![]()

Router is a lightweight high performance HTTP request router (also called multiplexer or just mux for short) for fasthttp.
This router is optimized for high performance and a small memory footprint. It scales well even with very long paths and a large number of routes. A compressing dynamic trie (radix tree) structure is used for efficient matching.
Based on julienschmidt/httprouter.
Best Performance: Router is one of the fastest go web frameworks in the go-web-framework-benchmark. Even faster than httprouter itself.
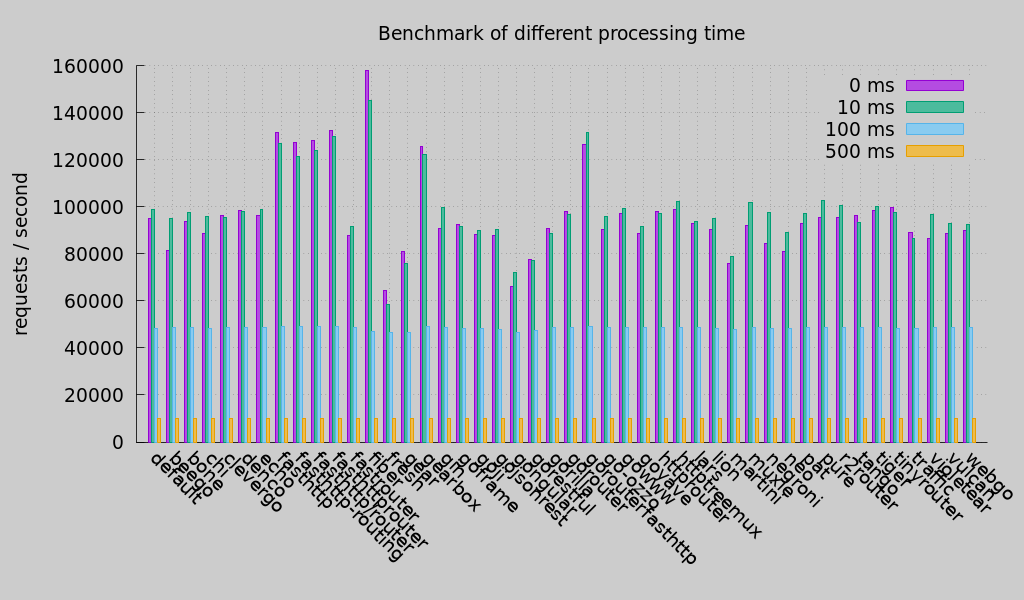
- Basic Test: The first test case is to mock 0 ms, 10 ms, 100 ms, 500 ms processing time in handlers.
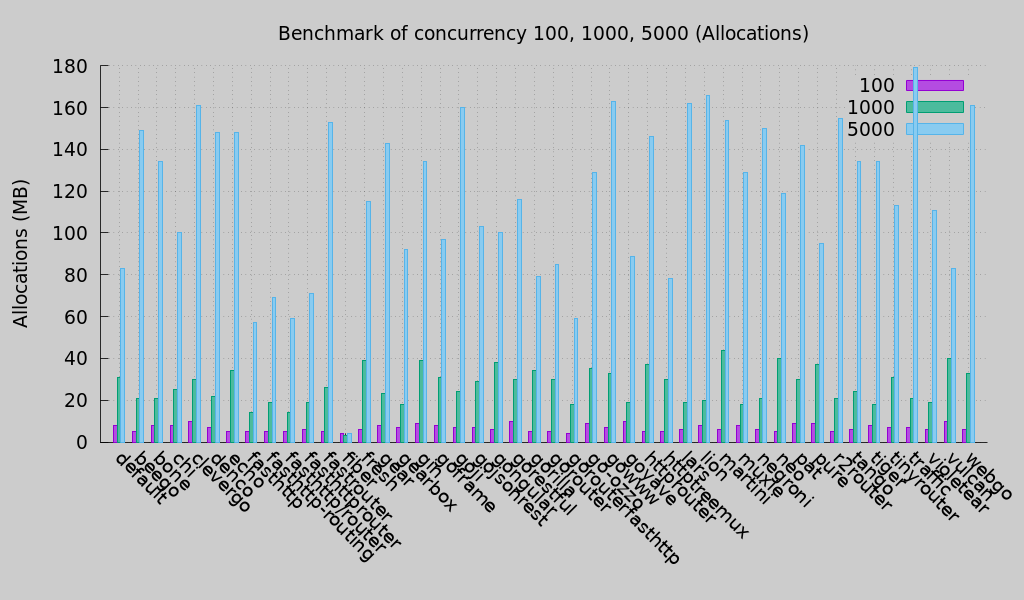
- Concurrency Test (allocations): In 30 ms processing time, the test result for 100, 1000, 5000 clients is:
* Smaller is better
See below for technical details of the implementation.
Only explicit matches: With other routers, like http.ServeMux, a requested URL path could match multiple patterns. Therefore they have some awkward pattern priority rules, like longest match or first registered, first matched. By design of this router, a request can only match exactly one or no route. As a result, there are also no unintended matches, which makes it great for SEO and improves the user experience.
Stop caring about trailing slashes: Choose the URL style you like, the router automatically redirects the client if a trailing slash is missing or if there is one extra. Of course it only does so, if the new path has a handler. If you don't like it, you can turn off this behavior.
Path auto-correction: Besides detecting the missing or additional trailing
slash at no extra cost, the router can also fix wrong cases and remove
superfluous path elements (like ../ or //).
Is CAPTAIN CAPS LOCK one of your users?
Router can help him by making a case-insensitive look-up and redirecting him
to the correct URL.
