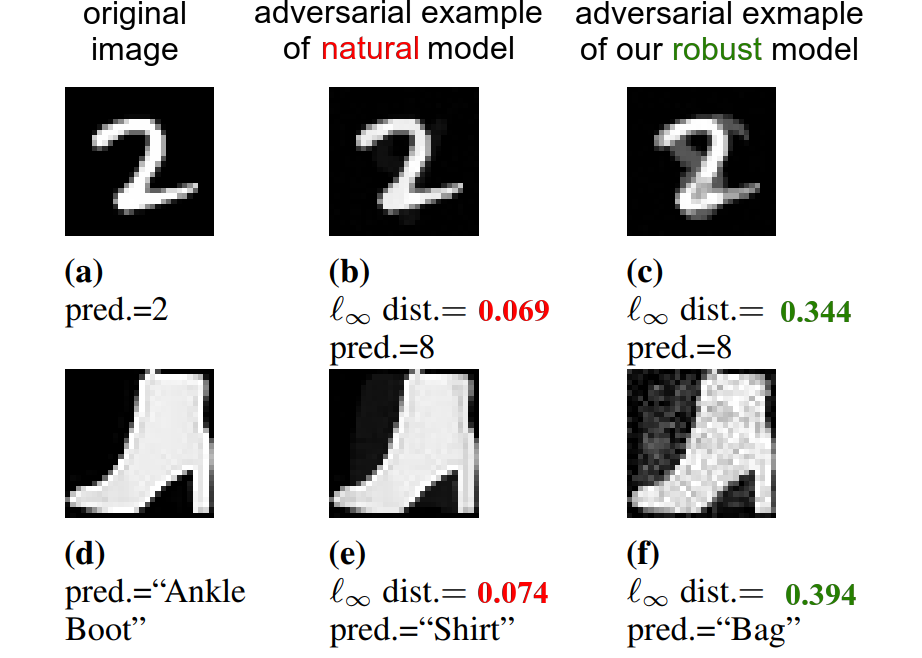
We developed a novel algorithm to train robust decision tree based models (notably, Gradient Boosted Decision Tree). This repo contains our implementation under the XGBoost framework. We plan to merge robust training as a feature to XGBoost upstream in near future.
Please refer to our paper for more details on the proposed algorithm:
Hongge Chen, Huan Zhang, Duane Boning, and Cho-Jui Hsieh "Robust Decision Trees Against Adversarial Examples", ICML 2019 [video of the talk] [slides] [poster]
We also provide our implementation of an attack proposed in Kantchelian et al. ICML 2016 to test the robustness of a GBDT model. This method uses Mixed Integer Linear Programming (MILP) to find the exact minimum adversarial example.
Sep 4, 2019: Checkout our new tree ensemble verification method in NeurIPS 2019! It is much faster and very tight compared to MILP. [GitHub] [paper]
Clone this repo and compile it:
git clone --recursive https://github.com/chenhongge/RobustTrees.git
cd RobustTrees
./build.sh
For detailed compilation options please refer to XGBoost Documentation. For building Python package interface, see these instructions.
Since our code is based on XGBoost with the addition of robust training, the interface is exactly the same as XGBoost. We use the same configuration file format as in XGBoost. To run a configuration file to train your model, simply run
./xgboost <configuration file>
In data/ folder we provide some example configuration files to start with.
See section download the dataset to download the
required datasets. For example, to train a 200-tree MNIST model with depth 8
and epsilon 0.3, just run
./xgboost data/ori_mnist.conf
Configuration files with .unrob use natural training and those without
.unrob use our proposed robust training. In natural training, the
tree_method parameter is set as exact.
We added two additional parameters to XGBoost:
(1) tree_method controls which training method to use. We add a new
option robust_exact for this parameter. Setting tree_method = robust_exact will use our proposed robust training. For other training
methods, please refer to XGBoost
documentation.
