Our Team:
팀명: TripleH (Kim Hyeon Jin, Lee Ha Gyeong, Hyun Ohjoo)
팀구성:
- 이하경(이화여대 컴퓨터공학과)
- 김현진(이화여대 컴퓨터공학과)
- 현오주(이화여대 컴퓨터공학과)
Idea:

Target Group:
한식을 맛보고 싶으나 한국어에 서투르고 한식에 대해 잘 알지 못하는 외국인 관광객
외국인 손님과의 소통이 어려운 한식 식당 점주들
Needs:

비건, 알레르기 등의 음식 제한은 외국인들이 한국의 여행을 즐기지 못하는 이유이다.
PoC:
메뉴판 사진 촬영을 통한 이미지 검색
- 메뉴판 사진에서 글자를 인식하는 AI 모델을 사용
- 한국어 인식 후 번역 API를 통한 영어 번역한 결과를 overlay하여 제공
음식 재료 / 비건 여부, 알레르기 유발 여부 정보 제공
- 만개의 레시피 등의 사이트의 레시피 크롤링과 레시피 API을 통해 음식 정보 수집
- 음식 별 재료 분석을 통하여 특정 재료가 그 음식에 들어갈 확률, 비건 여부, 알레르기 유발 여부 정보 제공
리뷰 분석 → 외국인의 한식 맛 표현에 대한 키워드 3개 뽑아서 보여줌
- 외국인이 작성한 리뷰 분석을 통해 특정 음식의 특징을 그들의 입맛 반영하여 키워드로 제공
- 초기 데이터 부족으로 Yelp의 리뷰 데이터 분석을 통해 키워드 추출, 이후 사용자 리뷰 데이터 분석을 접목할 예정

클릭하면 Youtube 영상으로 이동 :)

개발 환경 및 version Control :
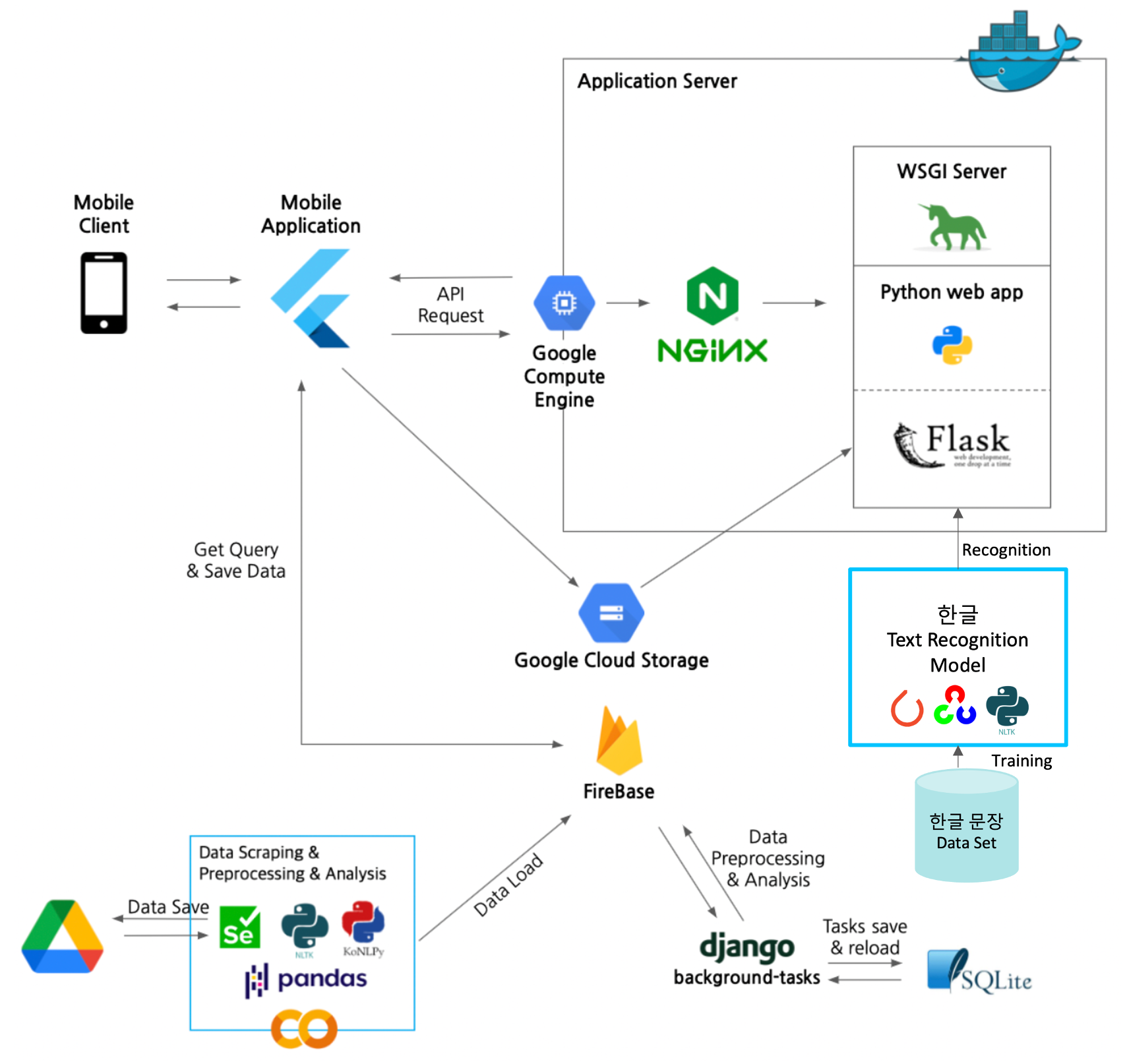
화면 Flow :

