R package for automated text analysis using network techniques.
There is growing interest in automated detection of latent themes in unstructured text data. Though topic models have become a popular choice for such tasks, the textnets package provides an alternative technique that synthesizes recent advances in network analysis/graph theory and natural language processing which has several significant advantages over conventional "bag of words" models.
Though network analysis is often used to describe relationships between people-- particularly within the social sciences-- it can also be applied to relationships between words. For example, network ties can be created by the co-occurence of individual words across documents, or ties can be created between documents themselves using a two-mode network projection.
The advantage of a network-based approach to automated text analysis are a) like social groups, the meaning of groups of words can be more accurately measured through triadic closure-- or the principle that the meaning of any two words or terms to each other can be more accurately understood if they are placed in the context of a third word; b) text networks can be applied to documents of any length unlike topic models which generally require a significant amount of words to function well. This is a significant advantage in an age where short social media texts are becoming pervasive. Finally, c) this approach benefits from recent advances in the interdisciplinary literature on community detection, which arguably provides more accurate ways of grouping words that benefit from clustering observed within networks as opposed to bag of words models. These advantages are further described in the articles referenced below.
Though the idea to think about texts as networks of words is not entirely new, advances in Natural Language Processing and community detection analysis have pushed things forward. The textnets package is an attempt to make these innovations widely accessible, and to encourage others to innovate further. The textnets package provides functions performing the following tasks:
- preparing texts
- creating text networks
- visualizing text networks
- detecting themes within text networks
The most current version of the textnets package is currently available on Github. Therefore to install textnets, the devtools package must also be installed.
install.packages("devtools")
library(devtools)
install_github("cbail/textnets")
library(textnets)Before we move on to a working example, it's important to note that the textnet package constructs two-mode networks out of texts, also known as affiliation or bipartite networks. Such networks include two sets of nodes, with edges drawn only between nodes of different sets. To clarify this concept, let's take the example of a network where the first node set is words found in US newspaper headlines on the day of the first moon landing (July 20, 1969), and the second node set is the newspapers themselves. The data would look something like this:
