This project is a demonstration of how to use Apache Cassandra for building a shopping cart application. The README provides an overview of Apache Cassandra, a comparison with relational databases, an explanation of data modeling in Cassandra, and a description of the project's data model and query-driven approach.
- Introduction about Apache Cassandra
- Partitions
- Replication ensures reliability and fault tolerance
- Apache Cassandra vs Relational Database
- Cassandra Data Types
- Cassandra User Defined Type
- Data Modeling
- Query-driven modeling
- Project Model
- How the service will work?
- Containers With Cassandra
- Cassandra Multi DC Cluster
- Introducing Cassandra on Kubernetes
- Guides that can help you
- Conclusions
- References
Apache Cassandra is a NoSQL distributed database. By design, NoSQL databases are lightweight, open-source, non-relational, and largely distributed. Counted among their strengths are horizontal scalability, distributed architectures, and a flexible approach to schema definition [1].
- Cassandra was developed from the flaws of system/hardware that can and does occur.
- Distributed Peer-To-Peer system.
- All nodes are the same.
- Data is partitioned across nodes in the cluster.
- Custom replication to ensure the fault tolerance.
- Read/Write Anywhere between data centers.
All nodes participate in a masterless cluster, meaning there is no primary node. A commit log ensures data durability by monitoring write activities. The data is also written to a memory structure and only flushed to disk when the memory becomes full. Need more capacity? Add a server. Want higher throughput? Add a server [2].
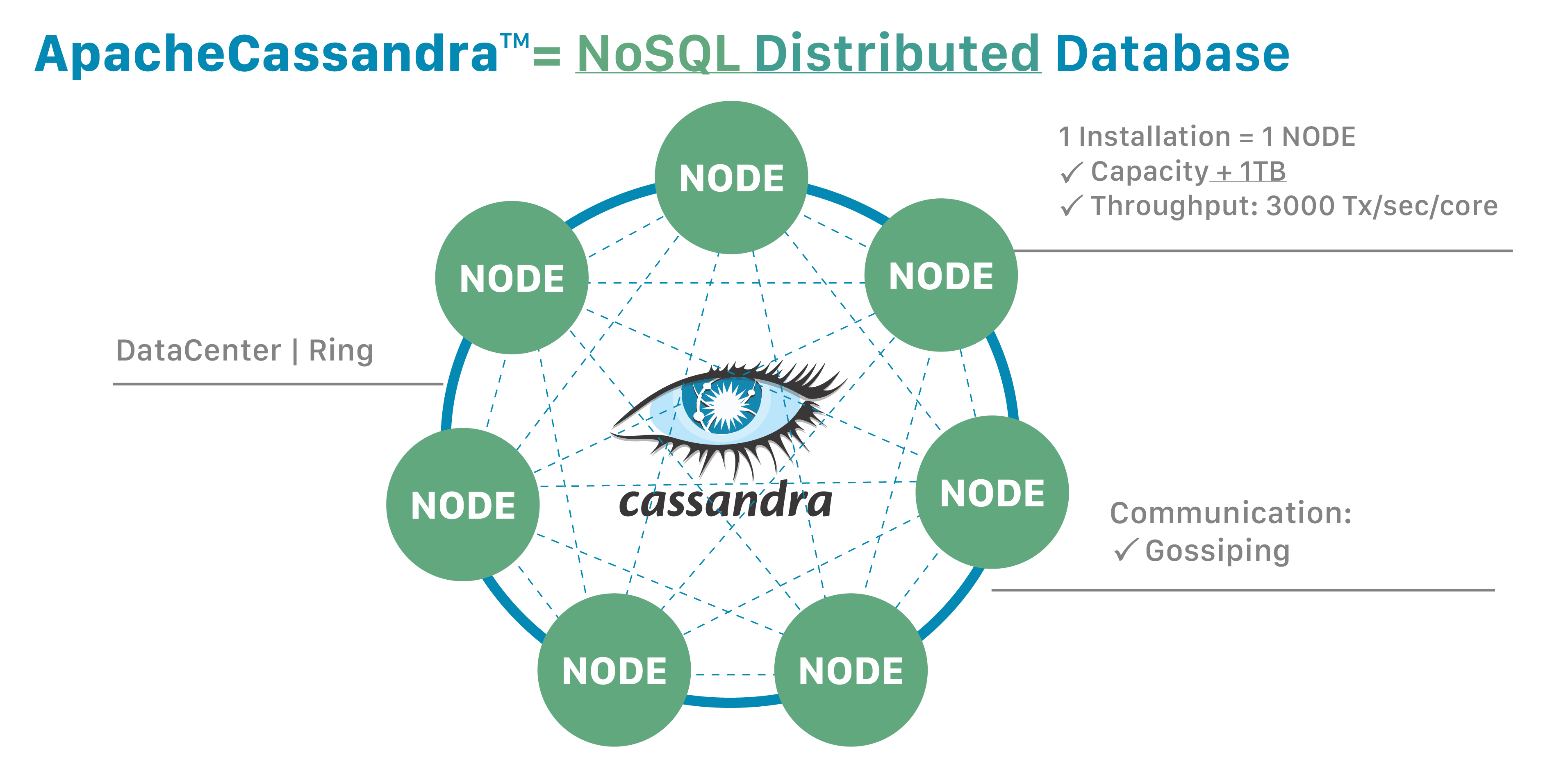 Figure 1: Distribution provides power and resilience.
