Programs to simulate the trajectory of three astronomical bodies through space, moving according to Newton's gravitional laws. Demonstrates periodicity in the general case for two but not three or more bodies.
3_body_illustration.py contains code to trace the path of three point objects in space.
divergence.py contains modules to generate maps of how many iterations it takes for various starting points (of one body) to diverge if a small shift is made. Code is now compatible with use of a GPU (if available) via torch. Using a mid-level gaming GPU will speed up figure generation by a factor of around 60x.
batched_divergence.py implements a batched version of divergence.py in which multiple frames (ie different planet 1 mass divergence plots) are computed simultaneously. Depending on your GPU hardware (particularly the clock speed relative to the number of active CUDA cores at any given time) and the module resolution settings, this can lead to a modest speedup (~40%) or make very little difference.
For further speedups via custom CUDA implementation, divergence.cu provides a highly optimized CUDA kernel with driver code to simulate three body divergence.
divergence_kernel.cu and divergence_transfer.py implement a ctypes-based pointer transfer to drive an optimized CUDA kernal with python, followed by retrieval and Matplotlib-based plotting of the computed array. These kernels typically give a >2x speedup relative to the pytorch code as a result of these optimizations. This library includes compiled CUDA kernels for the divergence_transfer.py binding code, so you don't need to set up your own nvidia toolkit and compiler system to run the python code.
If you want to re-compile this code for any reason, or compile similar CUDA kernels on your own, use -Xcompiler. For stand-alone CUDA kernels not expecting python bindings, compilation may be performed with only an output file flag specified.
$ nvcc -o divergence divergence.cuFor CUDA kernels that are bound to python drivers, compile with -fPIC as follows;
$ nvcc -Xcompiler -fPIC -shared -o compiled_name.so kernel_name.cuNB CUDA kernels are tested with CUDA major versions 11x and 12x, and may fail for others.
If you have multiple GPUs, head to the /distributed directory. There you will find CUDA kernels and python drivers that perform three body simulations on multiple GPUs in parallel such that with N devices you can expect the total time taken to be 1/N times the time taken for one. With 4x V100 GPUs, you can expect to simulate a 1000x1000 grid of initial positions for 50,000 steps in around 18 seconds, generating the image at the end of this file.
For single-threaded distributed CUDA kernels with python drivers, compilation requires with -fPIC as shown for the single-threaded version. For multithreaded distributed CUDA kernels for python drivers, you must specify both -fopenmp and -fPIC flags to the Xcompiler as follows:
$ nvcc -Xcompiler -fopenmp -Xcompiler -fPIC -shared -o compiled_name.so kernel_name.cuCompiling
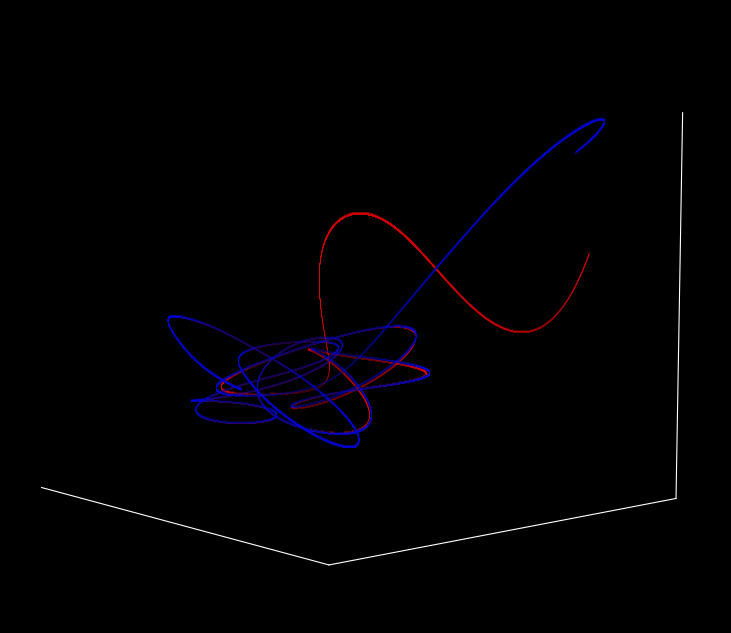
An single body's trajectory upon shifting relative to the other two bodies:
A 1000x1000 (50k steps) divergence plot.

{kind=link}