Listen to any audio stream on your machine and print out the transcribed or translated audio. Based on OpenAI's Whisper project. If you want to live transcribe or translate audio from a livestream or URL, you can find it here
- Turn on stereo mix settings on windows first before running the script
- Install and add ffmpeg to your PATH
- Install CUDA to your system
- choose envs of your choices.
- clone this repo into your local storage.
- run
pip install -r requirements.txt - run
python audioWhisper.py --devices trueto getdevice_indexandchannel - run
python audioWhisper.py. Make sure to define the index ofStereo Mixoutput device if it is not2.
| --flags | Default Value | Description |
|---|---|---|
--devices |
false | To print all available devices |
--model |
small | Select model list. refer here |
--task |
transcribe | Choose between to transcribe or to translate the audio to English |
--device_index |
2 | Choose the output device to listen to and transcribe the audio from this device |
--channel |
2 | Number of channels of the output device |
--rate |
44100 | Sampling rate of the output device |
--audioseconds |
5 | Length of audio files to record (seconds) |
--audiocounts |
5 | Number of audio files to save into path |
--output_dir |
"audio" | Output directory to save audio files recorded by audioWhisper.py |
The performance of the transcribing and translating the audio are depending on your machine's performance and model you used. medium or large models could give more accurate and make sense translation while tiny and small is good enough for transcribing the english audio.
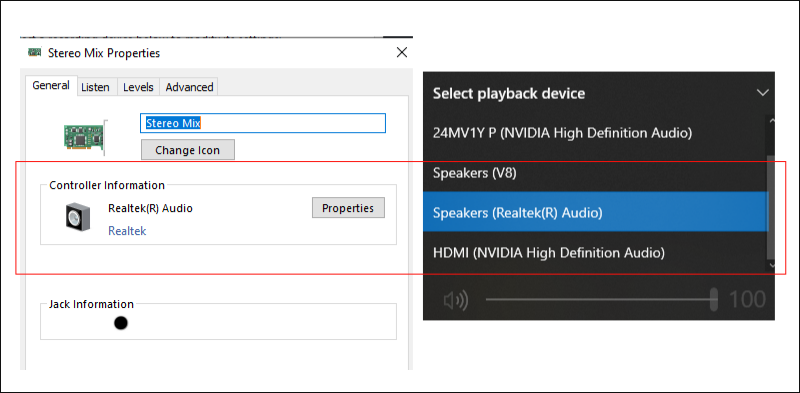
- Make sure the playback device of your machine is the same with
Stereo Mixdevice before you run the script.
The translated audio is not perfect but it can still translate the point of the talk from audio. Video demo for this app is on youtube.
The code and the model weights of Whisper are released under the MIT License. See their repo for more information. The code of this repo is under MIT License. See LICENSE for further details.