Data
 The data file formats used in the Juicer / Juicebox / Straw ecosystem are described below.
The data file formats used in the Juicer / Juicebox / Straw ecosystem are described below.
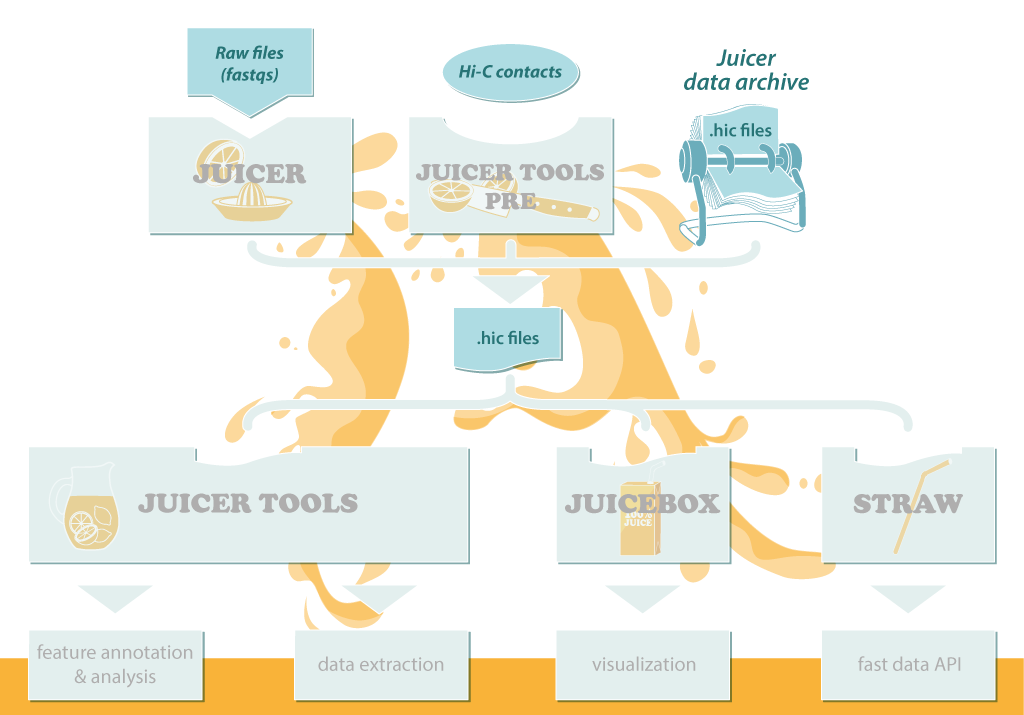
The Juicer data archive is available at aidenlab.org/data.html and consists of hic files, described below.
The .hic file is a highly compressed binary file that stores contact matrices from multiple resolutions in a clever way, allowing random access. To create a .hic file, use Pre. To extract data from a .hic file, use dump; or access the data directly with the Straw API. All of the feature annotation algorithms operate directly on .hic files. Juicebox uses the fast querying capabilities of .hic files to make it possible to zoom in and out of many different resolutions quickly.
The .hic file format is described extensively in Durand and Shamim et al., 2016. You can look at this table from the supplementary materials to get the exact specification, or at this document.
Hi-C contacts are represented as one line per read; the minimal necessary information is the chromosome and position of each read. Pre takes a number of different possible formats to represent Hi-C contacts.
These are the raw data files that come off the sequencer. They include the read name, the read (a string of A,C,T,G, or N) and base quality information. Juicer takes fastq files and transforms them into contact matrices stored in a .hic file. See this article for more information.