Figure 1: Distribution provides power and resilience.
The partition-key plays a crucial role in determining the placement of data on the ring, significantly impacting query efficiency. During the data insertion process, a consistent hashing algorithm partitions the data and assigns a hash number to the partition-key, ensuring accurate placement on the ring.
To optimize for a specific location, such as grouping data by state, our application needs to be designed accordingly. By making the state field the logical grouping for the data, we can leverage this characteristic to improve ring efficiency.

Figure 2: Partitions.
In scenarios with multiple partitions based on state, we must ensure that the primary key includes the state field. When defining the primary key as state, we establish two things: the uniqueness of the record and its partitioning based on the state. However, relying solely on the state as the primary key would lead to inefficient record overwrites. To avoid this, we include another element in the primary key, such as an ID, to maintain uniqueness in real-life scenarios.
CREATE TABLE address_by_id (
add_id UUID,
add_street TEXT,
add_number INT,
add_zip_code TEXT,
add_state TEXT,
add_country TEXT,
PRIMARY KEY ((add_state), add_id) # --> state as the partition key and the id as a part of the primary key
)The partition-key remains crucial for determining the placement of data on the ring. It allows us to accurately locate data within the ring structure. This feature is particularly fascinating in Cassandra because it enables us to predict the destination of data when inserted into the ring. For instance, if we insert data for Texas into a 1000-node ring, we know precisely where it will reside. This characteristic simplifies data querying, as the consistent hashing algorithm ensures that queried data remains in the same location, eliminating the need for extensive searching.
The process is highly efficient, utilizing a constant-time, order-one algorithm. When we search for data related to Texas, we can quickly locate it within the 1000-node ring.
One piece of data can be replicated to multiple (replica) nodes, ensuring reliability and fault tolerance. Cassandra supports the notion of a replication factor (RF), which describes how many copies of your data should exist in the database. So far, our data has only been replicated to one replica (RF = 1). If we up this to a replication factor of two (RF = 2), the data needs to be stored on a second replica as well – and hence each node becomes responsible for a secondary range of tokens, in addition to its primary range. A replication factor of three ensures that there are three nodes (replicas) covering that particular token range, and the data is stored on yet another one [3].
