I stumbled across this repository one day and was enthralled in reading the many topics and following the guides. Unfortunately, it is a lot simpler to read someone else's blog and follow along than it is to actually build a lot of the programs they describe. So I am writing my own guide on something that I will be building and researching myself from (almost) scratch. If you enjoy this project or others linked to above, I would strongly encourage you to try and build your own.
you will need only a little of the following:
- curiosity
- programming experience
- a c compiler
this is not a beginners' guide on c. Though I may explain functions that some may see as basic, you should have a decent handle on how to write a program in at least one programming language, if not c itself. That said, everything you don't understand can easily be learned through the use of search engines.
The zip format was designed to make it easy to compress and write and decompress and read individual files bundled together. The file structure makes this clear.
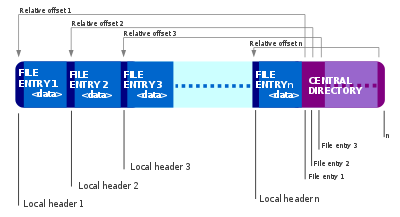
A directory describing each entry is appended to the end of the record, which describes the properties of each file and its location. This makes appending new files to an existing zip file by simply replacing the central directory with the new file followed by a new central directory. This also allows the contents and properties of the zip file to be read without extracting any data.
Read through the design section of the wikipedia page for more information and a general understanding of what we're going to be doing.
First things first, we should probably mirror the functionality of the unzip
utility, since that's what we're trying to build.
unzip takes a zip file as an argument and gently informs you when you don't
give it exactly that, so our first step will be implementing a simple program
just like so:
#include <stdio.h>
int main(int argc, char** argv) {
if (argc != 2) {
// not exactly two arguments
printf("usage: %s file[.zip]\n",argv[0]);
return 1;
// return with error code
}
FILE *input = fopen(argv[1], "rb"); // open the argument file
if (!input) {
printf("cannot open file %s\n", argv[1]);
return 1;
}
fclose(input); // don't forget to close the file
return 0;
}Now that we have a body, the first thing we need do is find the central directory. All we really need to do for this is go to the end of the file minus the number of bytes in the directory, right? Except since there's really no limit on the number of files included in a zip archive so the central directory could really be as long as we wanted, which makes this a little more difficult.
Luckily, the end of the archive includes an 'end of central directory' entry that describes exactly where we should get started. (Actually it's by design. No luck involved.) But that's also variable length, since it can include a comment! Meaning we have no choice but to start at the back of the archive and work our way to the front, looking for the magic 'end of central directory signature', which tells us we've found what we're looking for.
We'll use int fseek(FILE *stream, long int offset, int whence) followed by
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream) in a loop
to do just that, starting with where we'd expect
the signature to be, and moving back byte by byte until we find it.
fseek(input, -22, SEEK_END); // start at 22 bytes from the back of the file
fread(&possible_sig, 4, 1, input); // read possible signature value
printf("possible_sig: %#.8x\n",possible_sig);
while (possible_sig != EOCD_SIGNATURE) {
fseek(input, -5, SEEK_CUR);
// move back 5 bytes (length of signature plus one)
fread(&possible_sig, 4, 1, input);
printf("possible_sig: %#.8x\n",possible_sig);
}You'll need to add a line defining the EOCD_SIGNATURE macro and the
uint32_t possible_sig variables in the right places as well. Go find the
magic number for the end of central directory structure in the
wikipedia page
You can now compile this program with your favorite compiler and run it on zip files you make on your very own computer! I've included some in this repository that contain some interesting books. Feel free to try them out. The first archive doesn't contain a comment, which will let you read the eocd signature on the first try. The other contains a comment, and you'll see the code search for a few bytes before successfully finding the signature.
Warning! if you are programming on a computer that uses
big-endian encoding, you will
have to reverse the endianness of the possible_sig variable or reverse the
byte order of the EOCD_SIGNATURE macro, otherwise this code will not work
properly. If you don't understand the benefits and downsides of both endian
encodings, I highly recommend it as a fun family activity for a lazy
sunday afternoon
so now that we've found our eocd entry, let's define a struct to hold that
information so we can refer back to it later. I'll start a file called
unzip.h to contain all of our structures so our unzip.c file stays
uncluttered. the struct should look like this:
#ifndef MYUNZIP_H
#define MYUNZIP_H
#include <inttypes.h>
struct eocd_record {
uint32_t signature;
uint16_t disk_num;
uint16_t central_dir_start_disk;
uint16_t num_central_dir_on_disk;
uint16_t num_central_dir_total;
uint32_t central_dir_size;
uint32_t central_dir_offset;
uint16_t comment_len;
};
#endifMake sure the field sizes are all correct. I prefer to explicitly state them
using uintxx_t. Additionally, I am against the use of typedef when it comes
to declaring a struct in c, for several reasons that are better explained in
this book,
which I recommend to anyone.
Finally, we'll read the eocd into an instance of our struct, verify the signature, and use this in the next section to start reading information about which files we have in our archive.
fseek(input, -4, SEEK_CUR); // move back to the beginning of the eocd
fread(&eocd, sizeof(struct eocd_record), 1, input);
// read the eocd
assert(eocd.signature == EOCD_SIGNATURE);
// make sure we've got the right thingMake sure to #include <assert.h> at the beginning of either your .c or .h
file and to either declare an eocd variable or make a pointer to one and
allocate enough memory to fit all of the required details.
Now that we have our end of central directory entry we can access the actual central directory entry. The central directory is simply a series of central directory file headers, one for each entry. Let's grab the first one and print the filename and some details.
First we'll need a new struct that matches the layout of the central
directory file header.
struct central_dir_file_header {
uint32_t signature;
uint16_t created_version;
uint16_t needed_version;
uint16_t flag;
uint16_t compression_method;
uint16_t last_modification_time;
uint16_t last_modification_date;
uint32_t crc32;
uint32_t compressed_size;
uint32_t uncompressed_size;
uint16_t file_name_len;
uint16_t extra_field_len;
uint16_t file_comment_len;
uint16_t file_start_disk_num;
uint16_t internal_file_attr;
uint32_t external_file_attr;
uint32_t local_file_header_offset;
};Now we'll declare one, fseek to the beginning of the central directory, and
read the first entry:
fseek(input, eocd.central_dir_offset, SEEK_SET);
// move to beginning of central directory
fread(&cdfh, sizeof(struct central_dir_file_header), 1, input);
// read first file header
assert(cdfh.signature == CDFH_SIGNATURE);
file_name = malloc(cdfh.file_name_len + 1);
fread(file_name, cdfh.file_name_len, 1, input);
// read the file name
file_name[cdfh.file_name_len] = '\0';
printf("first file is named: %s\n", file_name);The reason we allocate one extra byte is to save space for our null-terminator, and important element of cstrings you may or may not know of. Read up on them here
You should notice something a little strange when you run this latest version:
> ./myunzip books.zip
possible_sig: 0x06054b50
first file is named: ee_as_in_freedom.txt.utf-8UT?Somehow we missed the first two bytes of our book title. Feel free to try and
figure out where we went wrong by investigating all of the values of the
central directory file header and comparing them with that you'd expect them to
be. A good way to do this is using the hexdump utility with the -C flag like
so:
> hexdump -C books.zip > dump.hex(this will be faster on a smaller archive)
000ceb10 6f 93 ae 13 c6 fa ff 0f 50 4b 01 02 1e 03 14 00 |o.......PK......|
000ceb20 00 00 08 00 87 bd ed 4c e9 c8 0b 94 b9 c8 02 00 |.......L........|
000ceb30 6e 5c 07 00 1c 00 18 00 00 00 00 00 01 00 00 00 |n\..............|
000ceb40 a4 81 00 00 00 00 66 72 65 65 5f 61 73 5f 69 6e |......free_as_in|
000ceb50 5f 66 72 65 65 64 6f 6d 2e 74 78 74 2e 75 74 66 |_freedom.txt.utf|
000ceb60 2d 38 55 54 05 00 03 8d 71 49 5b 75 78 0b 00 01 |-8UT....qI[ux...|
000ceb70 04 f5 01 00 00 04 14 00 00 00 50 4b 01 02 1e 03 |..........PK....|
000ceb80 14 00 00 00 08 00 8d bd ed 4c 8d c4 7e d6 91 07 |.........L..~...|
000ceb90 04 00 94 58 0a 00 1a 00 18 00 00 00 00 00 01 00 |...X............|
You'll notice all of the values are correct until external_file_attr, which
is shifted by two bytes. The reason behind this may not be obvious, until you
realize the size of the struct we've created isn't cleanly divisible by four.
Most compilers optimize structs to align with nature memory access boundaries.
More on that here.
The aforementioned stack overflow page gives us an easy way to prevent this
behavior by simply adding __attribute__((__packed__)) to our struct
definition. Our central_dir_file_header should now look like this:
struct __attribute__((__packed__)) central_dir_file_header {
uint32_t signature;
uint16_t created_version;
uint16_t needed_version;
...
uint32_t local_file_header_offset;
};Compile and run with our new header and we should get the following:
> ./myunzip books.zip
possible_sig: 0x06054b50
first file is named: free_as_in_freedom.txt.utf-8Now that we finally have that working, let's take a look at how to find the
rest of the file headers. Each header is 46 + n + m + k bytes in length,
where n, m, and k are the lengths of the file name, extra field, and file
comment, respectively.
We already read our 46 + n bytes when we used fread to fill our
central_dir_file_header and file_name variables, meaning all we have to
do is fseek another m + k bytes and we should arrive at the next header.
fseek(input, cdfh.extra_field_len + cdfh.file_comment_len, SEEK_CUR);
// move to next cdfh
fread(&cdfh, sizeof(struct central_dir_file_header), 1, input);We can run this process in a loop until our signature value is no longer valid, meaning we've reached the end of central directory record, and the end of all of our files in the archive. It should look something like this:
while (cdfh.signature == CDFH_SIGNATURE) {
file_name = realloc(file_name, cdfh.file_name_len + 1);
// reallocate space for the new file name
fread(file_name, cdfh.file_name_len, 1, input);
// read the new file name
file_name[cdfh.file_name_len] = '\0';
// append a null-term
printf("next file is named: %s\n", file_name);
fseek(input, cdfh.extra_field_len + cdfh.file_comment_len, SEEK_CUR);
// move to the next entry
fread(&cdfh, sizeof(struct central_dir_file_header), 1, input);
// read the next entry
}Don't forget to free the file_name variable when you're done and define
the CDFH_SIGNATURE value at the top of your file.
Try out the new changes. you should get something like this:
> ./myunzip books.zip
possible_sig: 0x06054b50
first file is named: free_as_in_freedom.txt.utf-8
next file is named: hacker_crackdown.txt.utf-8
next file is named: heroes_of_the_computer_revolution.txt.utf-8
next file is named: underground.txt.utf-8To start, I wanted to reformat the code to make things a little cleaner. I started by writing a function that looks like this:
void list_contents(FILE *input, int offset);Which pretty simply takes our input zip file and an offset for our central
directory file header, and does all of the operations we talked about earlier.
Then I decided to present the information in a nice format, much like running
unzip -l books.zip does. Now my output looks like this:
> ./myunzip books.zip
length date time name
--------- ---------- -------- ----
482414 07-13-2018 23:44:07 free_as_in_freedom.txt.utf-8
678036 07-13-2018 23:44:13 hacker_crackdown.txt.utf-8
109485 07-13-2018 23:38:24 heroes_of_the_computer_revolution.txt.utf-8
949369 07-13-2018 23:43:26 underground.txt.utf-8This page helped me a bit with the time
and date, but otherwise everything is fairly straightforward. (Note: the length
attribute presented here is the uncompressed length. This should be simple to
validate against ls -l)
Now this is the real core of what I wanted to learn when I started this project. Zip files use the deflate algorithm which is comprised of two sections: LZ77 and huffman coding.
LZ77 eliminates repetitions in our source file by creating pointers to previous sections of the text instead of repeating a string of characters. (Here's a video to visualize that, by one of my favorite bloggers, Julia Evans)
Huffman coding is a method of redefining how we represent our data in binary, using shorter length codes for more frequent artifacts, and longer ones for less frequently occurring objects, which reduces the total length of our text file (or other filetypes)!
To visualize this, there's a great tool called infgen, which reads gzip, zlib, or raw deflate streams. Unfortunately the author hasn't implemented zip file support (though it's open source, so feel free!), but we have the skills and know-how to look through our zip archive and find the deflate stream for any of our files. I wrote a new function to output a deflate stream given our input file pointer and a starting offset (which we can get from our central directory file header).
// write first file deflate stream to file
fseek(input, eocd.central_dir_offset, SEEK_SET);
fread(&cdfh, sizeof(struct central_dir_file_header), 1, input);
assert(cdfh.signature == CDFH_SIGNATURE);
output_deflate(input, cdfh.local_file_header_offset);These four lines will grab the first entry in the central directory file
header, verify it is what it should be, and call our output function with
the input file pointer and the offset of our first file. Make sure the
eocd variable contains the end of central directory entry we scanned for
in section 1
Now on to the function itself! This is a pretty straightforward read and copy operation, with a little fun grabbing the included filename to name our output file accordingly. Ideally the copy should be done in batches to prevent the program from attempting to allocate too much memory, but we'll get back to that if we ever decide to use this code for anything more than learning
we're also going to need a new struct to hold our local file header, which
comes immediately before our deflate stream and holds a bit of information
regarding the data we're about to read. It looks like this:
struct __attribute__((__packed__)) local_file_header {
uint32_t signature;
uint16_t version;
uint16_t bit_flag;
uint16_t compression_method;
uint16_t last_modification_time;
uint16_t last_modification_date;
uint32_t crc32;
uint32_t compressed_size;
uint32_t uncompressed_size;
uint16_t file_name_len;
uint16_t extra_field_len;
};This struct also needs to be packed since there's an odd number of 16 bit
fields between some 32 bit fields, similar to the central directory file
header.
And our function:
void output_deflate(FILE *input, int lfh_offset) {
FILE *output;
struct local_file_header lfh;
void *data;
char *filename;
// move to the given offset
fseek(input, lfh_offset, SEEK_SET);
// read our local file header
fread(&lfh, sizeof(struct local_file_header), 1, input);
// check things are right
assert(lfh.signature == LFH_SIGNATURE);
// grab memory to store our filename
filename = malloc(lfh.file_name_len + 4);
// read the filename
fread(filename, lfh.file_name_len, 1, input);
// add our file extension and a null terminator for good measure
strcpy(filename + lfh.file_name_len, ".df\0");
// open a destination file pointer
output = fopen(filename, "wb");
// allocate memory for the deflate stream
data = malloc(lfh.compressed_size);
/* find the deflate stream (we've already read
the entire header and the filename) */
fseek(input, lfh.extra_field_len, SEEK_CUR);
// read the deflate stream
fread(data, lfh.compressed_size, 1, input);
// write the deflate stream
fwrite(data, lfh.compressed_size, 1, output);
//close the file, free our memory
fclose(output);
free(filename);
free(data);
}Now we should see a file with a .df extension when we run our program with
these new changes. Run this through infgen and look at the beginning to get
a glimpse into how the deflate algorithm is using huffman coding:
> ../infgen/infgen free_as_in_freedom.txt.utf-8.df | head
! infgen 2.4 output
!
dynamic
litlen 10 9
litlen 13 9
litlen 32 6
litlen 33 14
litlen 34 8
litlen 35 15
litlen 38 13Those first few lines tell us ascii codes followed by lengths of their
corresponding representations. For example, litlen 32 6 means ascii
code 32 (which corresponds to a space) is represented by a huffman coding
of six bits. This is cool because it tells us a bit about our source as well.
The fact that a space is represented by only six bits tells us it occurs
frequently enough to warrant cutting it down by two bits to save a bit of
space.