部署你自己的OpenAI 格式api😆,基于flask, transformers (使用 Baichuan2-13B-Chat-4bits 模型,可以运行在单张Tesla T4显卡) ,实现以下OpenAI接口:
- Chat /v1/chat/completions
- Models /v1/models
- Completions /v1/completions
同时实现接口相应的STREAMING模式,保证在langchain中基础调用
目前Baichuan2-13B-Chat int4量化后可在单张tesla T4显卡运行,并且效果和速度还可以,可以和gpt-3.5媲美。
- Baichuan2-13B-Chat-4bits:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
需要16g显存,如果主机显存不够可以考虑腾讯云的活动,60块钱15天32g内存、T4显卡的主机(活动已经下架,可以考虑使用Colab),非常划算😝,可以跑动baichuan2-13b-chat-4bits。
地址: https://cloud.tencent.com/act/pro/gpu-study
如果想要本地运行,T4显卡价格在5600元左右,也可以考虑2080ti魔改22g版本,某宝只要2600元左右 🤓️。
免费的Colab可以使用12G内存和T4显卡🤓️,可以考虑免费的Colab结合ngrok运行
- 打开
- 修改 NGROK_AUTHTOKEN,注意不要带双引号
- 修改运行配置,点击 修改 -> 笔记本设置 中把显卡改成T4
- 运行,点击 代码执行程序 -> 全部运行 (下载模型时间较长,请耐心等在)
- 运行结束后查看输出的ngrok外网访问链接,使用该链接请求
- 下载代码
git clone https://github.com/billvsme/my_openai_api.git
- 下载Baichuan2-13B-Chat-4bits模型
cd my_openai_api
git lfs install #需要先安装好git-lfs
git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
- 安装venv环境
mkdir ~/.venv
python -m venv ~/.venv/ai
. ~/.venv/ai/bin/activate
pip install -r requirements.txt
python my_openai_api.py
或者
gunicorn -b 0.0.0.0:5000 --workers=1 my_openai_api:app
实现了openai的models, chat, moderations 3个接口
可以参考https://platform.openai.com/docs/api-reference/chat
打开 http://127.0.0.1:5000/apidocs/
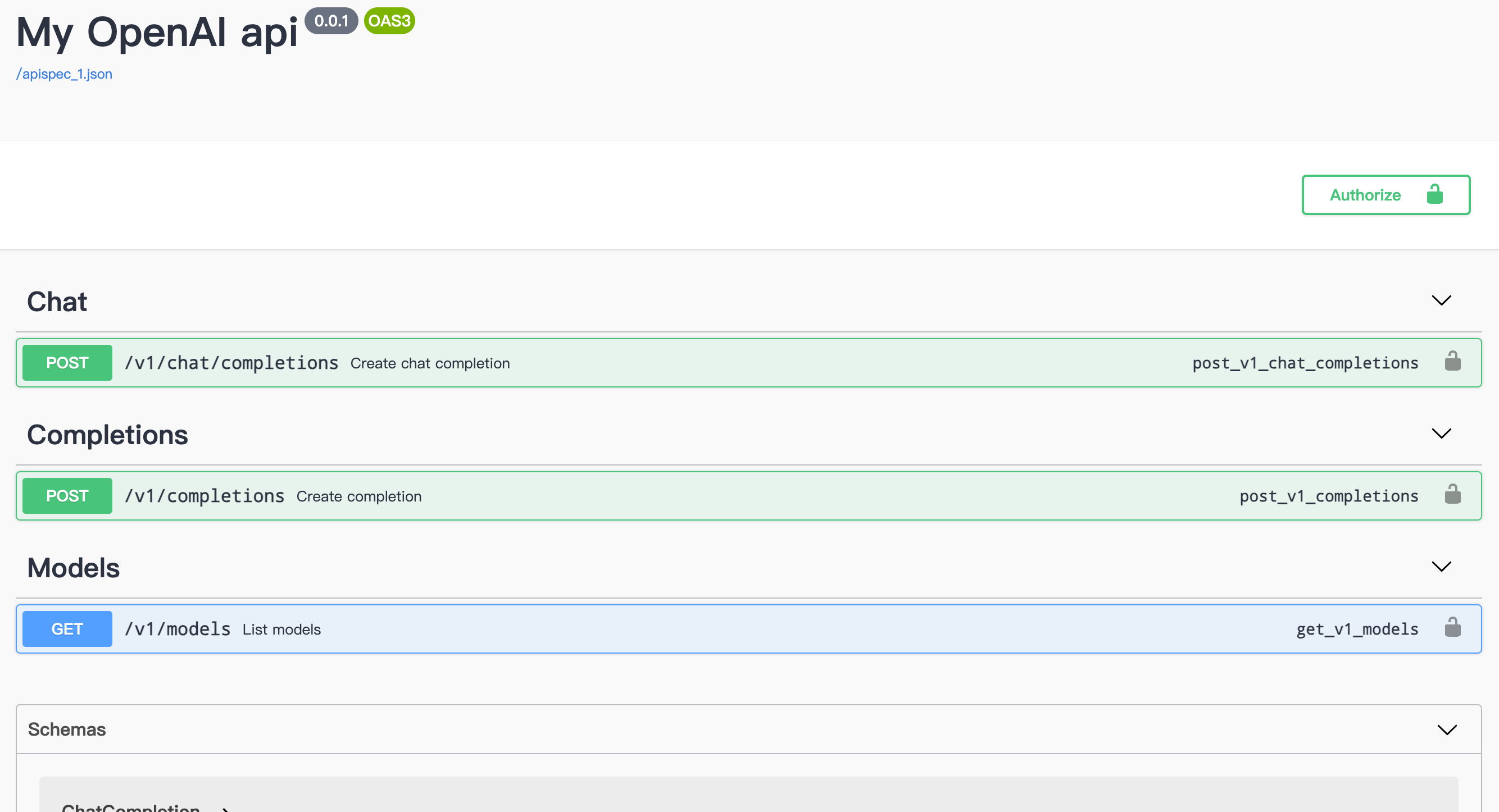
替换openai_base_api
# coding: utf-8
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.schema import (
HumanMessage,
)
openai_api_base = "http://127.0.0.1:5000/v1"
openai_api_key = "test"
# /v1/chat/completions流式响应
chat_model = ChatOpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], openai_api_base=openai_api_base, openai_api_key=openai_api_key)
resp = chat_model([HumanMessage(content="给我一个django admin的demo代码")])
chat_model.predict("你叫什么?")
