This repo contains code for our ECCV 2022 paper.
Learning Algebraic Representation for Systematic Generalization in Abstract Reasoning
Chi Zhang*, Sirui Xie*, Baoxiong Jia*, Ying Nian Wu, Song-Chun Zhu, Yixin Zhu
Proceedings of the European Conference on Computer Vision (ECCV), 2022
(* indicates equal contribution.)
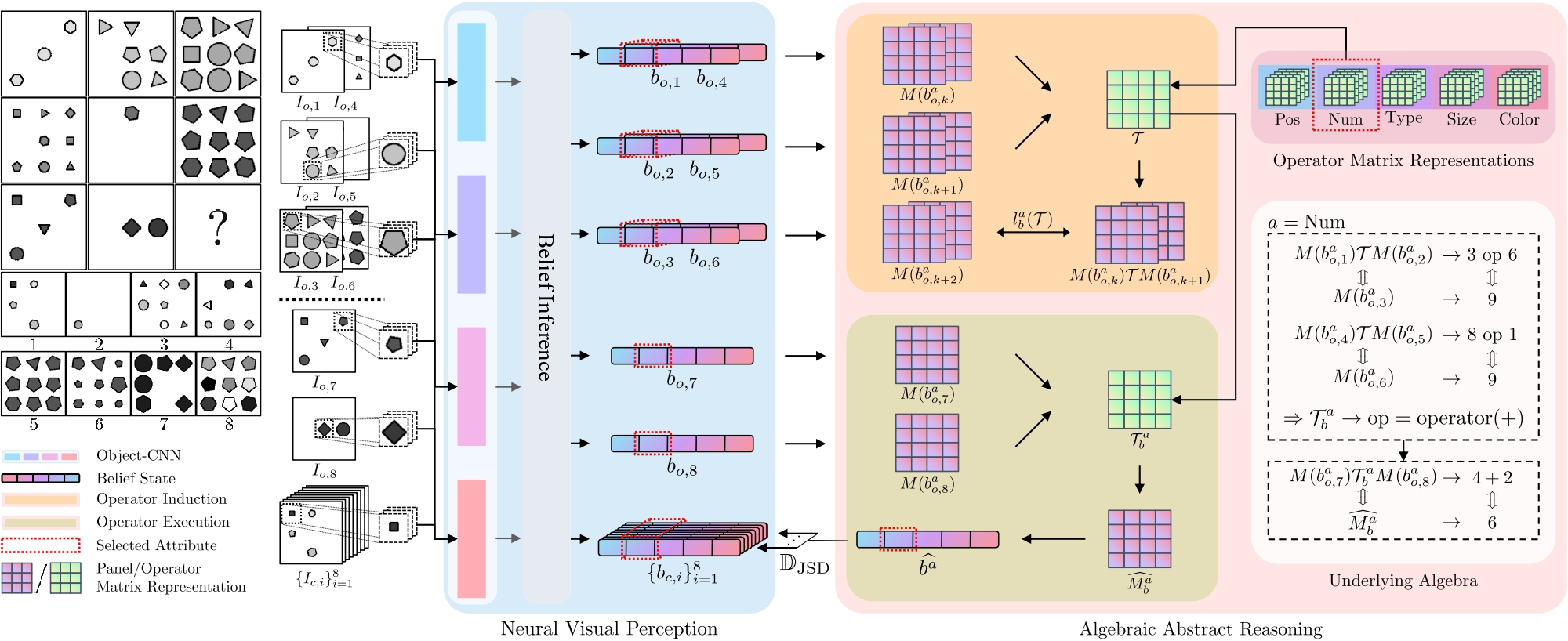
Is intelligence realized by connectionist or classicist? While connectionist approaches have achieved superhuman performance, there has been growing evidence that such task-specific superiority is particularly fragile in systematic generalization. This observation lies in the central debate between connectionist and classicist, wherein the latter continually advocates an algebraic treatment in cognitive architectures. In this work, we follow the classicist's call and propose a hybrid approach to improve systematic generalization in reasoning. Specifically, we showcase a prototype with algebraic representation for the abstract spatial-temporal reasoning task of Raven’s Progressive Matrices (RPM) and present the ALgebra-Aware Neuro-Semi-Symbolic (ALANS) learner. The ALANS learner is motivated by abstract algebra and the representation theory. It consists of a neural visual perception frontend and an algebraic abstract reasoning backend: the frontend summarizes the visual information from object-based representation, while the backend transforms it into an algebraic structure and induces the hidden operator on the fly. The induced operator is later executed to predict the answer's representation, and the choice most similar to the prediction is selected as the solution. Extensive experiments show that by incorporating an algebraic treatment, the ALANS learner outperforms various pure connectionist models in domains requiring systematic generalization. We further show the generative nature of the learned algebraic representation; it can be decoded by isomorphism to generate an answer.