-
Figma로 와이어프레임을 구성
-
Material Components(Android)와 Cupertino Components(iOS)로 애플리케이션의 구성요소 설정
-
Class와 Widget 기능 설명
-
Firebase 연동으로 정보 추출
-
각 음식이 들어갈 확률을 차트로 표시
-
Flutter 에서 리뷰 작성 시 Firebase로 전송 후, 플러터에서 바로 확인 가능
결과 화면





-
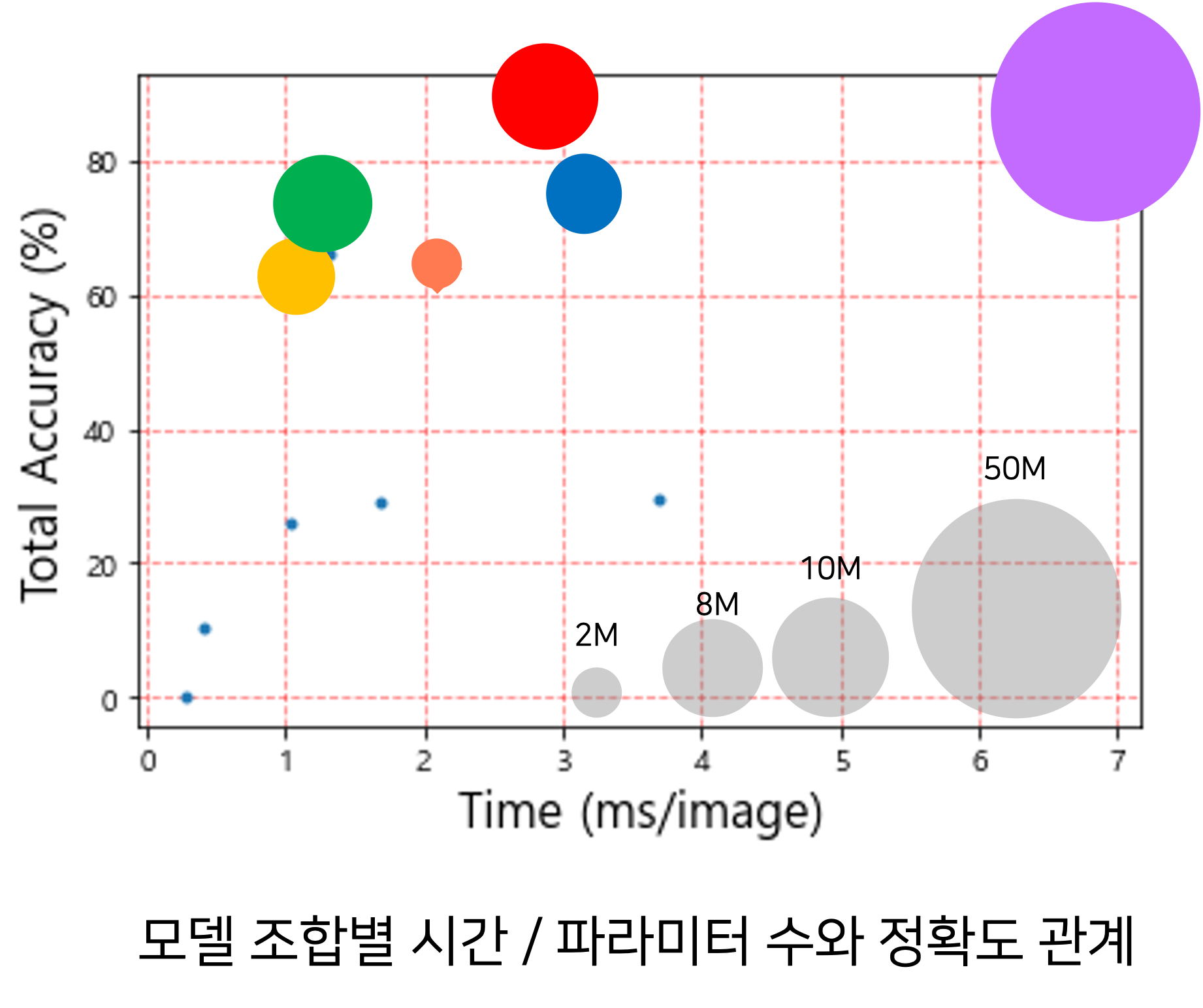
가장 높은 정확도를 보인 모델 조합은 TPS-VGG-BiLSTM-Attention이다.
-
변환(Transformer) 모듈에서 TPS를 사용할 때 정확도가 최대 34%까지 향상되는 결과를 보였다.
-
추출(Feature Extraction) 모듈에서 VGG와 ResNet을 사용하였을 때의 결과가 RCNN을 사용했을 때보다 높은 정확도를 보였고 모델 간 평균 파라미터 수를 비교했을 때는 ResNet,VGG, RCNN 순의 결과를 보였다.
-
시퀀스(Sequence) – 예측(Prediction) 모듈에서 BiLSTM-Attention 조합이 BiLSTM을 사용하지 않을 때보다 정확도가 높은 결과를 보였다. -> BiLSTM-Attention 조합이 함께 사용했을 때 정확도를 향상시키는 효과
- 재료 데이터 수집
- '식품의약품안전처'에서 '조리식품의 레시피' API 이용하여 데이터 수집
- '만개의 레시피'에서 Selenium과 BeautifulSoup을 이용하여 크롤링을 통해 데이터 수집
-
데이터 전처리
-
재료 정보에 단위, 수량, 숫자 등 필요없는 부분 제거
-
nltk와 KoNLPy를 사용하여 재료 정보를 한 단어씩 tokenizing 하여 명사만 추출
-
이후 제거되지 않은 불용어 사전 제작 후, 불용어 제거