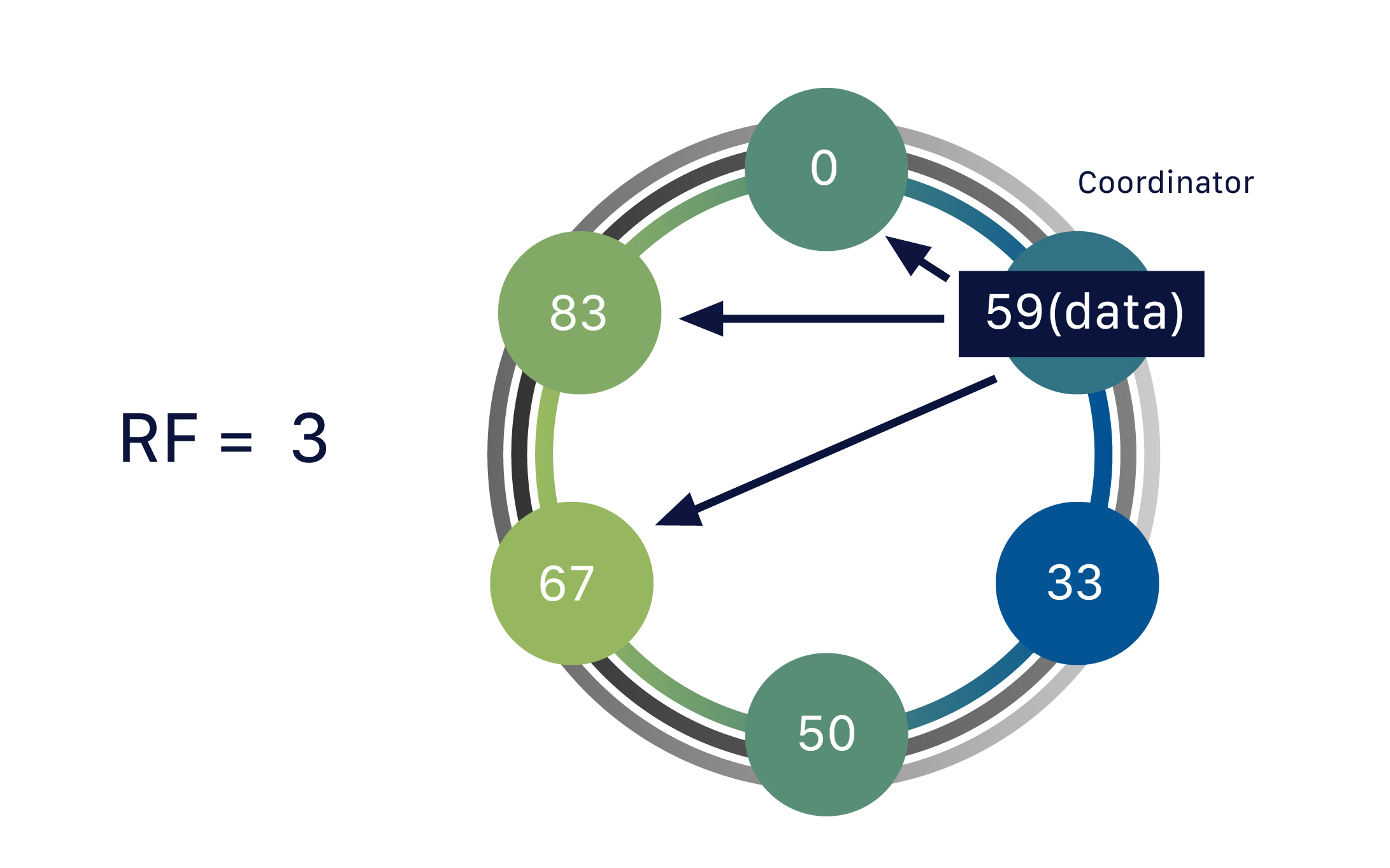 Figure 3: Reliability and fault tolerance.
Figure 3: Reliability and fault tolerance.
There are two basic strategies for data partitioning:
- Random partitioning - the default and recommended strategy. The data is partitioned as evenly as possible across the nodes using a HASH code for each row.
- Ordered partitioning - stores the rows in an ordered manner (pre-defined). In the cassandra.yaml configuration file, it is possible to change the modes in the partitioner option.
Apache Cassandra and relational databases are database management systems with different approaches. Here are some key differences between Apache Cassandra and a relational database:
-
Data Model:
- Relational Database: Relational databases follow a structured, table-based data model where data is organized into rows and columns. Tables are defined by fixed schemas, and relationships between tables are established through foreign keys.
- Apache Cassandra: Cassandra adopts a denormalized, column-based data model. Data is stored in column families, where each row can have a variable number of columns. This allows for greater flexibility in data modeling, especially in large-scale scenarios with high availability requirements.
-
Scalability:
- Relational Database: Relational databases are typically scaled vertically, which means adding more resources (CPU, memory) to a single server to handle increased workload. This approach may have practical limitations in terms of scalability.
- Apache Cassandra: Cassandra was designed for horizontal scalability, allowing the addition of more nodes to the cluster to handle increased workload. It efficiently distributes data across multiple nodes, providing high availability and linearly scalable performance.
-
Consistency and Availability:
- Relational Database: Relational databases typically follow the ACID (Atomicity, Consistency, Isolation, Durability) model to ensure data consistency. This means that in concurrent transactions, consistency is maintained, but there may be a trade-off in availability.
- Apache Cassandra: Cassandra follows an eventual consistency model, where availability and performance are prioritized over immediate consistency. This enables fast read and write operations even in distributed environments but may result in a period where data is eventually consistent.
-
Geographic Flexibility:
- Relational Database: Relational databases often have limitations regarding the geographic distribution of data. Data is stored on a single server or replicas within a specific geographic region.