Here is a two-mode projection of this network. As you can see, edges are only drawn between newspapers and words (i.e. nodes belonging to different sets).
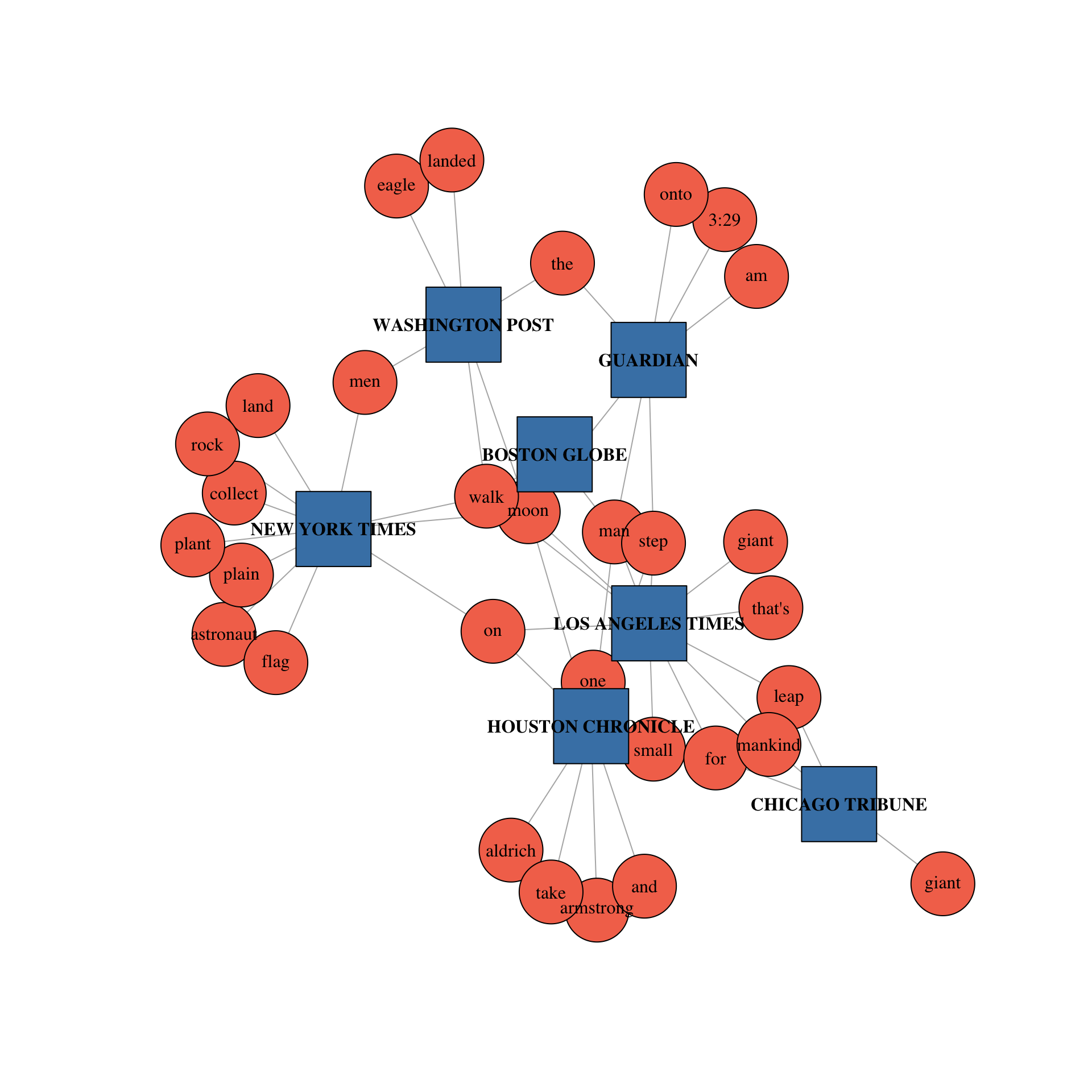
With some reshaping of the data, this two-mode network can be projected in either of its one-mode forms. That is, with either words connected through the newspapers they share in common, or with newspapers connected through the words they share in common. Importantly, these two projections represent the node_type="words" and node_type="groups" parameter settings respectively, which are specified in the PrepText function described further below.

When you're using textnets, one node set will always be comprised of the words found in the documents analyzed; the other node set can be the documents themselves, or some meta data about those documents, such as the authors, publishers, dates, etc.
The textnets package requires input to be formatted as a dataframe, where each row represents a document. The text of each document is contained in a column, with other columns including meta data. To get a better sense of this, let's take a look at some sample data that are included with the textnets package called sotu. You can load these data into your rStudio session as follows:
data("sotu")If you browse these data, you will see that it includes all texts from The State of the Union Address, which is a speech given by the president of the United States each year to describe past accomplishments and future challenges facing the nation. It is a popular dataset in the field of Natural Language Processing because it provides a diverse range of language by different individuals over time. For our purposes, the data are ideal because they contain the transcript text for every State of the Union address, as well as meta data describing the president who delivered the address, the date of delivery, and the president's party affiliation.
The textnet package includes two functions to prepare texts for analysis. You will choose one or the other for your analysis. The PrepText function prepares texts for networks based solely on word co-occurence, while PrepTextSent (available in the development folder and not automatically loaded with the package yet) prepares text for networks using word co-occurences and sentiment analysis of sentences containing the words. While PrepText defaults to preparing texts for networks using all parts of speech, it can also be limited to nouns and noun compounds. Users may prefer to create networks based on only nouns and noun compounds because previous studies have shown that such parts of speech are more useful in mapping the topical content of a text than other parts of speech, such as verbs or adjectives (e.g. Rule, Cointet, and Bearman 2015).
Let's begin with the PrepText function. This function has three required arguments: (1) textdata, a dataframe containing the texts to be analyzed and at least one additional column containing groups; (2) textvar, the name of the column containing the texts as a string; (3) groupvar, the name of the column containing the the groups through which the words of those texts will be linked as a string. For example, the latter could contain unique document ids, if the user would like to link words co-occurring within documents, or it could be author ids, if the user would like to link words co-occurring by authors, etc. In network analysis terminology, the textvar and the groupvar are specifying the nodes sets of a two-mode network.
Additionally, the PrepText function takes eight optional arguments which control the exact way the text is processed. First, users should specify which type of two-mode network projection they are interested in using the node_type argument. node_type = "words" prepares texts for a network in which words will be the nodes (with edges to each other based on co-appearance in the same group) and node_type = "groups" prepares data for a network with groups as nodes (with edges based on overlap in words between the groups). An example of the former application is Rule, Cointet, and Bearman (2015), and an example of the latter application is Bail (2016).
The other optional arguments are (1) tokenizer which controls how words are divided into unit of analysis and allows accurate tokenization of Twitter texts including mentions (@) and hashtags (#) with the specification tokenizer = "tweets"; (2) pos which controls whether all parts of speech (pos = "all") or just nouns and noun compouns should be returned (pos = "nouns"); (3) language which controls the language for part-of-speech tagging and the stop word lexicon; (4) udmodel_lang which allows users to pass a previously loaded udpipe model to the function; and (5-7) a set of control arguments specifying whether stop words, i.e. very common nouns such as "and", "the", "a", in English, should be removed (remove_stop_words), whether numeric tokens should be deleted (remove_numbers); for tokenizer = "tweets" only), and whether compound nouns should be identified and returned (compound_nouns). The function also allows to pass arguments to the specific tokenizer backend, such as strip_numeric for tokenizer = "words" or strip_url for tokenizer = "tweets".
The output of the PrepText function is a dataframe in "tidytext" style, where each row of the dataframe describes a word, the document that it appears in, and its overall frequency within that document. The dataframe returned by PrepTextSent additionally contains a column containing the median of the sum of the sentiments in the sentences containing each word.
The following code prepares the first State of the Union address for each president, specifying that nodes will be the group of presidents, with edges drawn according to the overlap of words used in their speeches. In this example we also remove stop words and return noun compounds. Since part-of-speech tagging is a lengthy process, we are only using the first speech for each president to simply our working example:
sotu_firsts <- sotu %>% group_by(president) %>% slice(1L)On a 2017 MacBook Pro (with a 2.3 GHz i5 & 8 GB ram), the code below a little less than five minutes to run.
sotu_firsts_nouns <- PrepText(sotu_firsts, groupvar = "president", textvar = "sotu_text", node_type = "groups", tokenizer = "words", pos = "nouns", remove_stop_words = TRUE, compound_nouns = TRUE)
The syntax for using the PrepTextSent function is the same as the PrepText function with the difference that by default only nouns and noun compounds are returned and users need to specify the sentiment lexicon they would like to use sentiment_lexicon = c("afinn", "bing"). Since the PrepTextSent function needs to perform both part of speech tagging and dependency parsing, it will be marginally slower than PrepText. The amount of time will depend on both the number and the length of texts. But users may conclude that the added time is worth it if they believe that positions on issues as expressed through positive and negative sentiment might reveal clustering among documents debating the same issues.
sotu_firsts_sentiment <- PrepTextSent(sotu_firsts, groupvar = "president", textvar = "sotu_text", node_type = "groups",
tokenizer = "words", sentiment_lexicon = "afinn", language = "english", udmodel_lang = udmodel_lang, remove_numbers = NULL, compound_nouns = TRUE)The workhorse function within the textnets package is the CreateTextnet function. This function reads in an object created using the PrepText or PrepTextSent functions and outputs an igraph object based on a weighted adjacency matrix, or a square matrix where the rows and columns correspond to either the groups of the group variable (if the user specificed node_type = "groups" in the previous stage), or words (if the user specified node_type = "words"). The cells of the adjacency matrix are the transposed crossproduce of the term-frequency inverse-document frequency (TFIDF) for overlapping terms between two documents for PrepText and the matrix product of TFIDF crosspropduct and sentiment score crossproduct for PrepTextSent. The first is similar to the procedure described in Bail (2016).
