El proyecto es una propuesta de modelamiento del idioma español por medio de bases de datos relacionales, para la creación del modelo el programa es capaz de analizar el orden, composición y estructura de cualquier texto suministrado o conjunto de palabras. Esto quiere decir que el programa es capaz de construir un modelamiento sobre cualquier idioma en el que estén escritos los textos suministrados, sin embargo, por defecto se distribuye con una implementación en español y una biblioteca de textos en español obtenidos por la herramienta de web scraping integrada en el proyecto.
Esta es la documentacion grafica oficial del proyecto, casi todo esta explicado ahi de una manera divertida; asi que espero sea de utilidad. ¡Se puede ver online en GitHub!
- Daniel Felipe Montenegro Herrera
Para su correcto funcionamiento el proyecto hace uso de cuatro librerías en Python, estas librerías son las que permiten la interconectividad de la herramienta. A continuación, se detalla el uso de cada librería:
- Os: Permite la lectura y escritura de archivos
- Time: Genera pequeños retardos para que la interfaz sea mas amigable
- Requests: Crea las solicitudes a las paginas web [1]
- Mysql.connector: Es la librería oficial de Mysql para conectarse desde Python [2]
- BeautifulSoup: Facilita el análisis de documentos html [3]
La librería Os y la librería Time vienen por defecto distribuidas con Python, el resto se instaló por medio de pip.
El Corpus de Referencia del Español Actual [4] (CREA) provee un listado de frecuencias de todas palabras existentes en la lengua.
Por defecto la base de datos se distribuirá con las primeras 121000 frecuencias del CREA, sin embargo, para poner a prueba la herramienta procesamos con ella 3276 textos (cuentos de diversos autores en el idioma español) que contenían 852302 frases los cuales fueron recolectados de la pagina web Ciudad Seva [5], esto gracias a que en su documento robots.txt especificaba al momento del raspado que era posible extraer este contenido.
Esta biblioteca se formo por medio de una aplicación que esta integrada en la librería para hacer Web Scraping de cualquier pagina web.
Es el gestor de base de datos que utiliza el proyecto, los scripts de creación de la base de datos que se distribuyen están implementados especialmente para su uso en MYSQL.
La base de datos que se distribuye por defecto es modificable, sin embargo, el script de creación incluido solo plantea la necesidad de cinco entidades para su correcto funcionamiento. Las entidades son las siguientes:
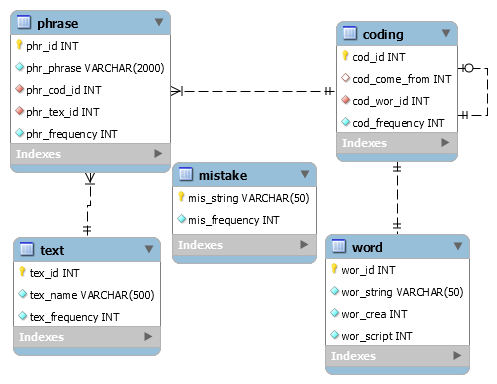
- Entidades (5): word, coding, phrase, mistake y text
- Triggers (1): frequent_mistake
- Views (7): crea, scripts, total_words, mistakes, codings, texts y phrases
- Stored Procedures (7): insert_crea, insert_word, insert_mistake, insert_coding, insert_text, insert_phrase y id_word
- Users (2): root y guest
- Values (121000): Las 121.000 primeras frecuencias del CREA
El script de creacion permite la creacion de dos usuarios, el primero es el usuario por defecto 'root' y el segundo es un usuario invitado llamado 'guest'.
Este es el detalle del contenido de cada una de las carpetas que se distribuyen con este proyecto:
-
/DATA WEB SCRAPING: Posee todos los textos que se utilizaron para construir la base de datos sustentada con el proyecto, son documentos de texto (.txt) los cuales son transcripciones de cuentos, poemas o libros extraidos de la web. Son mas de 3000 por lo que pesan un poco, asi que para poder distribuirlos los encontraras comprimidos en el archivo 'data_web_scraping.rar'.
-
/DOCUMENT: Te brindara un poco de informacion del proyecto, sin embargo, hay algunas cosas que son mas faciles de visualizar por eso es recomendable ver la presentacion que tiene informacion mas visual y completa sobre el proyecto.