- Apache Cassandra: Cassandra allows data replication across multiple geographically distributed data centers, offering high availability and fault tolerance across different regions. This is particularly useful in applications with global replication needs or serving users in different parts of the world.
These are just a few of the differences between Apache Cassandra and a relational database. The choice between the two depends on specific project requirements, such as scalability, data modeling flexibility, and consistency and availability needs [4].
CQL (Cassandra Query Language) is a typed language and supports a rich set of data types, including native types, collection types, user-defined types, tuple types, and custom types, there are some examples regarding native types [5]:
| Data Type | Description |
|---|---|
| ASCII | Sequence of ASCII characters |
| BIGINT | 64-bit long integer |
| BOOLEAN | Boolean value (true or false) |
| DATE | Date without time or time zone |
| DOUBLE | 64-bit floating-point number |
| FLOAT | 32-bit floating-point number |
| INET | IPv4 or IPv6 address |
| INT | 32-bit integer |
| TEXT | UTF-8 encoded character string |
| TIME | Time value |
| TIMESTAMP | Date and time stamp |
| UUID | Universally unique identifier |
| VARINT | Arbitrary-precision integer |
| TIMEUUID | Universally unique identifier with time |
Figure 3: Cassandra native types.
In Cassandra, in addition to primitive data types, it is possible to create User Defined Types (UDTs) to model more complex data structures. UDTs allow grouping related fields into a single entity. Here is an explanation of User Defined Types in Cassandra: Definition User Defined Types are created by the user to define a custom data structure. A UDT consists of a set of fields, where each field has a name and an associated data type. UDTs are created at the keyspace level and can be used as data types in table columns [6].
Let's consider the scenario that we will develop during the project, we have three UDTs:
 Figure 4: User Defined Types.
Figure 4: User Defined Types.
CQL support the definition of user-defined types (UDTs). Such a type can be created, modified and removed using the create_type_statement, alter_type_statement and drop_type_statement described below. But once created, a UDT is simply referred to by its name, let’s create and use a UDT:
Using CQL to define UDTs:
CREATE TYPE address_type (
id UUID,
street TEXT,
addressNumber INT,
zipCode TEXT,
country TEXT
);Using Java to define UDTs:
@UserDefinedType("address_type")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class AddressType {
@CassandraType(type = Name.UUID)
private UUID id;
@CassandraType(type = Name.TEXT)
private String street;
@CassandraType(type = Name.DOUBLE)
private Integer addressNumber;
@CassandraType(type = Name.TEXT)
private String zipCode;
@CassandraType(type = Name.TEXT)
private String country;
}Apache Cassandra stores data in tables, with each table consisting of rows and columns. CQL (Cassandra Query Language) is used to query the data stored in tables. Apache Cassandra data model is based around and optimized for querying. Cassandra does not support relational data modeling intended for relational databases.
Data replication is a key aspect of Cassandra's data model. Replication ensures that copies of data are stored on multiple nodes to provide fault tolerance and high availability. Cassandra uses a distributed consensus protocol called the gossip protocol to ensure that data remains consistent across replicas.
By working without rigid relationships and relying on data replication, Cassandra offers exceptional scalability, fault tolerance, and the ability to handle massive amounts of data. This data model is particularly well-suited for use cases where high availability, read and write performance, and flexible data schemas are crucial, such as real-time analytics, IoT data, and large-scale web applications.
In Cassandra, data modeling is query-driven. The data access patterns and application queries determine the structure and organization of data which then used to design the database tables.
Data is modeled around specific queries. Queries are best designed to access a single table, which implies that all entities involved in a query must be in the same table to make data access (reads) very fast. Data is modeled to best suit a query or a set of queries. A table could have one or more entities as best suits a query. As entities do typically have relationships among them and queries could involve entities with relationships among them, a single entity may be included in multiple tables [7].
Unlike a relational database model in which queries make use of table joins to get data from multiple tables, joins are not supported in Cassandra so all required fields (columns) must be grouped together in a single table. Since each query is backed by a table, data is duplicated across multiple tables in a process known as denormalization. Data duplication and a high write throughput are used to achieve a high read performance [8].
 Figure 5: Shopping Cart model.
Figure 5: Shopping Cart model.
