本次比赛以阿里电商广告为研究对象,提供了淘宝平台的海量真实交易数据,参赛选手通过人工智能技术构建预测模型预估用户的购买意向,即给定广告点击相关的用户(user)、广告商品(ad)、检索词(query)、上下文内容(context)、商店(shop)等信息的条件下预测广告产生购买行为的概率(pCVR),形式化定义为:pCVR=P(conversion=1 | query, user, ad, context, shop)。
结合淘宝平台的业务场景和不同的流量特点,我们定义了以下两类挑战:
- 日常的转化率预估
- 特殊日期的转化率预估

- 数据探索与特征使用方案:业务逻辑和特征覆盖率
- 数据采样:样本采样与过滤
- 根据特征使用方案构造特征:基础特征、平稳特征、动态特征、高阶特征、文本特征、偏好特征、趋势特征、leak特征等
- 特征分类:连续性、二值型、枚举型
- 特征处理与分析:特征归一化、离散化(one-hot)、缺失值填补
- 特征选择:过滤型、包裹型(采用该方案,KFlod)、嵌入型
- 模型选择:bagging(采用该方案,KFlod)、stacking
复赛提供了8月31日到9月7号12:00:00的数据,需要预测9月7号12:00:00~24:00:00的广告转化率。
我们首先分析了每天的流量、转化率。
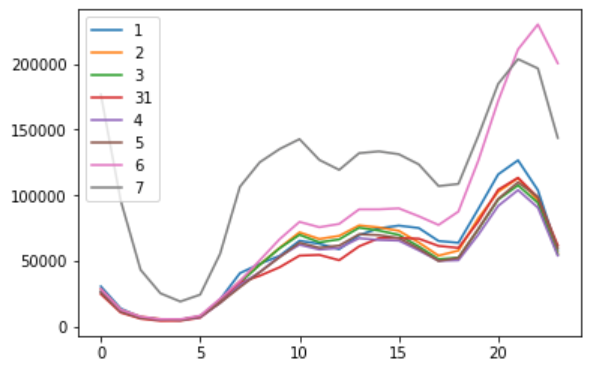

通过分析,我们可以发现6号和7号的场景与前6天的场景不同,点击量在这两天猛增,在6号的转化率突然降低(大家观望并没有发生消费),7号转化率突然增高(大量的消费记录),初步推测7号应该为双11或者618。
我们采用7号上半天的数据作为训练集,每次验证随机选择20%数据作为验证集。这样子做的优点是可以加快训练,节省时间,可以验证更多的特征及思路。

通过该图可以发现大多数用户的点击量为1,所以存在用户冷启动问题,即该用户没有历史记录,不能从历史数据中获得该用户的购物意向。针对每个冷启动用户,我们只能从点击商品的属性和上下文信息中获得购物意向。
我们的解决方案:
可以通过有多次点击用户的历史行为学习每个商品的相似度。具体的是将用户点击商品行为路径转化为成word2vec的输入形式。通过word2vec计算每个商品的向量表示,通过向量表示可以表示商品的相似度。
| user_id | item_id | history_click |
|---|---|---|
| 1 | A | A,B,C,A |
| 1 | B | A,B,C,A |
| 1 | C | A,B,C,A |
| 1 | A | A,B,C,A |
第一的解决方案:
具体思路:对于单次用户,我们只能通过他搜索的和商品实际的属性,以及品类的确定。 对于多次用户,我们能统计出用户的属性偏好,以及用户的实际想购买的偏好。
- 捕捉用户对商品属性的偏好(占比),groupby(“user_id”).proerty.mean()
- 通过统计这些属性偏好的人和搜索item之间的关系。groupby(“item_id”).proerty.mean()
总而言之一句话:用属性来表征user_id,用user_id来表征item_id。
- 基础特征(用户、商铺、商品、上下文)
- 统计特征(全局/日/小时,31号到6号、5号,7号)user_id,user_id_item_id(个性化)等
- 时间差特征(user_id对item_id的时间差,近一天以内)
- 概率特征(转化率31号到5号)
- leak特征(当天)
- 文本特征(item_id的word2vec)
- 偏好特征(商品属性、以及查询与商品的匹配程度,例如算交集、匹配率)
- 趋势特征(例如,当天商品的价格与前七天的平均价格的差值)
- 占比特征(例如,用户-商铺点击数占商铺点击数的比重)
- 业务特征(例如,用户连续多少次点击但是没有发生购买行为)
- 竞争特征(例如,之前之后点击了多少价格更低,销售量更高的商品)
==其中关于时间差和leak特征,分别计算当前点击与上一次及下一次点击的时间差。以及近期m次点击的统计,具体来说就是比较当前点击与最近m次点击的异同。==
| user_id | item_id | history_click | path |
|---|---|---|---|
| 1 | A | 0 | |
| 1 | B | 0 | 1 |
| 1 | C | 00 | 2 |
| 1 | A | 001 | 3 |
| 2 | A | 0 | |
| 2 | A | 1 | 4 |
| 2 | B | 10 | 5 |
| 2 | A | 101 | 6 |
我们采用KFlod的方案选择特征。即将训练集分成5等份,每次选择80%的数据作为训练,剩余的20%作为验证,将每次验证结果拼接在一起可以得到整个训练集的验证结果。相当于用5个不同的模型验证了新的特征,通过该特征选择方案可以选择出可靠的特征。
通过设置每个样本的权重从而达到类别平衡。训练集的转化率为0.046,测试集的转化率预估0.037,所以我们需要加大对负样本的权重,使得预测转化率降低。

上式中expected_cvr代表期望达到的转化率,pos_example和neg_example分别是训练集中正样本和负样本的个数,pos_weight和neg_weight分别是训练集中正样本和负样本的权重。我们可以设置pos_weight固定为1,调整neg_weight即可。
在这里需要注意到,在sklearn、lgb或者xgb中有两个参数都已达到该效果,即class_weight和sample_weight。class_weight是对各个类别统一设置权重、sample_weight为各个样本设置权重,最终每个样本的权重为class_weight * sample_weight。我们这里只设置了sample_weight。
模型:xgb和lgb
融合:bagging,即Kflod。将训练集分成k等份,每次拿k-1份数据进行训练并预测测试集,将每次测试集的结果取平均作为结果。
分别通过xgb和lgb模型并采用bagging策略得到两份结果,最终取平均作为最终输出结果。
参考资料: