jendeley is a JSON-based document organizing software.
jendeleyis JSON-based. You can see and edit your database quickly.jendeleyworks locally. Your important database is owned only by you. No cloud.jendeleyis browser-based. You can run it anywhere node.js runs.
- Why jendeley?
- Quickstart
- Install
- Generate JSON database file
- Launch the service daemon and open the web user interface
- Use the web user interface
- Advanced topics
- Contact me
- Support me
As programmers, we need various documents in different formats, such as recent machine learning papers, classic compiler books, CPU and accelerator specification documents, programming language documents, and informative blog articles. To efficiently manage these documents, it's essential to categorize and classify them. Additionally, we need to ensure that they are saved and accessible long-term, as we never know when we need them.
To address these challenges, I developed jendeley. It allows you to register both PDFs and webpages in the same database, making categorization easy through the use of tags. Moreover, the database is stored as a plain text JSON file, making it easily editable using your preferred editor. This means that even if jendeley's development process ends, you can still access your information and create alternative applications to manage it.
$ npm install @a_kawashiro/jendeley -g
$ jendeley scan --papers_dir <YOUR PDFs DIR>
$ jendeley launch --db <YOUR PDFs DIR>/jendeley_db.jsonThen you can see a screen like this!
{kind=link}
{kind=link}
$ npm install @a_kawashiro/jendeley -gYou can find the latest package at npm page.
$ jendeley scan --papers_dir <YOUR PDFs DIR>This command outputs the database to <YOUR PDFs DIR>/jendeley_db.json. If you have no PDF file, please specify an empty directory as <YOUR PDFs DIR>.
If jendeley encounters an issue scanning some PDFs, it generates a shell script named edit_and_run.sh. Please refer to the following subsection to learn how to rename the files accordingly, so that jendeley can properly recognize them.
jendeley uses a filename to find the document ID (e.g., DOI or ISBN)). jendeley recognizes parts of a filename that are not enclosed by [ and ] as the title of the file. So I recommend you to name the file accordingly, for example,
RustHorn CHC-based Verification for Rust Programs.pdf- When the document's title includes spaces, the filename should include spaces.
RustHorn CHC-based Verification for Rust Programs [matushita].pdf- If you want to write additional information in a filename, please enclose it by
[and].
- If you want to write additional information in a filename, please enclose it by
jendeley heavily relies on DOI or ISBN to find the title, authors and the year of publication of PDFs. When DOI or ISBN can not be automatically found by jendeley, you can manually specify DOI of the PDF using the filename.
- To specify DOI, change the filename to include
[jendeley doi <DOI with all delimiters replaced with underscore>].- For example,
cyclone [jendeley doi 10_1145_512529_512563].pdf.
- For example,
- To specify ISBN, change the filename to include
[jendeley isbn <ISBN>].- For example,
Types and Programming Languages [jendeley isbn 0262162091].pdf.
- For example,
- When the PDF doesn't have any DOI or ISBN, you can specify it by
[jendeley no id].- For example,
ARM reference manual [jendeley no id].pdf.
- For example,
jendeley launch --db <YOUR PDFs DIR>/jendeley_db.json
This command launches the jendeley daemon and opens the web user interface in your web browser at http://localhost:5000. You have the option to change the default port by using the --port option.
When using Linux, you can set up jendeley to start automatically by using systemd. To do this, create a file named ~/.config/systemd/user/jendeley.service with the following contents, and then run systemctl --user enable jendeley && systemctl --user start jendeley. Then, you can access jendeley at http://localhost:5000. Logs are accessible with the command journalctl --user -f -u jendeley.service.
# jendeley.service
[Unit]
Description=jendeley JSON-based document organization software
[Service]
ExecStart=jendeley launch --db <FILL PATH TO THE YOUR DATABASE JSON FILE>
[Install]
WantedBy=default.target
When using Windows, you can set up jendeley to launch automatically at startup. To do this, first open the startup directory by pressing Windows+R and typing shell:startup and then pressing Enter.

And make autorun-jendeley.bat with the following contents using notepad.exe.
:: autorun-jendeley.bat
jendeley launch --db <FILL PATH TO THE YOUR DATABASE JSON FILE> >> <FILL PATH TO THE LOG FILE>

When jendeley launches, jendeley opens the web user interface automatically. If not, please access http://localhost:5000/.

