Note: this library is old. Consider using the more mature DBoW2 library instead.
DBow is an open source C++ library for indexing and converting images into a bag-of-word representation. It implements a hierarchical tree for approximating nearest neighbours in the image feature space and creating a visual vocabulary. DBow also implements an image database, based on an inverted file structure, for indexing images and enabling quick queries.
DBow does not require OpenCV (except for the demo application), but they are fully compatible. You can check the demo included with the library to see how to use SURF features effortlessly.
DBow has been tested on a real dataset collected by the Rawseeds FP6-project, for a loop-closing application. In this test, 1755 images of an outdoor route were indexed in their bag-of-word representation and checked for matches in real time. On a Intel Quad CPU at 2.82 GHz, building a vocabulary with 95 words from a set of 1300 images took 3 minutes (without considering the feature extraction). The average time of adding a new image to the database was 1.9 ms, whereas querying the database took 7.2 ms on average.
The library is delivered with installation files for Visual Studio 9 (at least) and simple Makefiles. It has been tested on Windows with Visual Studio and STLport, and on Ubuntu with gcc 4.2.4. To install in Windows, open the Visual Studio sln file, open the Property page of the Demo project, change the include and library path of OpenCV if it is necessary, and compile all. If you do not have OpenCV installed or do not want to build the Demo application, disable that project.
To install in *nix, just type make nocv or make install-nocv to build the libraries. The latter command also copies them to the lib directory (not in the system directory). These commands do not build the demo application, which requires OpenCV2. To build also the demo, first make sure that pkg-config can find the OpenCV paths. If it cannot, you can modify the root Makefile and manually set the OPENCV_CFLAGS and OPENCV_LFLAGS macros. It should look like this:
Demo/Demo:
make -C Demo \
OPENCV_CFLAGS='/.../opencv/include/opencv' \
OPENCV_LFLAGS='/.../opencv/lib' \
OPENCV_LIBS='-lcxcore -lcv -lhighgui -lcvaux -lml'
Then, type make to build the demo, or make install to copy it to the bin directory too. A more portable installation system is not yet available, sorry.
Two lib/so library files are created. Your program must link against both of them (DBow and DUtils).
The library is composed of two main classes: Vocabulary and Database. The former is a base class for several types of vocabularies, but only a hierarchical one is implemented (class HVocabulary). The Database class allows to index image features in an inverted file to find matches.
###Weighting
Words in the vocabulary and in bag-of-words vectors are weighted. There are four weighting measures implemented to set a word weight wi:
- Term frequency (tf):
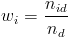 ,
,
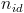 : number of occurrences of word i in document d,
: number of occurrences of word i in document d,
 : number of words in document d.
: number of words in document d. - Inverse document frequency (idf):
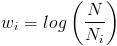 ,
,
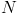 : number of documents,
: number of documents,
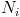 : number of documents containing word i.
: number of documents containing word i. - Term frequency -- inverse document frequency (tf-idf):
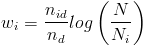 .
. - Binary:
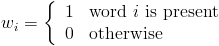
Note: DBow calculates N and Ni according to the number of images provided when the vocabulary is created. These values are not changed and are independent of how many entries a Database object contains.
###Scoring
A score is calculated when two vectors are compared by means of a Vocabulary or when a Database is queried. There are several scoring methods implemented. Note that the meaning of the numerical value of the score depends on the metric you are using. However, some of these metrics can be scaled to the interval [0..1], where 0 means no match at all, and 1 perfect match (see below). If you plan to modify the scoring code, note that for efficiency reasons there is an implementation in the Vocabulary class, and other in the Database class.
These are the metrics implemented to calculate the score s between two vectors v and w (from now on, v* and w* denote vectors normalized with the L1-norm):
- Dot product:
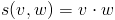
- L1-norm:
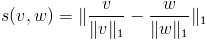
- L2-norm:
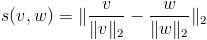
- Bhattacharyya coefficient:
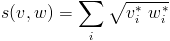
- χ² distance:
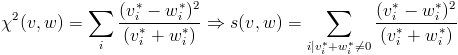
- KL-divergence:
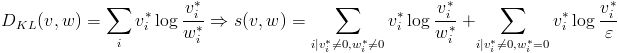
Note that with some methods, vectors are normalized before applying the metric. Since vectors are usually sparse and contain several zero entries, the χ² distance and the KL-divergence cannot be applied all along the vectors. For that reason, the entries that cause numerical problems are avoided. In the case of the KL-divergence, ε denotes the epsilon value of the computer (it is usually the smallest float positive number). When calculating a score, you can activate a flag to obtain it linearly scaled to [0..1], where 1 is the highest and 0 the lowest. You can activate this flag when using the L1-norm, the L2-norm and the χ² distance. Note that the Bhattacharyya coefficient is always in [0..1] independently of the scaling flag.
Note: for efficiency reasons, the implementation of the χ² distance assumes that weights are never negative (this is true when using tf, idf, tf-idf and binary vectors).
The default configuration when creating a vocabulary is tf-idf, L1-norm.
###Save & Load
All vocabularies and databases can be saved to and load from disk with the Save and Load member functions. When a database is saved, the vocabulary it is associated with is also embedded in the file, so that vocabulary and database files are completely independent.
Both structures can be saved in binary or text format. Binary files are smaller and faster to read and write than text files. DBow deals with the byte order, so that binary files should be machine independent (to some extent). You can use text files for debugging or for interoperating with your own vocabularies. You can check the file format in the HVocabulary::Save and Database::Save functions.