DAG #523
DAG #523
Conversation
stacker/dag/__init__.py
Outdated
|
|
||
| def add_node(self, node_name, graph=None): | ||
| """ Add a node if it does not exist yet, or error out. """ | ||
| if not graph: |
There was a problem hiding this comment.
Do you have any idea why this library does this so often? I haven't seen this pattern used really ever before. I thought maybe for testing, but it seems like a messy way to handle that.
There was a problem hiding this comment.
No clue. It seems unnecessary. I'll try to add a commit that removes this.
There was a problem hiding this comment.
Thanks, yeah, I couldn't figure it out - I thought it'd be a test thing, but just now looking at tests I don't think it is. Strange.
stacker/dag/__init__.py
Outdated
| raise KeyError('node %s does not exist' % dep_node) | ||
| test_graph = deepcopy(graph) | ||
| test_graph[ind_node].add(dep_node) | ||
| is_valid, message = self.validate(test_graph) |
There was a problem hiding this comment.
It seems like the validate method should throw the exception itself, and have anything that calls it deal with the results if they want to catch them.
stacker/dag/__init__.py
Outdated
| if not graph: | ||
| graph = self.graph | ||
| if dep_node not in graph.get(ind_node, []): | ||
| raise KeyError('this edge does not exist in graph') |
There was a problem hiding this comment.
Can you add more info to this exception? I actually think his overuse of KeyError, instead of custom Exceptions, is a little sloppy. In any case, I think it's going to be necessary to at least have the two nodes in the exception, so we have a useful error message.
stacker/dag/__init__.py
Outdated
| graph = self.graph | ||
| return [key for key in graph if node in graph[key]] | ||
|
|
||
| def downstream(self, node, graph=None): |
There was a problem hiding this comment.
descendants maybe to match predecessors more?
When I was cleaning this up I called them: ancestors (recursive parents) and descendants (recursive children) - I also had children and parents, as well as properties for has_children, has_descendants, etc. has_children and has_descendants were both the same call, because you couldn't have descendants if you didn't have children.
There was a problem hiding this comment.
Oh, sorry, this is what I woul dhave called children - all_downstream is what I would have called descendants
stacker/dag/__init__.py
Outdated
|
|
||
| # Now, rebuild the graph for each node that's present. | ||
| for node, edges in graph.items(): | ||
| if node in dag.graph: |
There was a problem hiding this comment.
This if seems dangerous, since we silently throw away any nodes that aren't in dag.graph, which really shouldn't ever happen, right?
There was a problem hiding this comment.
That's what should happen. It's iterating through the full graph of nodes, and only re-adding edges for nodes that exist in the filtered graph.
There was a problem hiding this comment.
Ahh, my bad - mixing dag & graph in this method made it confusing. Maybe having it be original_graph and filtered_graph would make it less confusing. Not a huge deal for now.
stacker/dag/__init__.py
Outdated
| if graph is None: | ||
| graph = self.graph | ||
|
|
||
| dependent_nodes = set( |
There was a problem hiding this comment.
I'm having a really hard time reading this - any way to dumb it down that isn't going to destroy performance?
stacker/dag/__init__.py
Outdated
| else: | ||
| raise ValueError('graph is not acyclic') | ||
|
|
||
| def size(self): |
There was a problem hiding this comment.
You could also give this class a __len__ method so that calling len() on it would return the size.
stacker/exceptions.py
Outdated
| self.stack = stack | ||
| self.dependency = dependency | ||
| self.exception = exception | ||
| message = ("Error detected when adding '%s' " |
There was a problem hiding this comment.
This message will be broken if stack & dependency aren't set.
There was a problem hiding this comment.
Where this is used, those things are never not present.
There was a problem hiding this comment.
Cool - you should make them required then, so we don't hit an edge case.
| return graph | ||
|
|
||
|
|
||
| class Graph(object): |
There was a problem hiding this comment.
Curious if this should just be combined with the Plan class?
There was a problem hiding this comment.
I originally started with that, but I think it's cleaner to keep these things separate:
Graphencapsulates a graph ofStepobjects, and has operations to make working on the graph itself easy (transposition, walking, etc).Planis more like a convenience class for Actions to consume (dump, outline, etc).
Plan could probably eventually get removed, as most of the methods on it may be better somewhere else, but I primarily kept it around to keep API compatibility with the existing Plan implementation.
stacker/plan2.py
Outdated
| return self.step_names | ||
|
|
||
|
|
||
| class UnlimitedSemaphore(object): |
There was a problem hiding this comment.
Is this just planning ahead for multi-process/threading?
There was a problem hiding this comment.
Yeah, this is leftover from multi-threading. I'll remove this since it's unnecessary right now.
