cyq.data is a high-performance and the most powerful orm. ormit's very special and different from others,who use who love it.
Support:Mssql、Mysql、Oracle、Sybase、Postgres、DB2、FireBird、Sqlite、DaMeng(达梦)、KingBaseES(人大金仓)、Txt、Xml、Access、Excel、FoxPro、Redis、MemCache。
开篇介绍:http://www.cnblogs.com/cyq1162/p/5634414.html
教程文章:https://github.com/cyq1162/cyqdata/tree/master/demo
QQ群:6033006、129551677,QQ:272657997
VIP培训课程,精通系列视频,300元/套,(共18集,每集1小时左右),可群里联系作者购买!
CYQ.Data 最近汇总了一下教程,放个人微信公众号里了,有需要的在公众号里输入cyq.data就可以看到了

注意事项:
1:MySQL 5.7.9版本需要把用命令行设置: 执行SET GLOBAL sql_mode = ''; 把sql_mode 改成非only_full_group_by模式。验证是否生效 SELECT @@GLOBAL.sql_mode 或 SELECT @@sql_mode
As CYQ.Data began to return to free use, it was found that users' emotions were getting more and more excited. In order to maintain this continuous excitement, I had the idea of open source.
At the same time, because the framework has evolved over the past 5-6 years, the early tutorials that were previously published are too backward, including the way they are used, and related introductions, which are easily misleading.
To this end, I intend to re-write a series to introduce the latest version, let everyone transition from traditional ORM programming to automated framework-based thinking programming (self-created words).
So: the name of this new series is called: CYQ.Data from entry to give up ORM series
1: It is an ORM framework.
2: It is a data layer component.
3: It is a tool set class library.
Look at a picture below:

As can be seen from the above figure, it is more than just an ORM, but also comes with some functions.
therefore:
Write log: You no longer need: Log4net.dll
Manipulating Json: You no longer need newtonjson.dll
Distributed Cache: You no longer need Memcached.ClientLibrary.dll
At present, the framework is only 340K, and subsequent versions will not be confused and the volume will be smaller.
Look at a one-size-fits-all development trend chart:

In the open source China search for .NET department: ORM, the number is about 110, in the CodeProject search for .NET department: ORM, the number is about 530.
After a lot of review, it's easy to see that the ORMs on the market are almost the same, the only difference:
It is in the custom query grammar, each family is playing their own tricks, and must play differently, otherwise everyone is the same, showing no sense of superiority.
At the same time, this variety of nonsense query syntax sugar also wastes a lot of developer time, because the cost of learning is to look at a book or a series from entry to mastery.
In general, it is possible to jump out of this trend! Explain that ORM is a routine, innovative, and requires art cells.
Once, I also had a very simple and traditional ORM called XQData:
I created it in 2009, and found that I am still lying on the hard disk, and I will openly share it with open source to the small partners who have not made ORM.
XQData source code (SVN download) address: http://code.taobao.org/svn/cyqopen/trunk/XQData
In the early version of CYQ.Data (not too early to say), compared with the traditional entity ORM, in addition to eclectic, it seems a bit tide, value encouragement and attention, it does not feel cool where it is used .
With the formation of the automation framework thinking, after years of improvement, today, the gap with the physical ORM is not at the same level.
First look at the way the entity ORM code is written: the entity inherits from CYQ.Data.Orm.OrmBase
Using (Users u = new Users()) { u.Name = " passing the fall " ; u.TypeID = Request["typeid"] ; // .... u.Insert(); }
It looks very simple, isn't it? It is indeed, but it is too fixed, not smart enough, once written, it is a pair of heavenly connections.
Why do I recommend MAction? Because it has an automated framework thinking:
Look at the following code:
Using (MAction action = new MAction(TableNames.Users)) { action.Insert( true );//There is no single assignment process in the middle }
1: The code is less, there is no intermediate assignment process;
2: No dependency on attributes and database fields: no matter whether you modify the interface or modify the database, the background code is not adjusted;
1: Entity ORM: Code segments can only be included with distributed transactions, and links cannot be reused.
2: MAction: You can use local transactions, you can reuse links.
The above MAction code, there is a TableNames.Users table name dependency, if you turn it into a parameter, you will find a different sky:
Using (MAction action = new MAction) { action.Insert( true ); }
With just two lines of code, you find that it is completely decoupled from the database and interface.
1: Because it implements the true decoupling of the data layer and the UI layer.
2: Because it is based on the thinking of automated framework programming, there is no longer a process of attribute assignment.
Seeing this, and then looking back at the AjaxBase in the ASP.NET Aries open source framework, you can understand that the total code in the background is able to handle the automatic processing of arbitrary tables and data:
The following method only needs to pass a table name (+ corresponding data) to the front page:

If you further configure the table name in the Url menu field in the database, then an automated page is formed:
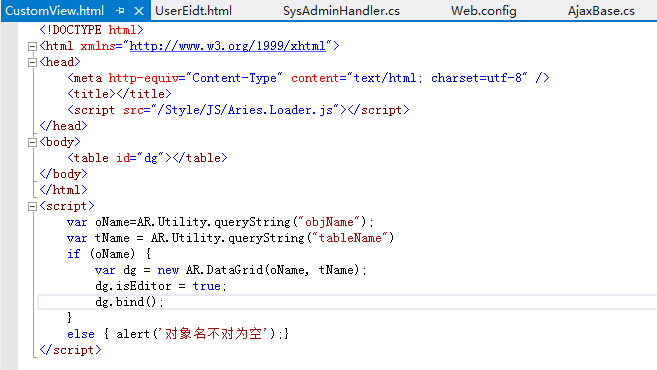
And these automatic automation framework programming thinking, are not possessed by the physical ORM, the entity ORM can only play a small bunch of code for a certain interface of a bunch of code.
Assume that there is an App project, there are Android version and IOS, they all need to call the background API. At this time, how do you design?
Don't move, wait for the App product manager to finalize the interface prototype, and then what elements are needed for the App interface, discuss with the development app development engineer, and then write the method for the request?
After all, you have to know which table to read and which data to check, so you can only passively? Every time you add a page or feature, you have to go to the background to write a bunch of business logic code, and then joint debugging?
Is it particularly tired?
Looking at the direct use of this framework, the process of your design will become simple, elegant and abstract:
Interface core code:
Using (MAction action = new MAction(tableName)) { action.Select(pageIndex, pageSize, where ).ToJson(); }
The next thing you want to design is:
1: Format the client request parameters for the app: {key:'xx',pageindex:1,pagesize:10,wherekey:'xxxx'}
2: Put the table name mapping into the database (Key, Value), the App only passes the Key when requesting the name
3: According to the actual business, construct the where condition.
Design a few of these common interfaces, and give them to the app developer to see what advantages they have:
1: Can reduce a lot of communication costs.
2: The design of the API is universal, reducing a lot of code, and subsequent maintenance is simple and configurable.
3: You can start work from the beginning, you don't have to wait until the App prototype starts.
4: Whether the continuous table exists or not, can be used in advance, and can be configured in the later stage.
5: After implementing a set, you can use the company for business change, because your design is decoupled from the specific business.
Imagine changing to an entity ORM. Do you have to have a database in advance to generate a bunch of entities, and then the specific business continues to be New instance, the limitations of thinking can only be limited to specific business.
Look at a picture first:

For the common data addition, deletion and change operations of the table, as can be seen from the above figure, the framework finally abstracts two core parameters:
I once thought about syntactic sugar, whether to design the piece of Where as: .Select(...).Where(...).Having(...).GroupBy(...).OrderBy(.. .)...
1: Developers have no learning costs.
2: Maintain the youthful creativity of the frame.
3: Have an automated framework thinking.
1: The complexity of the frame's own complex design increases.
2: The user has high learning costs and increased usage complexity.
3: Not suitable for automated extension: design has been an expression, can not dynamically construct query conditions dynamically based on a key and table! Only suitable for specific examples and business, not suitable for automated programming.
Of course, in most of the Where conditions, many are based on the conditions of the primary key or the unique key. In order to further abstract and adapt to the automation programming, I have designed a self-powered derivation mechanism.
Look at the following two codes: the left is where the construct is relatively complete, and the one on the right can automatically derive where. (There is anti-SQL injection inside, so don't worry about where condition injection problem).
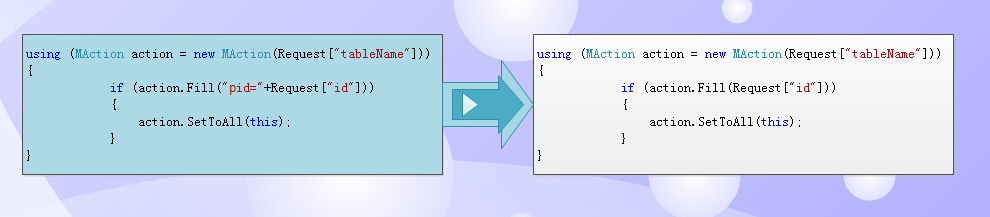
Through intelligent derivation, the primary key name parameter is removed (because the primary key table of different tables is different), intelligent derivation is generated, which allows the programmer to mainly care about the value passed, without paying attention to the specific primary key name.
If the value is a comma-separated multivalue of "1, 2, 3", the framework automatically derives the condition into the primary key in (1, 2, 3).
Look at the two sets of code: the left is still relatively complete where conditions, the right is intelligent derivation programming.
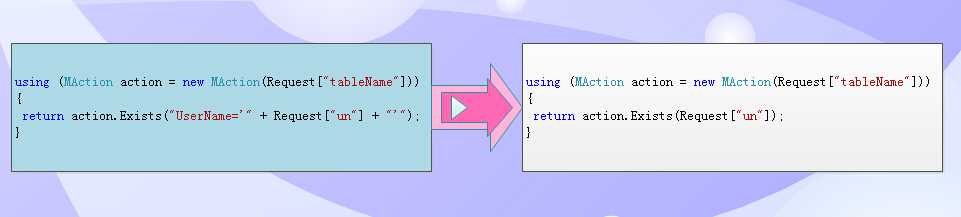
Note: The same is the value, but we want UserName, not the primary key, the system can also be derived?
At this time, the system will comprehensively analyze the type according to the type of the value, the primary key, and the unique key. It is found that the value should be constructed with the primary key or the unique key.
(PS: Unique key derivation is a feature that was completed yesterday, so only the latest version is available.)
Because the framework has intelligent derivation function, the difference between the fields is shielded, so that the user only needs to pay attention to the value. It is also an important feature that allows you to implement automated framework programming thinking.
Look at a picture: MDataTable: It can directly generate batch conversions with various data types:

MDataTable is one of the core of the framework, and the previous article has an exclusive introduction to it.
Of course, the construction of Table is often based on rows, so look at a picture: MDataRow (it is the core of single-line data)
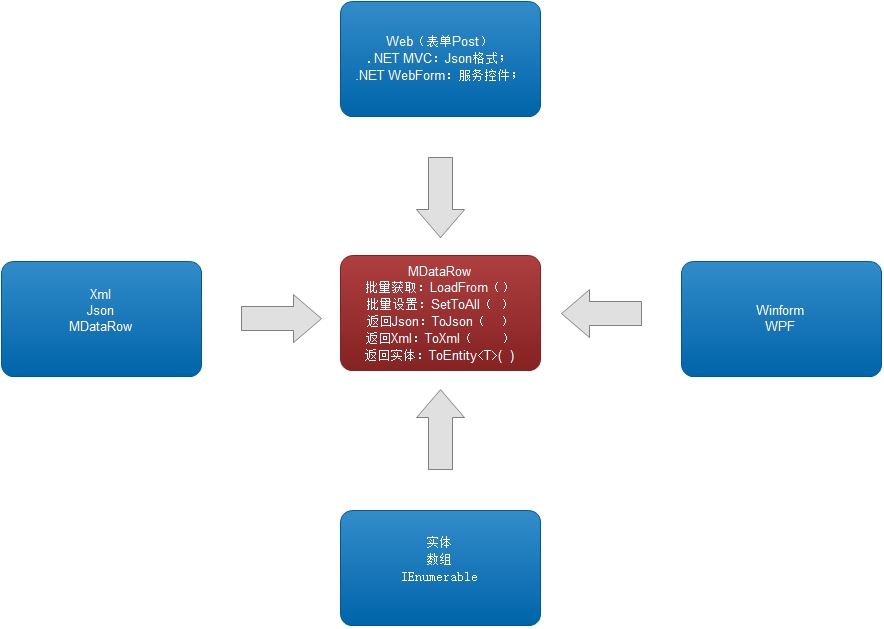
In fact, because MDataRow opened up a batch of data in a single line, it created a batch processing of multi-line data of MDataTable.
In fact, MDataRow is the core implementation layer, but it is relatively low-key.
1: Source SVN address: https://github.com/cyq1162/cyqdata.git
2: Project Demo example SVN address: https://github.com/cyq1162/CYQ.Data.Demo
3: Framework download address:
1: VS high version: search for cyqdata on Nuget
2: VS low version: http://www.cyqdata.com/download/article-detail-426
When using framework programming, you will find more concern about the flow of data and how to build a configuration system for abstract parameters.
In most of the programming time, in addition to the specific field meaning requires specific attention, most of them are based on automated programming thinking, data flow to thinking.
Early series: Without such programming thinking, it is inevitable that after reading the introduction, there will be a sense of violation.
Today's system: automation framework programming thinking, is also the reason for the high user loyalty, especially after free.
Of course, the follow-up will also rewrite the tutorial for this series, and the tutorial source code will be updated to SVN, so stay tuned.