# /v1/chat/completions普通响应
chat_model = ChatOpenAI(openai_api_base=openai_api_base, openai_api_key=openai_api_key)
resp = chat_model.predict("给我一个django admin的demo代码")
print(resp)
# /v1/completions流式响应
llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0, openai_api_base=openai_api_base, openai_api_key=openai_api_key)
llm("登鹳雀楼->王之涣\n夜雨寄北->")
# /v1/completions普通响应
llm = OpenAI(openai_api_base=openai_api_base, openai_api_key=openai_api_key)
print(llm("登鹳雀楼->王之涣\n夜雨寄北->"))
设置中把接口地址修改为你的ip,如果部署网页为https,注意在Chrome设置中“不安全内容”选择“允许”
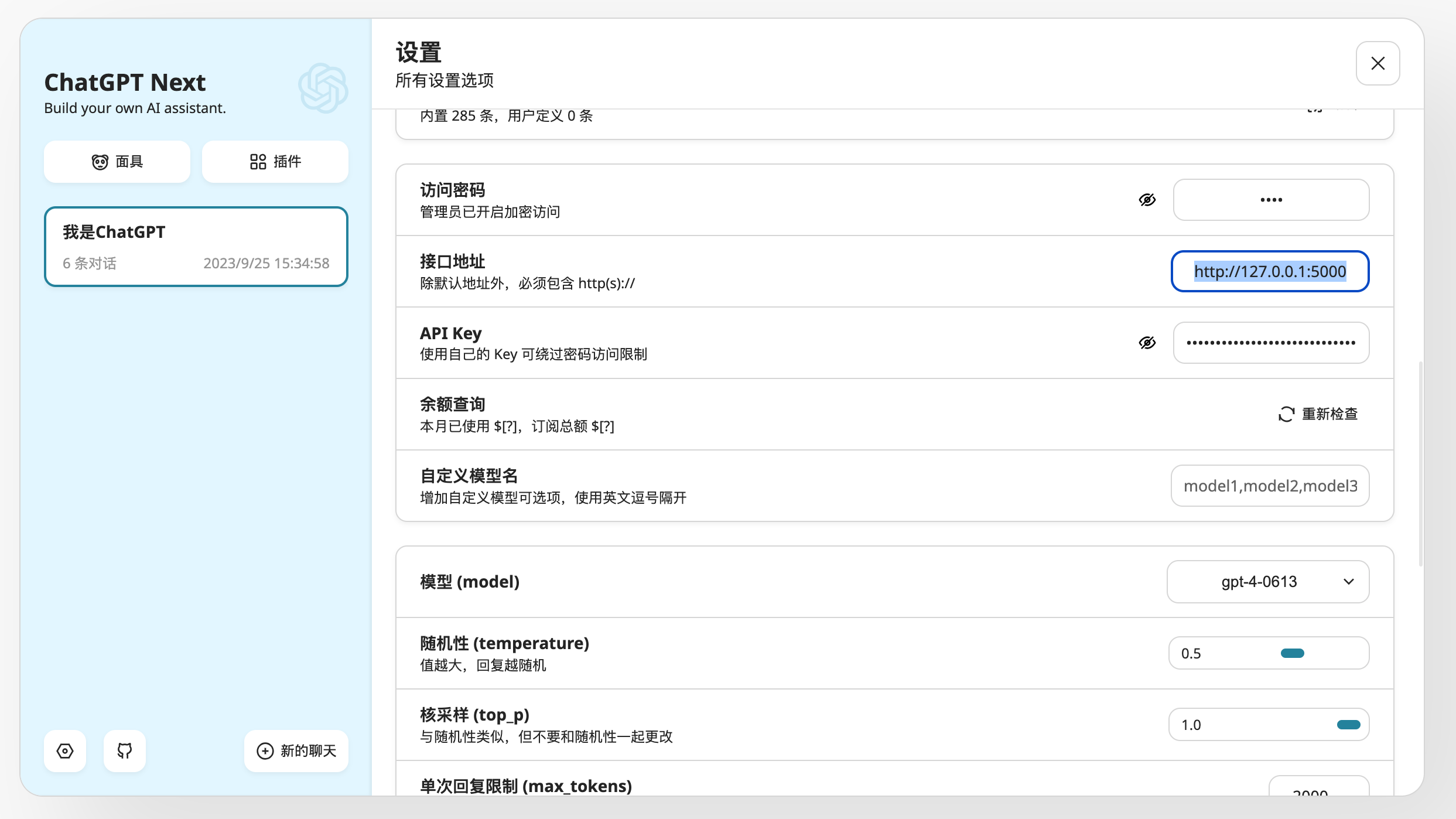
设置中把api url修改为你的ip