This ROS package creates an interface with dodo detector, a Python package that detects objects from images.
This package makes information regarding detected objects available in a topic, using a special kind of message.
When using an OpenNI-compatible sensor (like Kinect) the package uses point cloud information to locate objects in the world, wrt. to the sensor.
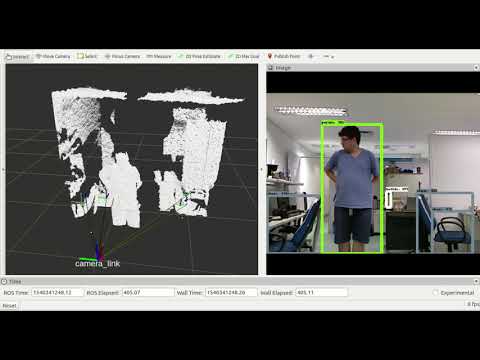
Click the image below for a YouTube video showcasing the package at work.
This repo is a ROS package, so it should be put alongside your other ROS packages inside the src directory of your catkin workspace.
The package depends mainly on a Python package, also created by me, called dodo detector. Check the README file over there for a list of dependencies unrelated to ROS, but related to object detection in Python.
Other ROS-related dependencies are listed on package.xml. If you want to use the provided launch files, you are going to need uvc_camera to start a webcam, freenect to access a Kinect for Xbox 360 or libfreenect2 and iai_kinect2 to start a Kinect for Xbox One.
If you use other kinds of sensor, make sure they provide an image topic and an optional point cloud topic, which will be needed later.
To use the package, first open the configuration file provided in config/main_config.yaml. These two global parameters must be configured for all types of detectors:
global_frame: the frame or tf that all object tfs will be published in relation to, egmap. Leave blank to publish wrt.camera_link.tf_prefix: a prefix for the object tfs which will be published by the package.
Then, select which type of detector the package will use by setting the detector_type parameter. Acceptable values are sift, rootsift, tf1 or tf2.
tf1 and tf2 detectors use the TensorFlow Object Detection API.
tf1 uses version 1 of the API, which works with TensorFlow 1.13 up until 1.15. It expects a label map and an inference graph. You can find these files here or provide your own. After you have these files, configure the following parameters in config/main_config.yaml:
inference_graph: path to the frozen inference graph (the.pbfile).label_map: path to the label map, (the.pbtxtfile).tf_confidence: confidence level to report objects as detected by the neural network, between 0 and 1.
tf2 uses version 2 of the API, which works with TensorFlow 2. It expects a label map and a directory with the exported model. You can find these files here or provide your own. After you have these files, configure the following parameters in config/main_config.yaml:
saved_model: path to the directory with the saved model (usually exported with the name saved_model by the API).label_map: path to the label map, (the.pbtxtfile).tf_confidence: confidence level to report objects as detected by the neural network, between 0 and 1.
Take a look here to understand how these parameters are used by the backend.
If sift or rootsift are chosen, a keypoint object detector will be used. The following parameters must be set in config/main_config.yaml:
sift_min_pts: minimum number of points to consider an object as present in the scene.sift_database_path: path to the database used by the keypoint object detector. Take a look here to understand how to set up the database directory.
After all this configuration, you are ready to start the package. Either create your own .launch file or use one of the files provided in the launch directory of the repo.
In your launch file, load the config/main_config.yaml file you just configured in the previous step and provide an image_topic parameter to the detector.py node of the dodo_detector_ros package. This is the image topic that the package will use as input to detect objects.
You can also provide a point_cloud_topic parameter, which the package will use to position the objects detected in the image_topic in 3D space by publishing a TF for each detected object.
The example below initializes a webcam feed using the uvc_camera package and detects objects from the image_raw topic:
<?xml version="1.0"?>
<launch>
<node name="camera" output="screen" pkg="uvc_camera" type="uvc_camera_node"/>
<node name="dodo_detector_ros" pkg="dodo_detector_ros" type="detector.py" output="screen">
<rosparam command="load" file="$(find dodo_detector_ros)/config/main_config.yaml"/>
<param name="image_topic" value="/image_raw" />
</node>
</launch>The example below initializes a Kinect using the freenect package and subscribes to camera/rgb/image_color for images and /camera/depth/points for the point cloud:
<?xml version="1.0"?>
<launch>
<include file="$(find freenect_launch)/launch/freenect.launch"/>
<node name="dodo_detector_ros" pkg="dodo_detector_ros" type="detector.py" output="screen">
<rosparam command="load" file="$(find dodo_detector_ros)/config/main_config.yaml"/>
<param name="image_topic" value="/camera/rgb/image_color" />
<param name="point_cloud_topic" value="/camera/depth/points" />
</node>
</launch>This example initializes a Kinect for Xbox One, using libfreenect2 and iai_kinect2 to connect to the device and subscribes to /kinect2/hd/image_color for images and /kinect2/hd/points for the point cloud. You can copy the launch file and use the sd and qhd topics instead of hd if you need more performance.
<?xml version="1.0"?>
<launch>
<include file="$(find kinect2_bridge)/launch/kinect2_bridge.launch">
<param name="_depth_method" value="cpu" type="str"/>
</include>
<node name="dodo_detector_ros" pkg="dodo_detector_ros" type="detector.py" output="screen">
<rosparam command="load" file="$(find dodo_detector_ros)/config/main_config.yaml"/>
<param name="image_topic" value="/kinect2/hd/image_color" />
<param name="point_cloud_topic" value="/kinect2/hd/points" />
</node>
</launch>These three launch files are provided inside the launch directory.