console: "> Couldn't find metadata on image", originally reported by @codedealer in Sygil-Dev#1179 (review)
Following metadata is written: - "prompt" contains the representation of the SceneObject corresponding to the intermediate image - "seed" contains the seed at the start of the function that generated this intermediate image - "width" and "height" contain the size of the image. To get the seed at the start of the render function without using it, a class SeedGenerator is added and used instead of the python generator functions. Fixes warning thrown in console: "> Couldn't find metadata on image", originally reported by @codedealer in Sygil-Dev#1179 (review)
Following metadata is written: - "prompt" contains the representation of the SceneObject corresponding to the intermediate image - "seed" contains the seed at the start of the function that generated this intermediate image - "width" and "height" contain the size of the image. To get the seed at the start of the render function without using it, a class SeedGenerator is added and used instead of the python generator functions. Fixes warning thrown in console: "> Couldn't find metadata on image", originally reported by @codedealer in Sygil-Dev#1179 (review)
Following metadata is written: - "prompt" contains the representation of the SceneObject corresponding to the intermediate image - "seed" contains the seed at the start of the function that generated this intermediate image - "width" and "height" contain the size of the image. To get the seed at the start of the render function without using it, a class SeedGenerator is added and used instead of the python generator functions. Fixes warning thrown in console: "> Couldn't find metadata on image", originally reported by @codedealer in Sygil-Dev#1179 (review)
# Description Intermediate image saving in scn2img tries to save metadata which is not set. This results in warning thrown in console: "Couldn't find metadata on image", originally reported by @codedealer in #1179 (review) Metadata for intermediate images is added to fix the warning. Following metadata is written: - "prompt" contains the representation of the SceneObject corresponding to the intermediate image - "seed" contains the seed at the start of the function that generated this intermediate image - "width" and "height" contain the size of the image. To get the seed at the start of the render function without using it, a class SeedGenerator is added and used instead of the python generator functions. Fixes warning thrown in console: "> Couldn't find metadata on image", originally reported by @codedealer in #1179 (review) # Checklist: - [x] I have changed the base branch to `dev` - [x] I have performed a self-review of my own code - [x] I have commented my code in hard-to-understand areas - [x] I have made corresponding changes to the documentation
Summary of the change
Description
(relevant motivation, which issue is fixed)
Related to discussion #925
To make this work I made a prompt-based layering system in a new "Scene-to-Image" tab.
You write a a multi-line prompt that looks like markdown, where each section declares one layer.
It is hierarchical, so each layer can have their own child layers.
Examples: https://imgur.com/a/eUxd5qn
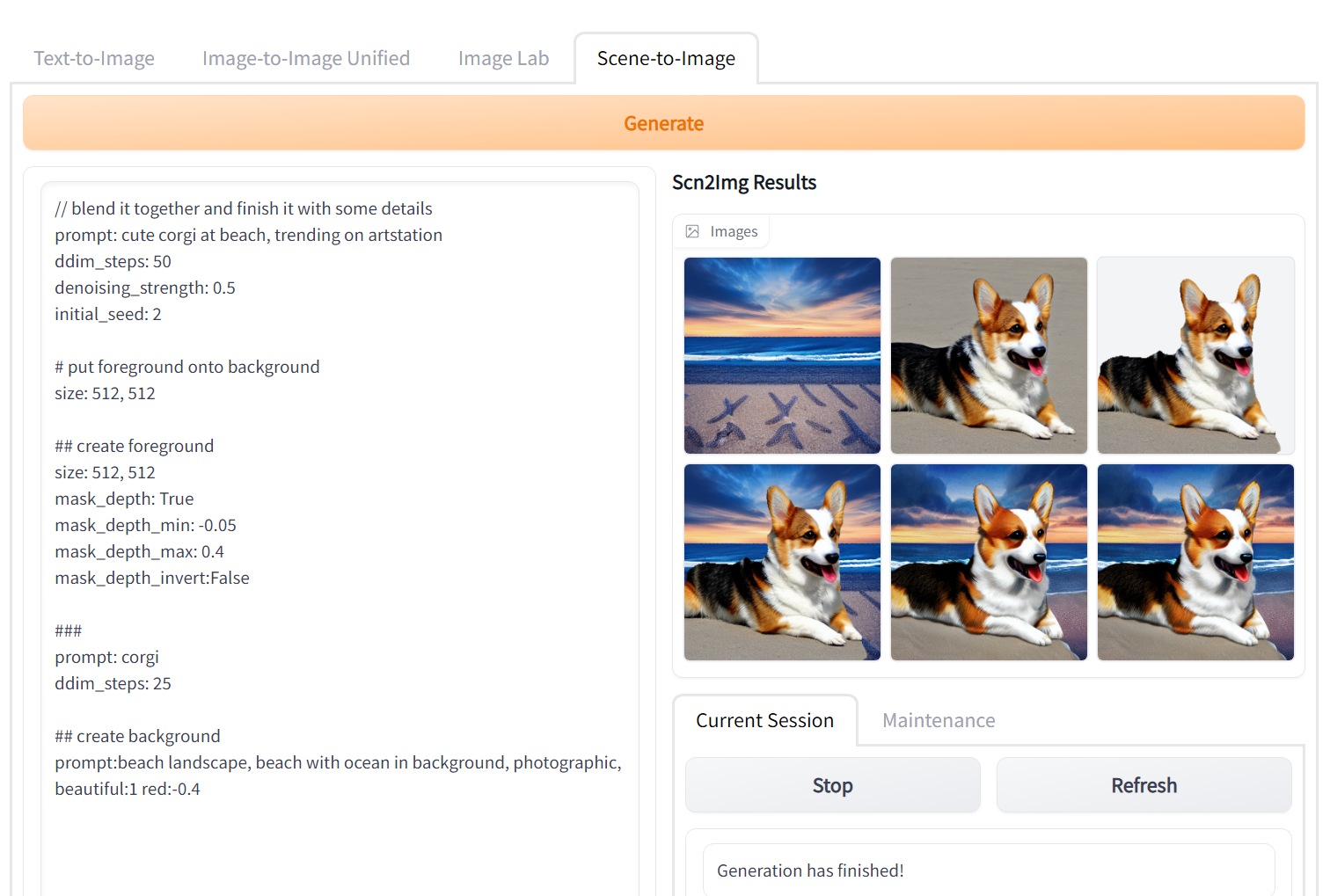
In the frontend you can find a brief documentation for the syntax, examples and reference for the various arguments.
Here a short summary:
Sections with "prompt" and child layers are img2img, without child layers they are txt2img.
Without "prompt" they are just images, useful for mask selection, image composition, etc.
Images can be initialized with "color", resized with "resize" and their position specified with "pos".
Rotation and rotation center are "rotation" and "center".
Mask can automatically be selected by color or by estimated depth based on https://huggingface.co/spaces/atsantiago/Monocular_Depth_Filter.
Additional dependencies that are required for this change
For mask selection by monocular depth estimation tensorflow is required and the model must be cloned to ./src/monocular_depth_estimation/
Changes in environment.yaml:
Einops must be allowed to be newer for tensorflow to work.
Checklist:
dev