{kind=link}
Train and evaluate the VQ-VAE model for our submission to the ZeroSpeech 2020 challenge. Voice conversion samples can be found here. Pretrained weights for the 2019 English and Indonesian datasets can be found here.
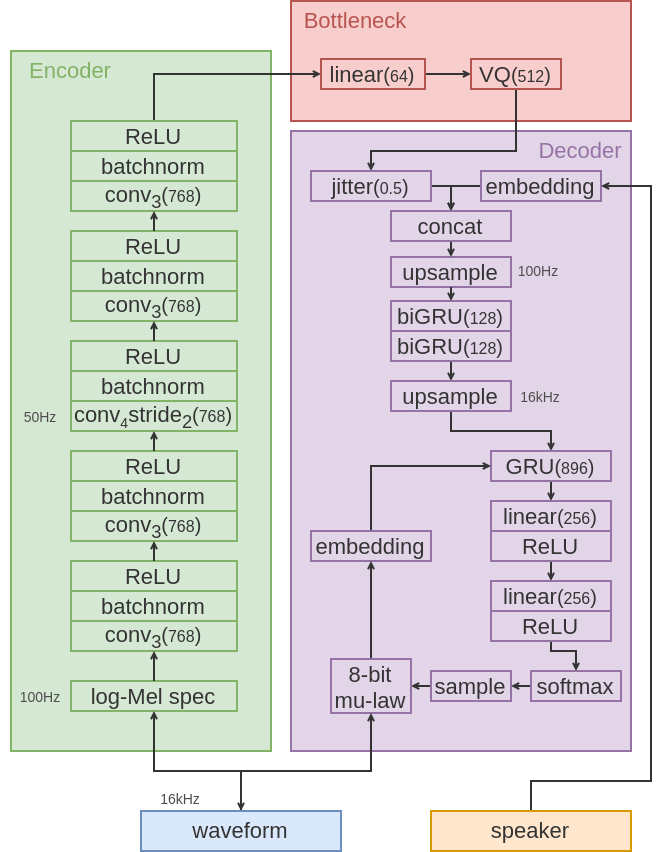
Fig 1: VQ-VAE model architecture.
-
Ensure you have Python 3 and PyTorch 1.4 or greater.
-
Install NVIDIA/apex for mixed precision training.
-
Install pip dependencies:
pip install -r requirements.txt -
For evaluation install bootphon/zerospeech2020.
-
Download and extract the ZeroSpeech2020 datasets.
-
Download the train/test splits here and extract in the root directory of the repo.
-
Preprocess audio and extract train/test log-Mel spectrograms:
python preprocess.py in_dir=/path/to/dataset dataset=[2019/english or 2019/surprise]Note:
in_dirmust be the path to the2019folder. Fordatasetchoose between2019/englishor2019/surprise. Other datasets will be added in the future.e.g. python preprocess.py in_dir=../datasets/2020/2019 dataset=2019/english
Train the models or download pretrained weights here:
python train.py checkpoint_dir=path/to/checkpoint_dir dataset=[2019/english or 2019/surprise]
e.g. python train.py checkpoint_dir=checkpoints/2019english dataset=2019/english
python convert.py checkpoint=path/to/checkpoint in_dir=path/to/wavs out_dir=path/to/out_dir synthesis_list=path/to/synthesis_list dataset=[2019/english or 2019/surprise]
Note: the synthesis list is a json file:
[
[
"english/test/S002_0379088085",
"V002",
"V002_0379088085"
]
]
containing a list of items with a) the path (relative to in_dir) of the source wav files;
b) the target speaker (see datasets/2019/english/speakers.json for a list of options);
and c) the target file name.
e.g. python convert.py checkpoint=checkpoints/2019english/model.ckpt-500000.pt in_dir=../datasets/2020/2019 out_dir=submission/2019/english/test synthesis_list=datasets/2019/english/synthesis.json dataset=2019/english
Voice conversion samples can be found here.
-
Encode test data for evaluation:
python encode.py checkpoint=path/to/checkpoint out_dir=path/to/out_dir dataset=[2019/english or 2019/surprise]e.g. python encode.py checkpoint=checkpoints/2019english/model.ckpt-500000.pt out_dir=submission/2019/english/test dataset=2019/english -
Run ABX evaluation script (see bootphon/zerospeech2020).
The ABX score for the pretrained english model (available here) is:
{
"2019": {
"english": {
"scores": {
"abx": 14.043611615570672,
"bitrate": 412.2387509949519
},
"details_bitrate": {
"test": 412.2387509949519
},
"details_abx": {
"test": {
"cosine": 14.043611615570672,
"KL": 50.0,
"levenshtein": 35.927825062038984
}
}
}
}
}
This work is based on:
-
Chorowski, Jan, et al. "Unsupervised speech representation learning using wavenet autoencoders." IEEE/ACM transactions on audio, speech, and language processing 27.12 (2019): 2041-2053.
-
Lorenzo-Trueba, Jaime, et al. "Towards achieving robust universal neural vocoding." INTERSPEECH. 2019.
-
van den Oord, Aaron, and Oriol Vinyals. "Neural discrete representation learning." Advances in Neural Information Processing Systems. 2017.