

Webindex is an example Apache Fluo application that incrementally indexes links to web pages in multiple ways. If you are new to Fluo, you may want start with the Fluo tour as the WebIndex application is more complicated. For more information on how the WebIndex application works, view the tables and code documentation.
Webindex utilizes multiple projects. Common Crawl web crawl data is used as the input. Apache Spark is used to initialize Fluo and incrementally load data into Fluo. Apache Accumulo is used to hold the indexes and Fluo's data. Fluo is used to continuously combine new and historical information about web pages and update an external index when changes occur. Webindex has simple UI built using Spark Java that allows querying the indexes.
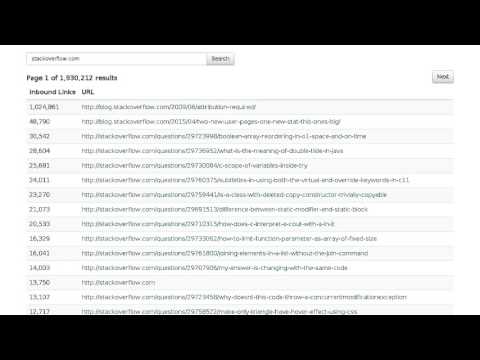
Below is a video showing repeatedly querying stackoverflow.com while Webindex was running for three days on EC2. The video was made by querying the Webindex instance periodically and taking a screenshot. More details about this video are available in this blog post.
If you are new to WebIndex, the simplest way to run the application is to run the development server. First, clone the WebIndex repo:
git clone https://github.com/astralway/webindex.git
Next, on a machine where Java and Maven are installed, run the development server using the
webindex command:
cd webindex/
./bin/webindex dev
This will build and start the development server which will log to the console. This 'dev' command
has several command line options which can be viewed by running with -h. When you want to
terminate the server, press CTRL-c.
The development server starts a MiniAccumuloCluster and runs MiniFluo on top of it. It parses a
CommonCrawl data file and creates a file at data/1000-pages.txt with 1000 pages that are loaded
into MiniFluo. The number of pages loaded can be changed to 5000 by using the command below:
./bin/webindex dev --pages 5000
The pages are processed by Fluo which exports indexes to Accumulo. The development server also starts a web application at http://localhost:4567 that queries indexes in Accumulo.
If you would like to run WebIndex on a cluster, follow the install instructions.
Metrics can be sent from the development server to InfluxDB and viewed in Grafana. You can either
setup InfluxDB+Grafana on you own or use Uno command uno setup metrics. After a metrics server
is started, start the development server the option --metrics to start sending metrics:
./bin/webindex dev --metrics
Fluo metrics can be viewed in Grafana. To view application-specific metrics for Webindex, import
the WebIndex Grafana dashboard located at contrib/webindex-dashboard.json.