(2) robust_eps is the L inifity perturbation norm (epsilon) used in
training. Since the same epsilon value will be applied for all features, it
is recommended to normalize your data (e.g., make sure all features are in
range 0 - 1). Normalization will not change tree performance
Please refer to XGBoost Documentation for all other parameters used in XGBoost.
XGBoost treats all missing feature values in LIBSVM input file as actually
"missing" and deals with them specially to improve accuracy. But in our robust
training setting, we assume no missing values, since a perturbation from
"missing" to a certain epsilon value is not clearly defined. To workaround
this issue, it is suggested to manually add 0 back for all missing values in
LIBSVM input so that XGBoost treats them as 0 values rather than missing values.
Otherwise, when evaluating robustness, if a model is trained on datasets with
missing values and tested on a point with missing feature values, that missing
feature should not be perturbed in an attack.
Note that in the original LIBSVM format, missing features values are defined as 0. Applying the workaround above will need to explicitly write 0 features in LIBSVM input. We will add an option to provide a cleaner fix to this issue in a future release.
First download the datasets. We normalized all feature values to [0,1] already.
cd data
./download_data.shYou may also run each line of download_data.sh to download each
individual dataset. The datasets are in LIBSVM format.
Now just run each configuration file to train models, for example:
# train a robust MNIST model, epsilon is set to 0.3 in conf file
./xgboost data/ori_mnist.conf
# train a natural MNIST model
./xgboost data/ori_mnist.unrob.confHere we provide our implementation of an attack proposed in Kantchelian et al. ICML 2016 to test the robustness of a GBDT model. This method uses Mixed Integer Linear Programming (MILP) to find the exact minimum adversarial example. The formulation in the original paper can only handle binary classification models. We generalized this formulation to multi-class models by targeting all classes other than the predicted one.
This code uses Gurobi to solve the MILP problem and is tested in Python 3.6.8. We suggest to use Conda to manage your Python environments. The following packages need to be installed:
# just install the original XGBoost
conda install -c conda-forge xgboost
conda install -c gurobi gurobi
conda install -c anaconda scipy
conda install -c anaconda scikit-learn
conda install -c anaconda numpy After training, you will get a .model file. We provide robust and natural 200-tree MNIST models in mnist_models/. To run the attack, simply do
python xgbKantchelianAttack.py -d=<path to data> -m=<path to the model> -c=<number of classes>
Some datasets' LIBSVM may index the features starting from 0, such as HIGGS and
cod-rna. If that is the case, add a parameter --feature_start=0.
You can also use -o=<which point to start>, -n=<how many point to be attacked> to choose the points you want to attack.
In Kantchelian et al.'s algorithm, a guard value is used, which can be
specified with --guard_val=<guard value>. You may also round the
threshold values in the model to certain number of digits by setting
--round_digits=<number of digits>.
For example, to run attack on trained MNIST models in the previous step, download MNIST data and run:
# attack robust MNIST model
python xgbKantchelianAttack.py -d=data/ori_mnist.test0 -m=mnist_models/robust_mnist_0200.model -c=10
# attack natural MNIST model
python xgbKantchelianAttack.py -d=data/ori_mnist.test0 -m=mnist_models/natural_mnist_0200.model -c=10The output of the script will give us average Linf distortion and running time over all examples.
This implemetation of Kantchelian's attack is based on the .json model file
dumped by XGBoost. XGBoost can only offer precision up to 8 digits, but the
minimum difference between two nodes' thresholds in the json file can be
smaller than 1e-8 (due to floating-point error in dump). Here rounding may be
an option, but it may be tricky to choose guard value after rounding. For
example, if we round thresholds to 1e-6, then guard value should be at least
less than 5e-7 to avoid mistake. If we do not round thresholds, XGBoost's
predict() may give wrong results on some adversarial examples. Those
adversarial examples are perturbed across the thresholds, but since the
perturbation is so small, in XGBoost's predict(), the perturbation fails to
misclassify. Therefore, we add a manual predict function to give output based
on the .json tree file produced by XGBoost. This manual prediction should
always work.