-
/PRESENTATION: Esta es la documentacion grafica oficial del proyecto, casi todo esta explicado ahi de una manera divertida; asi que espero sea de utilidad. ¡Se puede ver online en GitHub!
-
/SQL: Esta carpeta tiene todo lo que respecta a la construccion de la base de datos con la que se sutento el proyecto, la carpeta tiene en su interior dos carpetas.
- /SQL/SYSTEM: Es la principal en ella encontraras tres carpetas.
- /SQL/SYSTEM/CREATION SCRIPTS: Contiene dos scripts en SQL que son 'modeler_database.sql' y 'modeler_initialization.sql', el primero crea el esquema y las tablas, el segundo los procedimientos almacenados, vistas, triggers,usuarios... etc. Ademas de agregar por defecto 121000 palabras para poder hacer uso de la libreria.
- /SQL/SYSTEM/DIAGRAM: Es la imagen del modelo de la base de datos.
- /SQL/SYSTEM/MODEL WORKBENCH: Es el archivo Workbench de la base de datos.
- /SQL/VALUES: Tiene el script en SQL comprimido en rar para poder agregar los mas de 3000 cuentos alojados en la carpeta 'DATA WEB SCRAPING'
- /SQL/SYSTEM: Es la principal en ella encontraras tres carpetas.
-
/CODE: Aqui esta alojado el script modeler.py del proyecto escrito en python.
El codigo puede desempeñar las siguientes funcionalidades, ya sea por medio del llamado a sus métodos o por medio de su interfaz de consola:
- Buscador de frases: Dada una palabra o frase, busca todas las frases de la base de datos con esa frase o palabra, señalando en cada una el texto de su origen.
- Corrector de ortografía: Dada una palabra o frase corrige su ortografía.
- Completar una frase: A partir de una palabra o frase indica cual es la palabra mas probable a continuación.
- Entrenador corrector ortografico: Funciona igual que el corrector ortografico, sin embargo, te indica las posibles correcciones y en caso de que no exista una corrección guarda la palabra como un error (exclusiva del usuario 'root').
Creando una conexión con la base de datos es posible consultar la vista phrases y realizar una búsqueda sobre la misma, la sentencia a utilizar será SELECT LIKE para utilizar el comodín de búsqueda “%”. Un ejemplo de la búsqueda para todas las frases que contienen “tu” en la base de datos seria la siguiente:
SELECT Phrase, Text_name FROM phrases WHERE Phrase LIKE ‘%tu%' ;
El resultado de esta búsqueda serán todas las tuplas frase-texto que contengan la palabra o frase indicada entre los porcentajes, de esta manera es como se implemento esta funcionalidad.
Para verificar cada uno de los ejemplos que se presentaran a continuación por favor considere como corrección ortográfica para cada tipo de error a la palabra: Montenegro. Supongamos que al escribir la palabra de ejemplo cometemos un error, podemos clasificar cualquier posible error en alguno de estos tipos.
- Error de omisión: Es la falta de uno o mas caracteres. Ejemplo:
Mntenegrose omite la primer letra o. - Error de posición: Se intercambia uno o mas caracteres por uno diferente. Ejemplo:
Montenegzose intercambio la r por la z. - Error de adición: Se agrega un carácter de mas a la palabra. Ejemplo:
Monttenegrose escribe la palabra con dos t.
La palabra virde es reamente la palabra verde mal escrita, para corregirla ortográficamente veamos los posible escenarios de acuerdo a los tipos de errores que presentamos anteriormente:
- - ?irde v?rde vi?de vir?e vird?
- = !irde
v!rdevi!de vir!e vird! - + !virde v!irde vi!rde vir!de vird!e virde!
Símbolos: El símbolo ? representa la ausencia de un carácter en esa posición, la ! significa que existe un carácter cualquiera en esa posición, que es lo mismo que “_” al hacer una consulta en SQL.
El caso resaltado es el que nos devolverá la corrección correcta de la palabra si intercambiamos ‘!’ por ‘e’, para obtener la palabra verde.
