Attentional Factorization Machines
Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
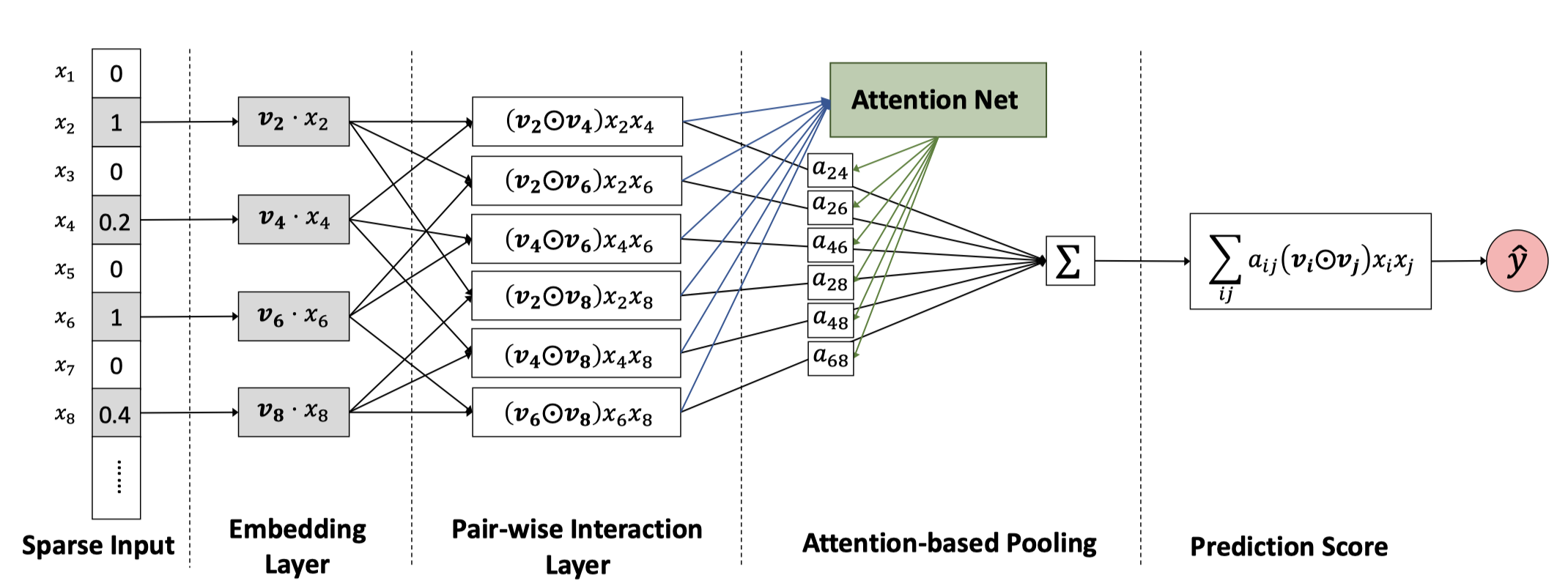
创新:基于Attention的Pooling层,与一般的Attention机制不同,具体可以看原文笔记
原文笔记: https://mp.weixin.qq.com/s/hPCS9Dw2vT2pwdWwPo0EJg
采用Criteo数据集进行测试。数据集的处理见utils文件,主要分为:
- 考虑到Criteo文件过大,因此可以通过
read_part和sample_sum读取部分数据进行测试; - 对缺失数据进行填充;
- 对密集数据
I1-I13进行归一化处理,对稀疏数据C1-C26进行重新编码LabelEncoder; - 整理得到
feature_columns; - 切分数据集,最后返回
feature_columns, (train_X, train_y), (test_X, test_y);
class AFM(keras.Model):
def __init__(self, feature_columns, mode, activation='relu', embed_reg=1e-4):
"""
AFM
:param feature_columns: A list. dense_feature_columns and sparse_feature_columns
:param mode:A string. 'max'(MAX Pooling) or 'avg'(Average Pooling) or 'att'(Attention)
:param activation: A string. Activation function of attention.
:param embed_reg: A scalar. the regularizer of embedding
"""- file:Criteo文件;
- read_part:是否读取部分数据,
True; - sample_num:读取部分时,样本数量,
5000000; - test_size:测试集比例,
0.2; - embed_dim:Embedding维度,
8; - mode:Pooling的类型,
att; - learning_rate:学习率,
0.001; - batch_size:
4096; - epoch:
10;
由于AFM过慢,所以采用Criteo数据集中前10w条数据,最终测试集的结果为:
- max:
AUC:0.736344; - avg:
AUC:0.597510;---训练20epoch - att:
AUC:0.734991;