The following table shows the performance of various methods on systematic generalization splits generated from the RAVEN method (upper half) and the I-RAVEN method (lower half). For details, please check our paper.
| Method | MXGNet | ResNet+DRT | ResNet | HriNet | LEN | WReN | SCL | CoPINet | ALANS | ALANS-Ind | ALANS-V |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Systematicity | 20.95% | 33.00% | 27.35% | 28.05% | 40.15% | 35.20% | 37.35% | 59.30% | 78.45% | 52.70% | 93.85% |
| Productivity | 30.40% | 27.95% | 27.05% | 31.45% | 42.30% | 56.95% | 51.10% | 60.00% | 79.95% | 36.45% | 90.20% |
| Localism | 28.80% | 24.90% | 23.05% | 29.70% | 39.65% | 38.70% | 47.75% | 60.10% | 80.50% | 59.80% | 95.30% |
| Average | 26.72% | 28.62% | 25.82% | 29.73% | 40.70% | 43.62% | 45.40% | 59.80% | 79.63% | 48.65% | 93.12% |
| Systematicity | 13.35% | 13.50% | 14.20% | 21.00% | 17.40% | 15.00% | 24.90% | 18.35% | 64.80% | 52.80% | 84.85% |
| Productivity | 14.10% | 16.10% | 20.70% | 20.35% | 19.70% | 17.95% | 22.20% | 29.10% | 65.55% | 32.10% | 86.55% |
| Localism | 15.80% | 13.85% | 17.45% | 24.60% | 20.15% | 19.70% | 29.95% | 31.85% | 65.90% | 50.70% | 90.95% |
| Average | 14.42% | 14.48% | 17.45% | 21.98% | 19.08% | 17.55% | 25.68% | 26.43% | 65.42% | 45.20% | 87.45% |
Important
- Python 3.8
- PyTorch (<=1.9.1 for
torch.solve) - CUDA and cuDNN expected
See requirements.txt for a full list of packages required.
To train the ALANS learner, one needs to first extract rule annotations for the training configuration. We provide a simple script in src/auxiliary for doing this. Properly set path in the main() function, and your dataset folder will be populated with rule annotations in npz files.
To train the ALANS learner, run
python src/main.py train --dataset <path to dataset>
You can check main.py for a full list of arguments you can adjust.
In the codebase, window sliding and image preprocessing are delegated to the dataset loader and the code only supports training on configurations with a single component.
Training from scratch is extremely hard, so we provide starter checkpoints in assets/. You can use those checkpoints for your training. For additional training details, please refer to the supplementary matrial.
To test on a configuration, run
python src/main.py test --dataset <path to dataset> --config <new config> --model-path <path to a trained model>
The code has improved designs from PrAE and does not raise CUDA memory issues.
If you find the paper and/or the code helpful, please cite us.
@inproceedings{zhang2022learning,
title={Learning Algebraic Representation for Systematic Generalization in Abstract Reasoning},
author={Zhang, Chi and Xie, Sirui and Jia, Baoxiong and Wu, Ying Nian and Zhu, Song-Chun and Zhu, Yixin},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022}
}
We'd like to express our gratitude towards all the colleagues and anonymous reviewers for helping us improve the paper. The project is impossible to finish without the following open-source implementations.