- 재료명 일반화 및 단어 통일
- 중복 제거: 한 메뉴에 중복되는 재료가 있는 경우 중복제거

- 전처리 된 최종 데이터

-
-
재료의 비건/알레르기 여부 데이터 생성
- 위의 Food_Ingredient 데이터 내의 모든 재료 추출 → 총 280개의 재료 사용

- 재료 리스트를 기반으로 비건/알레르기 사전 제작
- 서칭을 통해서 정보 획득 후, boolean 값으로 사전 제작
-
최종 데이터 파이어베이스에 업로드
[food raw data]

[food ingredient raw data]

- 이후 목표
- 현재 한국관광공사X카카오 관광 API 공모전에 선발되어 Tmap 네비게이션 데이터를 활용할 수 있음
- 이 데이터는 지역별 식음료 검색 순위 top100에 대한 정보도 포함하여, 이를 기준으로 검색을 용이하게 만들 예정
- 크롤링한 데이터를 더 활용하여, 정확한 비율을 제공할 예정
-
크롤링한 데이터가 너무 방대하고 음식 데이터와 재료 데이터가 따로 저장되어있는 문제 발생
-
장고를 이용하여 파이어 베이스의 데이터를 로드하고, 음식에 들어 있는 재료 별로 비건 여부, 알레르기 여부 등을 재료 데이터에서 찾아 합쳐줌
-
번역 - 음식 재료와 음식 명을 번역해 주었음
- Kakao i 번역 api 사용 → 인증 과정에서 계속 오류 발생
- Papago 번역 api 로 해결
-
데이터가 방대하다 보니 Too many request, time out 등의 에러가 발생
- Django의 Background-tasks Library를 사용하여 리퀘스트 작업을 백그라운드로 끊어서 보내줌
- SQLite를 이용하여 Background-tasks 저장, 주기적으로 리로드
-
결과 화면