Using CQL to define table "customer":
CREATE TABLE customer (
cus_id UUID PRIMARY KEY,
cus_name TEXT,
cus_document_number TEXT,
cus_status TEXT,
cus_credit_score TEXT,
cus_addresses SET<frozen<address_type>>,
cus_orders LIST<UUID>
);Using Java to define table "customer":
@Table(value = "customer")
@Data
public class Customer {
@Id
@PrimaryKeyColumn(name = "cus_id", ordinal = 0, type = PrimaryKeyType.PARTITIONED)
@CassandraType(type = Name.UUID)
private UUID id;
@Column("cus_name")
@CassandraType(type = Name.TEXT)
private String costumerName;
@Column("cus_document_number")
@CassandraType(type = Name.TEXT)
private String customerDocumentNumber;
@Column("cus_status")
@CassandraType(type = Name.TEXT)
private String customerStatus;
@Column("cus_credit_score")
@CassandraType(type = Name.TEXT)
private String customerCreditScore;
@Column("cus_addresses")
@CassandraType(type = Name.SET, typeArguments = { Name.UDT }, userTypeName = "address_type")
private Set<AddressType> addresses;
@Column("cus_orders")
@CassandraType(type = Name.LIST, typeArguments = { Name.UUID })
private List<UUID> customerOrders;
}Note that when we need certain information, we simply replicate it and if it is multiple, we remove the atomicity, which makes the reading very fast.
So we've learned all these things, but how am I going to get the information I need? Who will ensure consistency? Simple, the responsible for consistency is not the database, but the application. For this it is important to know what your queries will be and what the business rules are, let's see a simple example of an order below:
public ResponseEntity<Order> insert(Order order) {
order.setOrderOfferingId(UUID.randomUUID());
Customer customer = customerService.getById(order.getCustomerId());
if (customer == null) {
return ResponseEntity.notFound().build();
}
order.setOrderOfferingInstanDate(LocalDate.now());
calculateFinalPrice(order);
orderRepository.save(order);
updateCustomerWithNewOrder(customer, order);
return ResponseEntity.ok(order);
}Note that from the created order, an update is made to the customer associated with the order with a new order UUID, which will cause the list of orders for the customer to receive the newest order created by him. The main concept to work with Cassandra is to be aware that consistency problems are solved with business rules, for example, if it is not desired to include a role table, we can simply create an Enum, instead of performing a database query to evaluate the created access levels.
If you want just a single node to test your code and persist some data, you can use the example in the docker-compose file, which is running a single Cassandra instance and exposing the ports to use out of the docker network. Remember that if you need to connect your Java application to a instance you need to set the application.yml with the correct contact-point which can be the container ip address, if you're not exposing the instance, or the container name, if you're running your Java application in a docker container in the same database network.
version: '3.1'
services:
mycassandra:
image: cassandra
container_name: mycassandra
ports:
- "9042:9042" # Default port used for client-to-node communication.
- "7000:7000" # Default port used for inter-node communication within a Cassandra cluster.
volumes:
- cassandra-data:/var/lib/cassandra
volumes:
cassandra-data:If you want to use a multi-node cluster, you can use the docker-compose file setting the seed node and the worker node.
version: '3.1'
services:
cassandra-seed:
image: cassandra
ports:
- "9042:9042" # Native transport
- "7199:7199" # JMX
- "9160:9160" # Thrift clients
environment:
- CASSANDRA_SEEDS=cassandra-seed
- CASSANDRA_CLUSTER_NAME=cassandra-cluster
- CASSANDRA_PASSWORD_SEEDER=yes
- CASSANDRA_PASSWORD=cassandra
- MAX_HEAP_SIZE=2G
- HEAP_NEWSIZE=200M
cassandra-node:
image: cassandra
environment:
- CASSANDRA_SEEDS=cassandra-seed
- CASSANDRA_CLUSTER_NAME=cassandra-cluster
- CASSANDRA_PASSWORD=cassandra
- MAX_HEAP_SIZE=2G
- HEAP_NEWSIZE=200M
depends_on:
- "cassandra-seed"After that, you can run docker-compose -f docker-compose.yml up -d --scale cassandra-node=2 to run a cassandra cluster with two nodes. Note that it can be used to develop the Java application, but it's not good to use in productions, mainly when we're talking about persist data using multi-node cluster. The autor of this repository recommends to use the first docker-compose file to develop your own SpringBoot application, test some stuffs with the second, but for data operations, even with a test environment, is better to use e Kubernetes Cassandra Cluster.