sotu_firsts_network <- CreateTextnet(sotu_firsts_nouns)The textnets package includes two functions to visualize text networks created in the previous steps. The VisualizeText function creates a network diagram where nodes are colored by their cluster or modularity class (see previous section). In many cases, text networks will be very dense (that is, there will be a very large number of edges because most documents share at least one word). Visualizing text networks therefore creates inherent challenges, because such dense networks are very cluttered. To make text networks more readable, the VisTextNet function employs a "network backbone" technique which deletes edges using a disparity filter algorithm to trim edges that are not informative. By default, the function uses a tuning parameter called alpha which is set to .25. The user can specify different levels of alpha to trim more or less of the network. The VisTextNet function also includes an argument that determines which nodes will be labeled, since network visualizations with too many node labels can be difficult to interpret. The user specifies an argument called label_degree_cut which specifies the degree, or number of connections, that nodes should have to get labeled. For example, if the user only wants nodes that have at least 0 connections to other nodes to be labeled, they would use the following code:
VisTextNet(sotu_firsts_network, label_degree_cut = 0)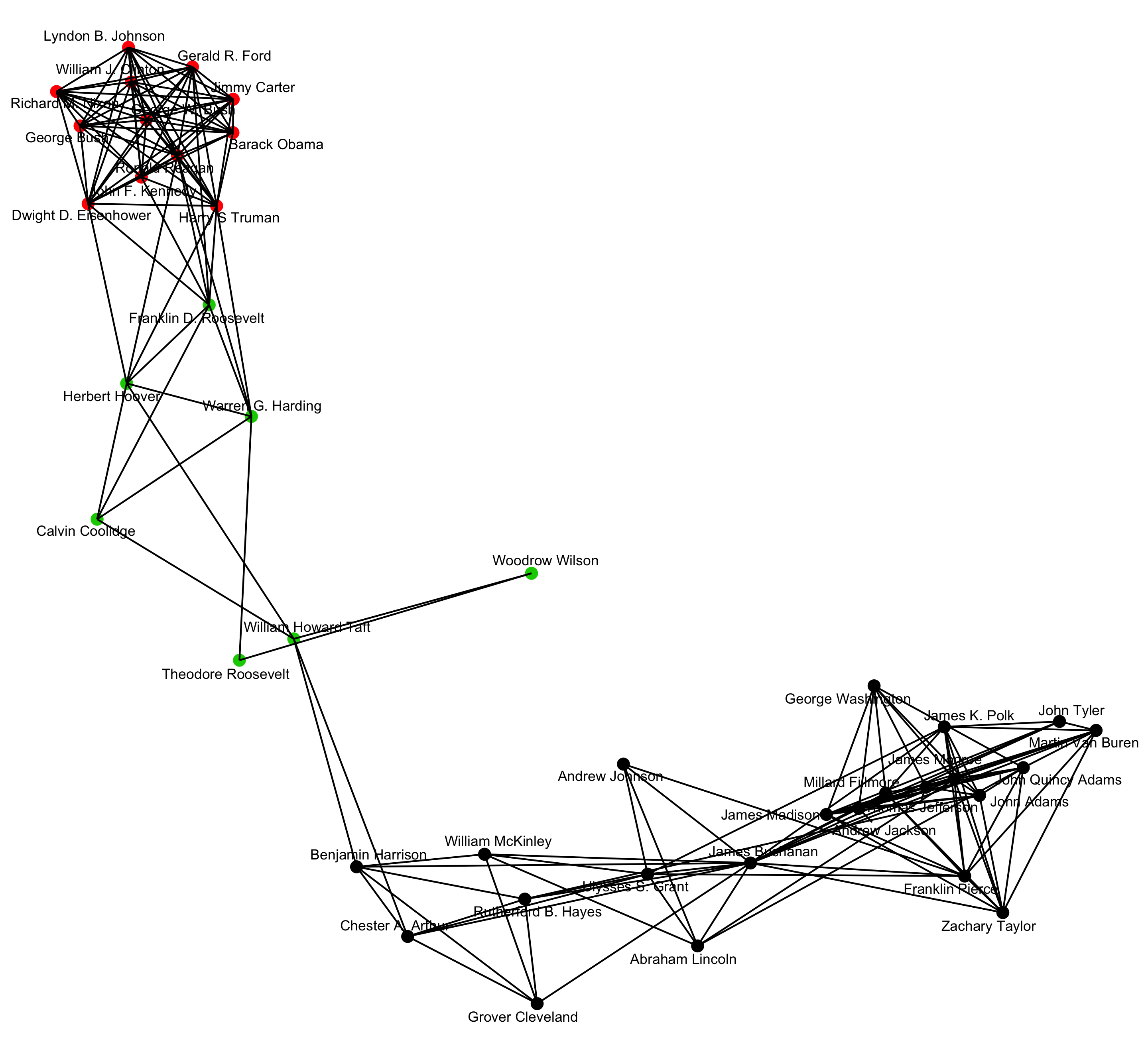
The user can also specify whether nodes should be sized according to their betweenness centrality using the betweenness=TRUE argument. For more details about why a researcher might want to do this see the section entitled "Centrality Measures" below.
The second visualization function in the textnets package is the VisTextNetD3 function. This function outputs an interactive javascript visualization of the text network, where the user can mouse over each node in order to reveal its node label. Once again, nodes are coloured by their modularity class.
VisTextNetD3(sotu_firsts_network)To save this as an html file for sharing with others or in a presentation, the following can be used. The height and width parameters are set in pixels, and bound=TRUE will prevent the network from dispersing beyond these dimensions. While this may help viewers to see all nodes, it will also cause nodes to cluster at the limits of height and wigth. This can be prevented by increasing the charge parameters, which specifies the strength of node repulsion (negative value) or attraction (positive value). The zoom parameter indicates whether to allow users to zoom in and out of the network, which can be especially helpful in large networks for exploring clusters.