Para encontrar la corrección de una palabra buscaremos en la base de datos todos los posibles escenarios que nombramos anteriormente con la sentencia SELECT LIKE. En la diapositiva anterior indicamos que el caso resaltado es el que nos devolverá la corrección, es decir el caso v!rde que llevado a la sentencia SQL quedaría de la siguiente manera:
SELECT * FROM " + table + " WHERE Word LIKE ‘v_rde' ;
Esta sentencia la hacemos con cada uno de los posibles escenarios y eso nos dará como resultado todas las posibles correcciones, ahora simplemente solo elegimos la palabra que mas repeticiones tenga en la base de datos. Si estamos corrigiendo mas de una palabra podemos utilizar la vista codings que nos indicara cual es el conjunto de palabras que puede continuar luego de una frase solo realizamos la intersección de estos dos conjuntos para afinar la corrección.
Para completar una frase solo tenemos que realizar una consulta sobre la vista codings, pero antes es bueno explicar de que manera se almacenan los datos en esta vista.
Para hacerlo supongamos la siguiente frase del autor Abelardo Díaz Alfaro: “sombra imborrable del josco sobre la loma que domina el valle del toa”
- El programa divide la frase, es decir genera el arreglo: [sombra, imborrable, del, josco, sobre, la, loma, que, domina, el, valle, del, toa].
- Luego analiza cada una de estas palabras y las agrega a la tabla codings teniendo en cuenta de que palabra viene y a que palabra va (agrega el id de la palabra, la vista solo convierte este id en la palabra en cuestión).
- Si la combinación de palabras ya existe solo le suma uno a la frecuencia (esto lo hace el procedimiento almacenado).
La tabla codings es una tabla que se relaciona consigo misma, sin embargo, esta tabla solo esta compuesta por números y la columna cod_come_from es el id de la ultima fila de esta misma tabla que contiene la combinación de palabras anterior a la palabra de la columna cod_wor_id.
Nota: Abordar el problema de esta manera nos asegura poder crear relaciones entre las entidades que decidimos construir con anterioridad, ya que este tipo de modelos normalmente es construido bajo un paradigma NOSQL; el reto propuesto en este proyecto era proponer una alternativa funcional desde el paradigma SQL.
Esta es la misma funcionalidad que el corrector ortográfico, sin embargo, esta variación no nos mostrara una única corrección como resultado sino todas las posibles correcciones de una palabra y nos permitirá elegir cual es la correcta para nosotros, de esta manera una vez elegida la corrección correcta le sumara una frecuencia a esa palabra en la base de datos. Si no existe una corrección para esa palabra la agregara como un error a la base de datos.
Esta función es exclusiva del usuario “root” de la base de datos quien es el que posee todos los permisos sobre la base de datos. En el menú del usuario “guest” no aparecerá esta funcionalidad.
Las funcionalidades se pueden usar de dos maneras, por medio del menú implementado en la librería o haciendo uso de los métodos, para llamar a los métodos primero hay que escribir 'import modeler' en el script de Python en el que vayamos a utilizarlo, luego hacer uno de los siguientes llamados para la funcionalidad:
- Buscador de frases: modeler. find_frase(phrase)
- Corrector de ortografía: modeler.spell_checker (phrase, table)
- Completar una frase: modeler.predictive_text(phrase)
- Entrenador corrector ortografico: modeler.spell_checker_trainer(word, table)
La segunda alternativa es usar el menú integrado en la librería, para utilizar este menú existen dos maneras, la primera es ejecutar el script modeler.py, la segunda es ejecutar un “import modeler” y luego un “modeler.Menu()”. Al iniciar nos pedirá el usuario y contraseña de la base de datos, una vez ingresado y confirmada la conexión nos mostrara el menú.
[1] Requests: HTTP for Humans™. Tomado de: https://2.python-requests.org/en/master/
[2] MySQL Connector. Tomado de: https://www.mysql.com/products/connector/
[3] Beautiful Soup Documentation. Tomado de: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
[4] Corpus de Referencia del Español Actual (CREA) - Listado de frecuencias. Tomado de: http://corpus.rae.es/lfrecuencias.html
[5] Ciudad Seva: Casa digital oficial del escritor Luis López Nieves. Tomado de: https://ciudadseva.com/