Iterator Implementation
RocksDB Iterator allows users to iterate over the DB forward and backward in a sorted manner. It also has the ability to seek to a specific key inside the DB, to achieve that .. the Iterator need to access the DB as a sorted stream.
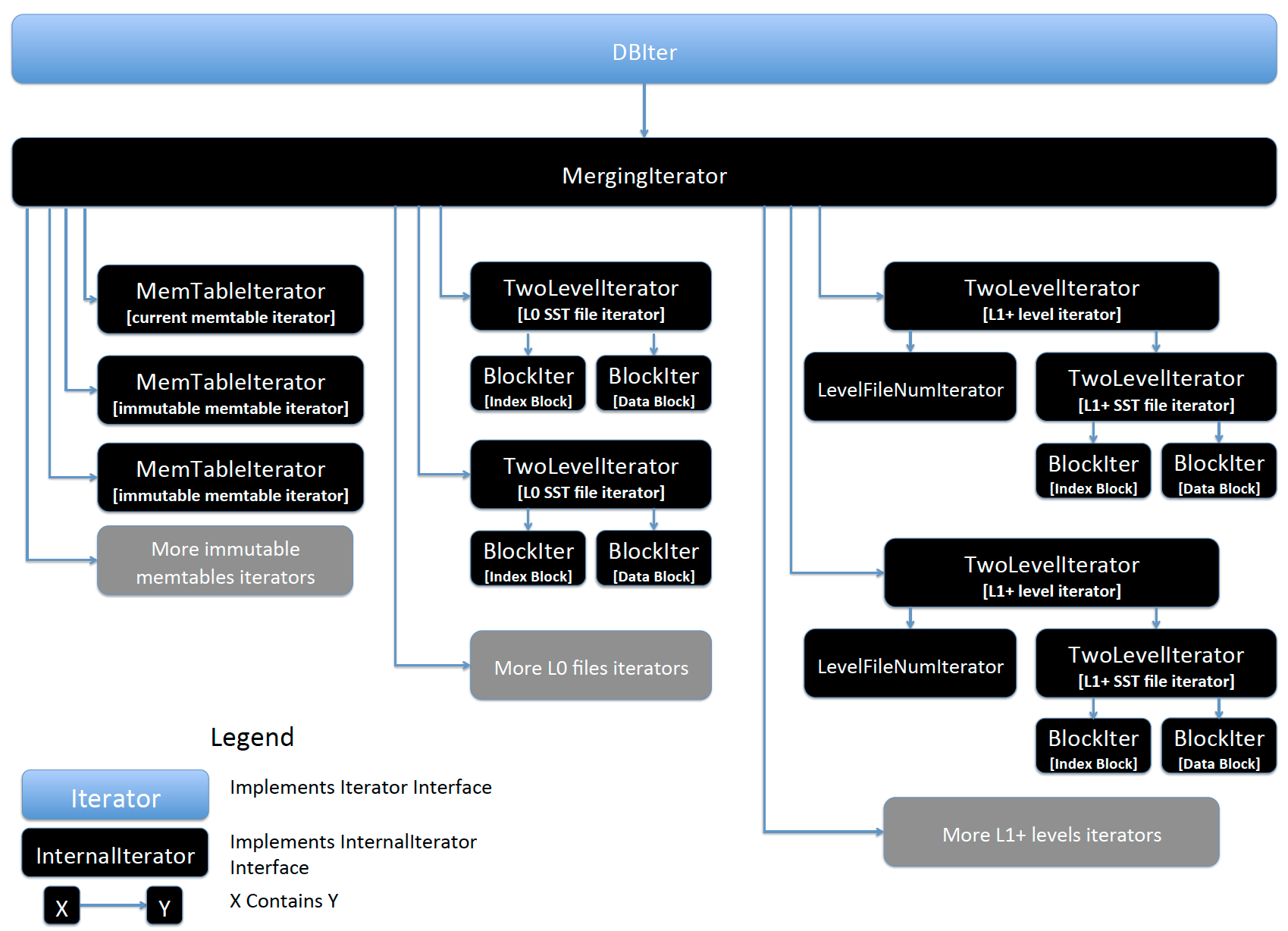
RocksDB Iterator implementation class is named DBIter, In this wiki page we will discuss how DBIter works and what it is composed of. In the following figure, you can see the design of DBIter and what it's composed of.
Implementation: db/db_iter.cc
Interface: Iterator
DBIter is a wrapper around an InternalIterator (In this case a MergingIterator).
DBIter's job is to parse InternalKeys exposed by the underlying InternalIterator and expose them as user keys.
The underlying InternalIterator exposed
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
But what DBIter will expose to the user is
Key="Key1" | Value = "KEY1_VAL2"
Key="Key2" | Value = "KEY2_VAL2"
Key="Key4" | Value = "KEY4_VAL1"
Implementation: table/merging_iterator.cc
Interface: InternalIterator
The MergingIterator is composed of many child iterators, MergingIterator is basically a heap for Iterators.
In MergingIterator we put all child Iterators in a heap and expose them as one sorted stream.
The underlying child Iterators exposed
= Child Iterator 1 =
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
= Child Iterator 2 =
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
= Child Iterator 3 =
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
The MergingIterator will keep all child Iterators in a heap and expose them as one sorted stream
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
Implementation: db/memtable.cc
Interface: InternalIterator
This is a wrapper around MemtableRep::Iterator, Every memtable representation implements its own Iterator to expose the keys/values in the memtable as a sorted stream.
Implementation: table/block.h
Interface: InternalIterator
This Iterator is used to read blocks from SST file, whether these blocks are index blocks or data blocks.
Since SST file blocks are sorted and immutable, we load the block in memory and create a BlockIter for this sorted data.
Implementation: table/two_level_iterator.cc
Interface: InternalIterator
A TwoLevelIterator is composed of 2 Iterators
- First level Iterator (
first_level_iter_) - Second level Iterator (
second_level_iter_)
first_level_iter_ is used to figure out the second_level_iter_ to use, and second_level_iter_ points to the actual data that we are reading.
RocksDB uses TwoLevelIterator to read SST files, first_level_iter_ is a BlockIter on the SST file Index block and second_level_iter_ is a BlockIter on a Data block.
Let's look at this simplified representation of an SST file, we have 4 Data blocks and 1 Index Block
[Data block, offset: 0x0000]
KEY1 | VALUE1
KEY2 | VALUE2
KEY3 | VALUE3
[Data Block, offset: 0x0100]
KEY4 | VALUE4
KEY7 | VALUE7
[Data Block, offset: 0x0250]
KEY8 | VALUE8
KEY9 | VALUE9
[Data Block, offset: 0x0350]
KEY11 | VALUE11
KEY15 | VALUE15
[Index Block, offset: 0x0500]
KEY3 | 0x0000
KEY7 | 0x0100
KEY9 | 0x0250
KEY15 | 0x0500
To read this file we will create a TwoLevelIterator with
-
first_level_iter_=>BlockIterover Index block -
second_level_iter_=>BlockIterover Data block that will be determined byfirst_level_iter_
When we ask our TwoLevelIterator to Seek to KEY8 for example, it will first use first_level_iter_ (BlockIter over Index block) to figure out which block may contain this key. this will lead us to set the second_level_iter_ to be (BlockIter over data block with offset 0x0250). We will then use the second_level_iter_ to find our key & value in the data block.