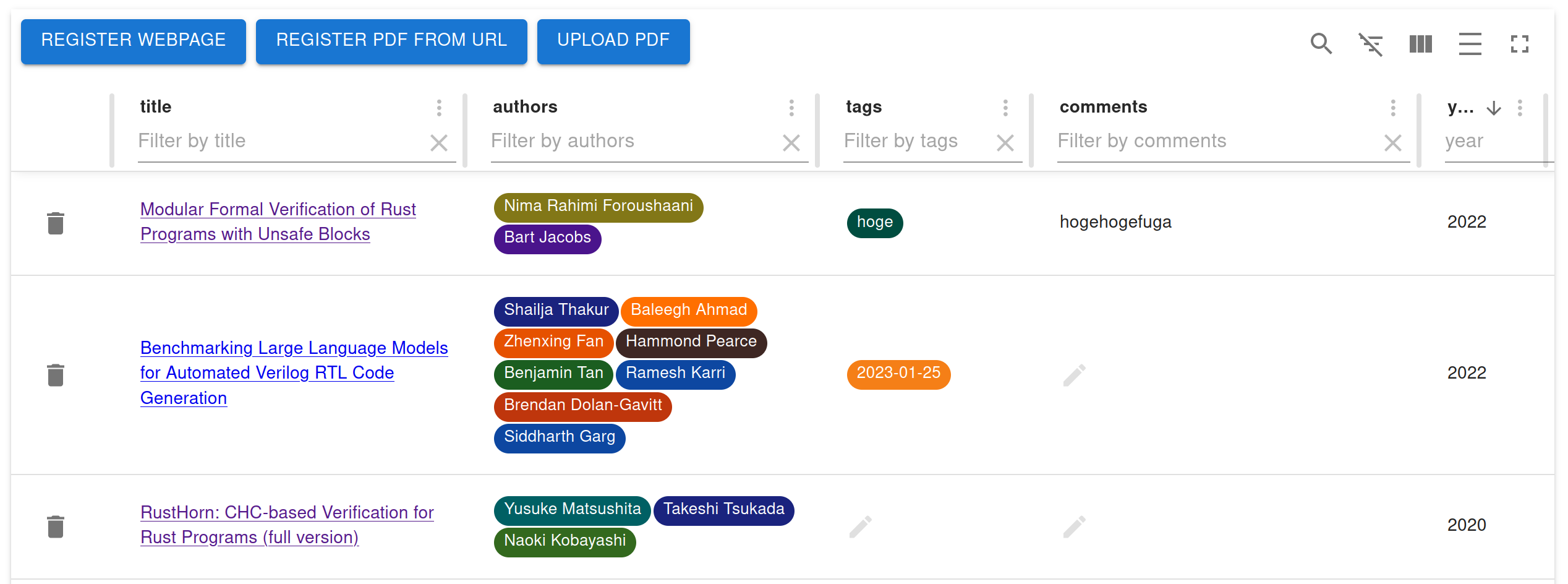
You can add a webpage to the database using REGISTER WEBPAGE button. When you register, you can write tags or comments. Tags are just commas (,) separated text. By the way, the date tags are automatically added to the database.

You can add a PDF file to the web by using the REGISTER PDF FROM URL button. When you add the file, jendeley will attempt to locate its Digital object identifier (DOI) or International Standard Book Number (ISBN) and register the meta information, such as the author's name or publication date, to the database. In some cases, jendeley may not be able to find the DOI or ISBN for the PDF, or there may not be a corresponding DOI or ISBN for it. In such situations, you can specify the DOI or ISBN by using the filename. For more information, please refer to the Recommended filename style section.

You can upload a PDF file in your computer using UPLOAD PDF button.
You can edit tags or comments after you register. You can edit tags or comments by double-clicking them. Comments are interpreted as Markdown.

Furthermore, you can filter the database using tags or comments.

Because jendeley is fully JSON-based, you can quickly check the database's contents.
$ cat jendeley_db.json | jq '.' | head
{
"jendeley_meta": {
"idType": "meta",
"version": "0.0.17"
},
"doi_10.1145/1122445.1122456": {
"path": "/A Comprehensive Survey of Neural Architecture Search.pdf",
"idType": "doi",
"tags": [],
"comments": "",You can edit your database using your preferred editor. However, after making the changes, it is important to verify that your database is still valid as a jendeley database using the command jendeley validate --db <PATH TO THE DATABASE>.
You can check the source code https://github.com/akawashiro/jendeley here. We welcome your pull request.
You can use LLM to generate tags for your documents. Launch the LLM server by running the following command.
$ ./run_ollama.shYou can find ./run_ollama.sh at run_ollama.sh.
Then, you can enable automatic tagging by setting the --experimental_use_ollama_server option when launching jendeley.
For example,
$ jendeley launch --db <YOUR PDFs DIR>/jendeley_db.json --experimental_use_ollama_serverTo run the LLM server automatically, you can use the following systemd service file.
$ cat ~/.config/systemd/user/ollama-jendeley.service
# jendeley.service
[Unit]
Description=jendeley JSON-based document organization software
[Service]
ExecStart=<PATH_TO_NODE>/node/v18.16.0/lib/node_modules/@a_kawashiro/jendeley/run_ollama.sh
[Install]
WantedBy=default.target
$ systemctl --user enable ollama-jendeley
$ systemctl --user start ollama-jendeleyTo check the LLM server's status, you can use the following command.
$ journalctl --user -f -u ollama-jendeley.serviceYou can find me on Twitter at https://twitter.com/a_kawashiro and on Mastodon at https://mstdn.jp/@a_kawashiro. Additional contact information can be found on my website at https://akawashiro.github.io/#links. Also, feel free to create an issue or submit a pull request on the repository.
Please star akawashiro/jendeley. It encourages me a lot.