Parameters in your routing pattern: Stop parsing the requested URL path, just give the path segment a name and the router delivers the dynamic value to you. Because of the design of the router, path parameters are very cheap.
Zero Garbage: The matching and dispatching process generates zero bytes of garbage. In fact, the only heap allocations that are made, is by building the slice of the key-value pairs for path parameters. If the request path contains no parameters, not a single heap allocation is necessary.
No more server crashes: You can set a Panic handler to deal with panics occurring during handling a HTTP request. The router then recovers and lets the PanicHandler log what happened and deliver a nice error page.
Perfect for APIs: The router design encourages to build sensible, hierarchical
RESTful APIs. Moreover it has builtin native support for OPTIONS requests
and 405 Method Not Allowed replies.
Of course you can also set custom NotFound and MethodNotAllowed handlers and serve static files.
This is just a quick introduction, view the GoDoc for details:
Let's start with a trivial example:
package main
import (
"fmt"
"log"
"github.com/fasthttp/router"
"github.com/valyala/fasthttp"
)
func Index(ctx *fasthttp.RequestCtx) {
ctx.WriteString("Welcome!")
}
func Hello(ctx *fasthttp.RequestCtx) {
fmt.Fprintf(ctx, "Hello, %s!\n", ctx.UserValue("name"))
}
func main() {
r := router.New()
r.GET("/", Index)
r.GET("/hello/{name}", Hello)
log.Fatal(fasthttp.ListenAndServe(":8080", r.Handler))
}As you can see, {name} is a named parameter. The values are accessible via RequestCtx.UserValues. You can get the value of a parameter by using the ctx.UserValue("name").
Named parameters only match a single path segment:
Pattern: /user/{user}
/user/gordon match
/user/you match
/user/gordon/profile no match
/user/ no match
Pattern with suffix: /user/{user}_admin
/user/gordon_admin match
/user/you_admin match
/user/you no match
/user/gordon/profile no match
/user/gordon_admin/profile no match
/user/ no match
If you need define an optional parameters, add ? at the end of param name. {name?}
If you need define a validation, you could use a custom regex for the paramater value, add :<regex> after the name. For example: {name:[a-zA-Z]{5}}.
Optional parameters and regex validation are compatibles, only add ? between the name and the regex. For example: {name?:[a-zA-Z]{5}}.
The second type are catch-all parameters and have the form {name:*}.
Like the name suggests, they match everything.
Therefore they must always be at the end of the pattern:
Pattern: /src/{filepath:*}
/src/ match
/src/somefile.go match
/src/subdir/somefile.go match
The router relies on a tree structure which makes heavy use of common prefixes, it is basically a compact prefix tree (or just Radix tree). Nodes with a common prefix also share a common parent. Here is a short example what the routing tree for the GET request method could look like:
Priority Path Handle
9 \ *<1>
3 ├s nil
2 |├earch\ *<2>
1 |└upport\ *<3>
2 ├blog\ *<4>
1 | └{post} nil
1 | └\ *<5>
2 ├about-us\ *<6>
1 | └team\ *<7>
1 └contact\ *<8>
Every *<num> represents the memory address of a handler function (a pointer). If you follow a path trough the tree from the root to the leaf, you get the complete route path, e.g \blog\{post}\, where {post} is just a placeholder (parameter) for an actual post name. Unlike hash-maps, a tree structure also allows us to use dynamic parts like the {post} parameter, since we actually match against the routing patterns instead of just comparing hashes. [As benchmarks show][benchmark], this works very well and efficient.
Since URL paths have a hierarchical structure and make use only of a limited set of characters (byte values), it is very likely that there are a lot of common prefixes. This allows us to easily reduce the routing into ever smaller problems. Moreover the router manages a separate tree for every request method. For one thing it is more space efficient than holding a method->handle map in every single node, for another thing is also allows us to greatly reduce the routing problem before even starting the look-up in the prefix-tree.
For even better scalability, the child nodes on each tree level are ordered by priority, where the priority is just the number of handles registered in sub nodes (children, grandchildren, and so on..). This helps in two ways:
- Nodes which are part of the most routing paths are evaluated first. This helps to make as much routes as possible to be reachable as fast as possible.
- It is some sort of cost compensation. The longest reachable path (highest cost) can always be evaluated first. The following scheme visualizes the tree structure. Nodes are evaluated from top to bottom and from left to right.
├------------
├---------
├-----
├----
├--
├--
└-
Because fasthttp doesn't provide http.Handler. See this description.
Fasthttp works with RequestHandler functions instead of objects implementing Handler interface. So a Router provides a Handler interface to implement the fasthttp.ListenAndServe interface.
Just try it out for yourself, the usage of Router is very straightforward. The package is compact and minimalistic, but also probably one of the easiest routers to set up.
This package just provides a very efficient request router with a few extra features. The router is just a fasthttp.RequestHandler, you can chain any fasthttp.RequestHandler compatible middleware before the router. Or you could just write your own, it's very easy!
Have a look at these middleware examples:
NOTE: It might be required to set Router.HandleMethodNotAllowed to false to avoid problems.
You can use another fasthttp.RequestHandler, for example another router, to handle requests which could not be matched by this router by using the Router.NotFound handler. This allows chaining.
The NotFound handler can for example be used to serve static files from the root path / (like an index.html file along with other assets):
// Serve static files from the ./public directory
r.NotFound = fasthttp.FSHandler("./public", 0)But this approach sidesteps the strict core rules of this router to avoid routing problems. A cleaner approach is to use a distinct sub-path for serving files, like /static/{filepath:*} or /files/{filepath:*}.
If the Router is a bit too minimalistic for you, you might try one of the following more high-level 3rd-party web frameworks building upon the Router package: