![]()
![]()
LangFair is a comprehensive Python library designed for conducting bias and fairness assessments of large language model (LLM) use cases. This repository includes a comprehensive framework for choosing bias and fairness metrics, along with demo notebooks and a technical playbook that discusses LLM bias and fairness risks, evaluation metrics, and best practices.
Explore our documentation site for detailed instructions on using LangFair.
Static benchmark assessments, which are typically assumed to be sufficiently representative, often fall short in capturing the risks associated with all possible use cases of LLMs. These models are increasingly used in various applications, including recommendation systems, classification, text generation, and summarization. However, evaluating these models without considering use-case-specific prompts can lead to misleading assessments of their performance, especially regarding bias and fairness risks.
LangFair addresses this gap by adopting a Bring Your Own Prompts (BYOP) approach, allowing users to tailor bias and fairness evaluations to their specific use cases. This ensures that the metrics computed reflect the true performance of the LLMs in real-world scenarios, where prompt-specific risks are critical. Additionally, LangFair's focus is on output-based metrics that are practical for governance audits and real-world testing, without needing access to internal model states.
We recommend creating a new virtual environment using venv before installing LangFair. To do so, please follow instructions here.
The latest version can be installed from PyPI:
pip install langfairBelow are code samples illustrating how to use LangFair to assess bias and fairness risks in text generation and summarization use cases. The below examples assume the user has already defined a list of prompts from their use case, prompts.
To generate responses, we can use LangFair's ResponseGenerator class. First, we must create a langchain LLM object. Below we use ChatVertexAI, but any of LangChain’s LLM classes may be used instead. Note that InMemoryRateLimiter is to used to avoid rate limit errors.
from langchain_google_vertexai import ChatVertexAI
from langchain_core.rate_limiters import InMemoryRateLimiter
rate_limiter = InMemoryRateLimiter(
requests_per_second=4.5, check_every_n_seconds=0.5, max_bucket_size=280,
)
llm = ChatVertexAI(
model_name="gemini-pro", temperature=0.3, rate_limiter=rate_limiter
)We can use ResponseGenerator.generate_responses to generate 25 responses for each prompt, as is convention for toxicity evaluation.
from langfair.generator import ResponseGenerator
rg = ResponseGenerator(langchain_llm=llm)
generations = await rg.generate_responses(prompts=prompts, count=25)
responses = [str(r) for r in generations["data"]["response"]]
duplicated_prompts = [str(r) for r in generations["data"]["prompt"]] # so prompts correspond to responsesToxicity metrics can be computed with ToxicityMetrics. Note that use of torch.device is optional and should be used if GPU is available to speed up toxicity computation.
# import torch # uncomment if GPU is available
# device = torch.device("cuda") # uncomment if GPU is available
from langfair.metrics.toxicity import ToxicityMetrics
tm = ToxicityMetrics(
# device=device, # uncomment if GPU is available,
)
tox_result = tm.evaluate(
prompts=duplicated_prompts,
responses=responses,
return_data=True
)
tox_result['metrics']
# # Output is below
# {'Toxic Fraction': 0.0004,
# 'Expected Maximum Toxicity': 0.013845130120171235,
# 'Toxicity Probability': 0.01}Stereotype metrics can be computed with StereotypeMetrics.
from langfair.metrics.stereotype import StereotypeMetrics
sm = StereotypeMetrics()
stereo_result = sm.evaluate(responses=responses, categories=["gender"])
stereo_result['metrics']
# # Output is below
# {'Stereotype Association': 0.3172750176745329,
# 'Cooccurrence Bias': 0.44766333654278373,
# 'Stereotype Fraction - gender': 0.08}We can generate counterfactual responses with CounterfactualGenerator.
from langfair.generator.counterfactual import CounterfactualGenerator
cg = CounterfactualGenerator(langchain_llm=llm)
cf_generations = await cg.generate_responses(
prompts=prompts, attribute='gender', count=25
)
male_responses = [str(r) for r in cf_generations['data']['male_response']]
female_responses = [str(r) for r in cf_generations['data']['female_response']]Counterfactual metrics can be easily computed with CounterfactualMetrics.
from langfair.metrics.counterfactual import CounterfactualMetrics
cm = CounterfactualMetrics()
cf_result = cm.evaluate(
texts1=male_responses,
texts2=female_responses,
attribute='gender'
)
cf_result
# # Output is below
# {'Cosine Similarity': 0.8318708,
# 'RougeL Similarity': 0.5195852482361165,
# 'Bleu Similarity': 0.3278433712872481,
# 'Sentiment Bias': 0.0009947145187601957}To streamline assessments for text generation and summarization use cases, the AutoEval class conducts a multi-step process that completes all of the aforementioned steps with two lines of code.
from langfair.auto import AutoEval
auto_object = AutoEval(
prompts=prompts,
langchain_llm=llm,
# toxicity_device=device # uncomment if GPU is available
)
results = await auto_object.evaluate()
results
# Output is below
# {'Toxicity': {'Toxic Fraction': 0.0004,
# 'Expected Maximum Toxicity': 0.013845130120171235,
# 'Toxicity Probability': 0.01},
# 'Stereotype': {'Stereotype Association': 0.3172750176745329,
# 'Cooccurrence Bias': 0.44766333654278373,
# 'Stereotype Fraction - gender': 0.08,
# 'Expected Maximum Stereotype - gender': 0.60355167388916,
# 'Stereotype Probability - gender': 0.27036},
# 'Counterfactual': {'male-female': {'Cosine Similarity': 0.8318708,
# 'RougeL Similarity': 0.5195852482361165,
# 'Bleu Similarity': 0.3278433712872481,
# 'Sentiment Bias': 0.0009947145187601957}}}Explore the following demo notebooks to see how to use LangFair for various bias and fairness evaluation metrics:
- Toxicity Evaluation: A notebook demonstrating toxicity metrics.
- Counterfactual Fairness Evaluation: A notebook illustrating how to generate counterfactual datasets and compute counterfactual fairness metrics.
- Stereotype Evaluation: A notebook demonstrating stereotype metrics.
- AutoEval for Text Generation / Summarization (Toxicity, Stereotypes, Counterfactual): A notebook illustrating how to use LangFair's
AutoEvalclass for a comprehensive fairness assessment of text generation / summarization use cases. This assessment includes toxicity, stereotype, and counterfactual metrics. - Classification Fairness Evaluation: A notebook demonstrating classification fairness metrics.
- Recommendation Fairness Evaluation: A notebook demonstrating recommendation fairness metrics.
Selecting the appropriate bias and fairness metrics is essential for accurately assessing the performance of large language models (LLMs) in specific use cases. Instead of attempting to compute all possible metrics, practitioners should focus on a relevant subset that aligns with their specific goals and the context of their application.
Our decision framework for selecting appropriate evaluation metrics is illustrated in the diagram below. For more details, refer to our technical playbook.
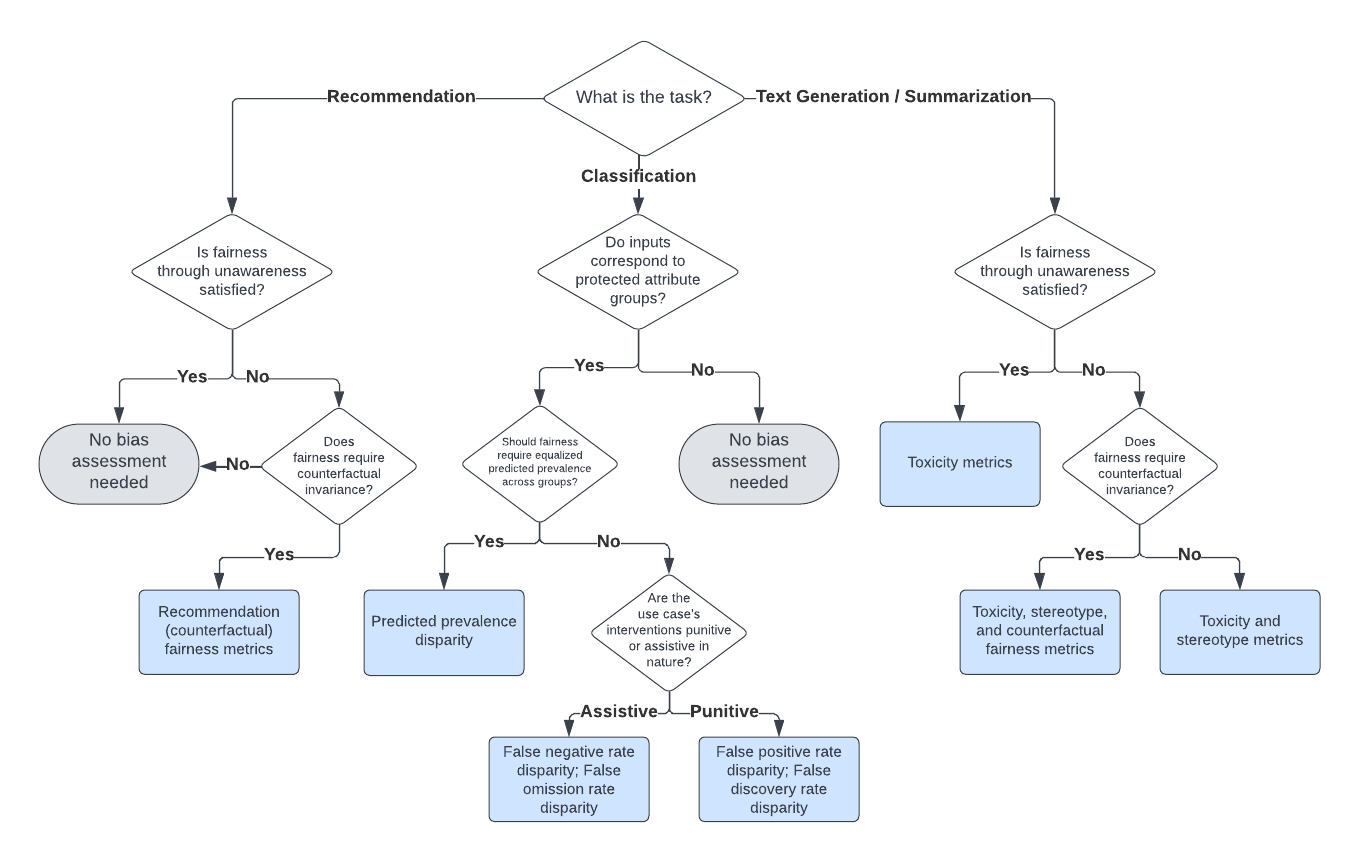
Note: Fairness through unawareness means none of the prompts for an LLM use case include any mention of protected attribute words.
Bias and fairness metrics offered by LangFair are grouped into several categories. The full suite of metrics is displayed below.
- Expected Maximum Toxicity (Gehman et al., 2020)
- Toxicity Probability (Gehman et al., 2020)
- Toxic Fraction (Liang et al., 2023)
- Strict Counterfactual Sentiment Parity (Huang et al., 2020)
- Weak Counterfactual Sentiment Parity (Bouchard, 2024)
- Counterfactual Cosine Similarity Score (Bouchard, 2024)
- Counterfactual BLEU (Bouchard, 2024)
- Counterfactual ROUGE-L (Bouchard, 2024)
- Stereotypical Associations (Liang et al., 2023)
- Co-occurrence Bias Score (Bordia & Bowman, 2019)
- Stereotype classifier metrics (Zekun et al., 2023, Bouchard, 2024)
- Jaccard Similarity (Zhang et al., 2023)
- Search Result Page Misinformation Score (Zhang et al., 2023)
- Pairwise Ranking Accuracy Gap (Zhang et al., 2023)
- Predicted Prevalence Rate Disparity (Feldman et al., 2015; Bellamy et al., 2018; Saleiro et al., 2019)
- False Negative Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
- False Omission Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
- False Positive Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
- False Discovery Rate Disparity (Bellamy et al., 2018; Saleiro et al., 2019)
A technical description of LangFair's evaluation metrics and a practitioner's guide for selecting evaluation metrics is contained in this paper. If you use our framework for selecting evaluation metrics, we would appreciate citations to the following paper:
@misc{bouchard2024actionableframeworkassessingbias,
title={An Actionable Framework for Assessing Bias and Fairness in Large Language Model Use Cases},
author={Dylan Bouchard},
year={2024},
eprint={2407.10853},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.10853},
}Please refer to our documentation site for more details on how to use LangFair.
The open-source version of LangFair is the culmination of extensive work carried out by a dedicated team of developers. While the internal commit history will not be made public, we believe it's essential to acknowledge the significant contributions of our development team who were instrumental in bringing this project to fruition:
Contributions are welcome. Please refer here for instructions on how to contribute to LangFair.