In order to save this interative visualization as a .html file, users can use the htmlwidgets package as follows:
library(htmlwidgets)
vis <- VisTextNetD3(sotu_firsts_network,
height=1000,
width=1400,
bound=FALSE,
zoom=TRUE,
charge=-30)
saveWidget(vis, "sotu_textnet.html")
In order to group documents according to their similarity-- or in order to identify latent themes across texts-- users may wish to cluster documents or words within text networks. The TextCommunities function applies the Louvain community detection algorithm to do this, which automatically uses the edge weights and determines the number of clusters within a given network. The function outputs a dataframe with the cluster or "modularity" class to which each document or word has been assigned.
sotu_firsts_communities <- TextCommunities(sotu_firsts_network)In order to further understand which terms are driving the clustering of documents or words, the user can use the InterpretText function, which also reads in an object created by the CreateTextnet function and outputs the words with the 10 highest TFIDF frequencies within each cluster or modularity class. In order to match words, the function requires that the user specify the name of the text data frame object used to create the text network-- in this case sotu_text_data (see above).
top_words_modularity_classes <- InterpretText(sotu_firsts_network, sotu_firsts_nouns)Often in social networks, researchers wish to calculate measures of influence or centrality in order to predict whether or not occupying brokerage positions can create greater social rewards for individuals. As Bail (2016) shows, the same logic can be applied to text networks to develop a measure of "cultural betweenness" or the extent to which a given document or word is between clusters. To calculate cultural betweennes as well as other centrality measures, textnet users can use the TextCentrality function.
text_centrality <- TextCentrality(sotu_firsts_network)Bail, Christopher A. 2016. "Combining Network Analysis and Natural Language Processing to Examine how Ad- vocacy Organizations Stimulate Conversation on Social Media." Proceedings of the National Academy of Sciences, 113:42 11823-11828
Rule, Alix and Jean-Philippe Cointet and Peter Bearman. 2015. "Lexical shifts, substantive changes, and continuity in the State of the Union Discourse, 1790-2014.