Cassandra multi dc cluster using docker-compose:
version: '3.1'
services:
cassandra-seed-dc1-rack1-node1:
image: cassandra
ports:
- "9042:9042"
environment:
- CASSANDRA_CLUSTER_NAME=cassandra-cluster
- CASSANDRA_DC=dc1
- CASSANDRA_RACK=rack1
- CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch
- CASSANDRA_SEEDS=cassandra-seed-dc1-rack1-node1,cassandra-seed-dc2-rack1-node1
- CASSANDRA_PASSWORD_SEEDER=yes
- CASSANDRA_PASSWORD=cassandra
- MAX_HEAP_SIZE=2G
- HEAP_NEWSIZE=200M
volumes:
- ./cassandra/cassandra-rackdc-dc1-rack1.properties:/etc/cassandra/cassandra-rackdc.properties
cassandra-seed-dc2-rack1-node1:
image: cassandra
ports:
- "9043:9042"
environment:
- CASSANDRA_CLUSTER_NAME=cassandra-cluster
- CASSANDRA_DC=dc2
- CASSANDRA_RACK=rack1
- CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch
- CASSANDRA_SEEDS=cassandra-seed-dc1-rack1-node1,cassandra-seed-dc2-rack1-node1
- CASSANDRA_PASSWORD_SEEDER=yes
- CASSANDRA_PASSWORD=cassandra
- MAX_HEAP_SIZE=2G
- HEAP_NEWSIZE=200M
volumes:
- ./cassandra/cassandra-rackdc-dc2-rack1.properties:/etc/cassandra/cassandra-rackdc.properties
cassandra-node-dc1-rack1-node2:
image: cassandra
environment:
- CASSANDRA_CLUSTER_NAME=cassandra-cluster
- CASSANDRA_DC=dc1
- CASSANDRA_RACK=rack1
- CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch
- CASSANDRA_SEEDS=cassandra-seed-dc1-rack1-node1,cassandra-seed-dc2-rack1-node1
- CASSANDRA_PASSWORD=cassandra
- MAX_HEAP_SIZE=2G
- HEAP_NEWSIZE=200M
volumes:
- ./cassandra/cassandra-rackdc-dc1-rack1.properties:/etc/cassandra/cassandra-rackdc.properties
cassandra-node-dc2-rack1-node2:
image: cassandra
environment:
- CASSANDRA_CLUSTER_NAME=cassandra-cluster
- CASSANDRA_DC=dc2
- CASSANDRA_RACK=rack1
- CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch
- CASSANDRA_SEEDS=cassandra-seed-dc1-rack1-node1,cassandra-seed-dc2-rack1-node1
- CASSANDRA_PASSWORD=cassandra
- MAX_HEAP_SIZE=2G
- HEAP_NEWSIZE=200M
volumes:
- ./cassandra/cassandra-rackdc-dc2-rack1.properties:/etc/cassandra/cassandra-rackdc.propertiesNow we know how to use Apache Cassandra in a docker container, let's to do a introduction to Multi-Datacenter (DC) Architecture using Apache Cassandra.
Apache Cassandra is a distributed NoSQL database known for its ability to handle massive amounts of data with high availability and fault tolerance. When dealing with geographically distributed applications, a Multi-Datacenter (DC) architecture becomes crucial to ensure low-latency access and disaster recovery. In a Multi-DC setup, Cassandra clusters are spread across multiple physical locations or data centers, enabling data to be replicated and accessed efficiently across different regions.

Figure 6: Multi-Datacenter Architecture.

Figure 7: Cassandra Operator Storage.
The image above shows basic storage orchestration by StatefulSet applications, which have persistent operations and Write/Read transactions. In Kubernetes, the object type to use for applications that have state, like databases, is the StatefulSet[9].
- Build a book tracker app (Spring Boot + Cassandra)
- Introdução ao Cassandra - Cassandra Day Brasil 2022
- Desenvolvimento de Aplicações - Cassandra Day Brasil 2022
- Introduction to Spring Data Cassandra
Apache Cassandra is an extremely powerful database and if used correctly it is possible to create applications with gigantic availability and scalability, the repository is a simple example of how to perform a ShoppingCart using Cassandra, however the code can and should be improved, suggestions are needed to content improvement. Furthermore, Apache Cassandra contains hundreds of features beyond those shown in the example that can be applied to increase performance.
- [1]: What is Apache Cassandra?
- [2]: Want more power? Add more nodes
- [3]: Replication ensures reliability and fault tolerance
- [4]: Comparative Analysis of Relational and Non-relational Databases in the Context of Performance in Web Applications
- [5]: The Cassandra Query Language (CQL)
- [6]: User-Defined Types (UDTs)
- [7]: What is Data Modeling?
- [8]: Query-driven modeling
- [9]: Using StatefulSets