Codecov Report
@@ Coverage Diff @@
## master #523 +/- ##
==========================================
+ Coverage 88.72% 89.14% +0.41%
==========================================
Files 92 96 +4
Lines 5926 6401 +475
==========================================
+ Hits 5258 5706 +448
- Misses 668 695 +27
Continue to review full report at Codecov.
|

|
Functional tests are all passing, so the only next steps to get this mergeable should be:
|
1fba1c8
to
f9ba218
Compare
|
@phobologic when you wanna review this, this should be 100% feature complete and pretty close to being mergeable. A lot of your original comments were around the implementation of |
|
A few of my comments are around things that look dangerous or error prone (duplicate key comment, the comment about ignoring mising edges)- if you think they aren't and can explain it, I'd be fine ignoring those. Others are just from general usefulness. Better errors, easier to read code, etc. I'm fine with skipping the stuff about children/descendants, since I know that's mostly just graph theory terms being used instead. All in all, I'll take a small performance hit if it means better maintainability in the future. That said, I don't expect my suggestions/questions to actually result in much of a hit at the scale we're operating and due to the fact that most of the time is spent in talking with AWS. I think we should go ahead and vendor - though we should give the Author credit at the top of the code most likely. Ok, now going to review the latest. |
stacker/__init__.py
Outdated
| tail=None, | ||
| stacks=None, stack_names=None, | ||
| reverse=False): | ||
| """A simple helper that builds a graph based plan from a set of stacks.""" |
There was a problem hiding this comment.
Can you do the full Args/Returns docstring here? Also, is plan a temporary thing until we remove the old plan?
stacker/plan2.py
Outdated
|
|
||
| def build_plan(description=None, steps=None, | ||
| step_names=None, reverse=False): | ||
| graph = build_graph(steps) |
There was a problem hiding this comment.
if steps is None, it'll break build_graph. Not sure what the right behavior should be.
There was a problem hiding this comment.
I can't think of a scenario where that could actually happen from the stacker CLI, since there's config validation to ensure that stacks isn't empty, but I'll add a test for that here.
|
|
||
| class Step(object): | ||
| """State machine for executing generic actions related to stacks. | ||
| Args: |
stacker/plan2.py
Outdated
| with this step | ||
| """ | ||
|
|
||
| def __init__(self, stack, fn=None, watch_func=None, |
There was a problem hiding this comment.
Is fn really optional at this point?
stacker/plan2.py
Outdated
| self.set_status(SUBMITTED) | ||
|
|
||
|
|
||
| def build_plan(description=None, steps=None, |
There was a problem hiding this comment.
description seems like it should be required, as well as steps?
stacker/tests/test_plan2.py
Outdated
|
|
||
| plan = build_plan(description="Test", steps=[Step(vpc), Step(bastion)]) | ||
|
|
||
| self.assertEqual(plan.graph.dag.graph, { |
There was a problem hiding this comment.
These kind of lines are part of my concern with having a separate graph class. It's a little confusing. Probably not a huge deal, just not straight forward.
There was a problem hiding this comment.
This is really just a bad test on my part. dag should be private within the Graph class, but no way to enforce that with python :(.
I'll add a to_dict method to Graph, to make testing this cleaner.
There was a problem hiding this comment.
Cool - I also just realized the name of this test is probably wrong.
| def walk(self): | ||
| """Walks each step in the underlying graph, in topological order.""" | ||
|
|
||
| def walk_func(step): |
There was a problem hiding this comment.
We should probably do something here to catch any errors that are raised, and prepend/append info about what step caused the issue - either here or on Graph.
There was a problem hiding this comment.
I think we definitely should make that change, since it's annoying when a stack throws an exception, and you have no context about what stack has the issue. But we should probably make that change separate from this PR, since that's not existing behavior.
We'll also need to think about how we handle exceptions in a parallelized world, since the current method of just throwing an exception and aborting won't work with multi-threads/processes.
| build_plan( | ||
| description="Test", | ||
| steps=[Step(vpc, None), Step(db, None), Step(app, None)]) | ||
| message = ("Error detected when adding 'namespace-db.1' " |
There was a problem hiding this comment.
You know, you probably wouldn't need this message test if we had different exceptions ;) Just saying.
tests/suite.bats
Outdated
| @@ -629,10 +629,7 @@ EOF | |||
| assert "$status" -eq 1 | |||
There was a problem hiding this comment.
Curious why we removed the asserts here?
There was a problem hiding this comment.
In the implementation in this PR, if a node in the graph fails (returns False), the entire graph walk will halt. It's not actually necessary to halt the entire graph walk, only nodes that depend on the failed node. I can update the implementation of the graph walk to support the old behavior.
stacker/__init__.py
Outdated
| __version__ = "1.1.4" | ||
|
|
||
|
|
||
| def plan(description=None, action=None, |
There was a problem hiding this comment.
What's the plan going forward with this? We probably can't name this function "plan" if we move plan2 to plan.
There was a problem hiding this comment.
The plan (no pun intended) would be to replace plan.py with plan2.py before merging, unless we want to keep the original plan.py around for backwards compatibility. I only went with plan2.py because overwriting plan.py in the PR would make reviewing it pretty hard, since it's a re-write.
There was a problem hiding this comment.
Right, but what about the plan method? If you have a plan method in stacker/__init__.py and a stacker/plan directory, you're going to have conflicts when someone does something like: from stacker import plan or from stacker.plan import * (maybe not on the last one, I honestly don't know!)
There was a problem hiding this comment.
Ah, gotcha. I think this plan method should actually be moved to stacker.actions.base, since that's where it's intended to be used.
|
Alright @phobologic. I think I've addressed a majority of the comments here. I also reverted back to the original behavior for failed child stacks, so that the entire graph of stacks is executed, but a given stack will not execute if any of it's dependencies are in a "not ok" state (see c0f3714) |
|
@Lowercases found a bug where |
| description (str): a description of the plan. | ||
| action (func): a function to call for each stack. | ||
| stacks (list): a list of :class:`stacker.stack.Stack` objects to build. | ||
| targets (list): an optional list of targets to filter the graph to. |
There was a problem hiding this comment.
You're right, targets is definitely a better name for this. Thanks for thinking of that.
|
|
||
|
|
||
| class Graph(object): | ||
| """Graph represents a graph of steps. |
There was a problem hiding this comment.
This is super helpful - thanks!
|
Cool. I'll update us internally to run this branch before merging. |
|
There's some talk about whether or not the Let's say you have a graph of stacks like the following: In the current behavior (this pr), if you specify If there's a change to the We could change the behavior here so that the graph includes the dependencies of In some configurations, this could easily blow up the size of the graph (e.g. if a parent also depends on a bunch of stacks), but makes it more "correct". |
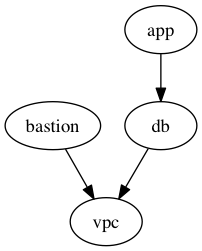
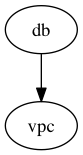
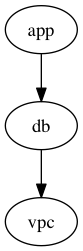
|
Personally, the expected behavior of the |
|
The version is this PR is I would prefer correctness over speed. I like @acmcelwee point, if we can support both, ( |
|
Yeah, that makes sense to me. I think I'll update this PR to the more complete version. If there's a need for the old behavior, we can add new flags for that. |
|
Aaaaand...I think I'm gonna flipflop my preference back to the fast version. I tried the complete version internally, and it's pretty easy for the graph to explode making I'll leave out specific stack names, but on our internal graph, when I targeted a stack that builds out an ECS cluster, the fast versions results in 4 stacks (3 dependencies). With the full version, the graph explodes to 100 stacks as a result of the parents transitive dependencies. |
This changes the internals of stacker plan's to first generate a Directed Acyclic Graph, and uses this as a means of walking the graph.
|
Thanks everyone for the comments and feedback. Super excited about what this is gonna enable for stacker moving forward. |
Generate a DAG internally
Third times the charm :)
Fixes #300
Fixes #186
Fixes #384
This is an internal refactor to change the Plan implementation to be backed by a Directed Acyclic Graph. Most of this work was already done a long time ago in #406, but this just brings it up to speed with the master branch, with a few important caveats:
Not parallelized
This implementation is not parallelized. This PR paves the way to make it easy to implement a 100% parallelized graph walk, but I didn't implement it here, primarily to make review easier, but also because it doesn't matter much based on the current implementation (more on that below). I think we should get the graph in
master, and then add a parallelized walk after the fact since that will need special attention to deal with concurrency issues (logging, user input, etc).In theory, this sounds like it should reduce performance, but ironically it has little impact. I benchmarked before and after on our internal stacker graph, which is pretty big:
before (stacker 1.1.3)
after (dag)
However, because the
--stacksflag now works like you'd expect it to, this branch can actually make most workflows a lot faster, even without concurrency.Notes for reviewer
For the time being, I'd like to focus on functionality, and making sure everything is feature complete, and all of the integration tests pass. There's probably some missing doc's, and I'll get to those things later.
Also, to make review easier, instead of making changes to
stacker.planI made a newstacker.plan2, and swapped out call sites to use the new graph based plan implementation. This will likely replacestacker.planbefore merging, unless we want to keep the oldstacker.planaround for API compatibility.The
stacker.dagmodule probably doesn't need much attention, since it's already been reviewed previously, and is stilled based onpy-dag. Feel free to review it if you want.TODO
--tailflag.