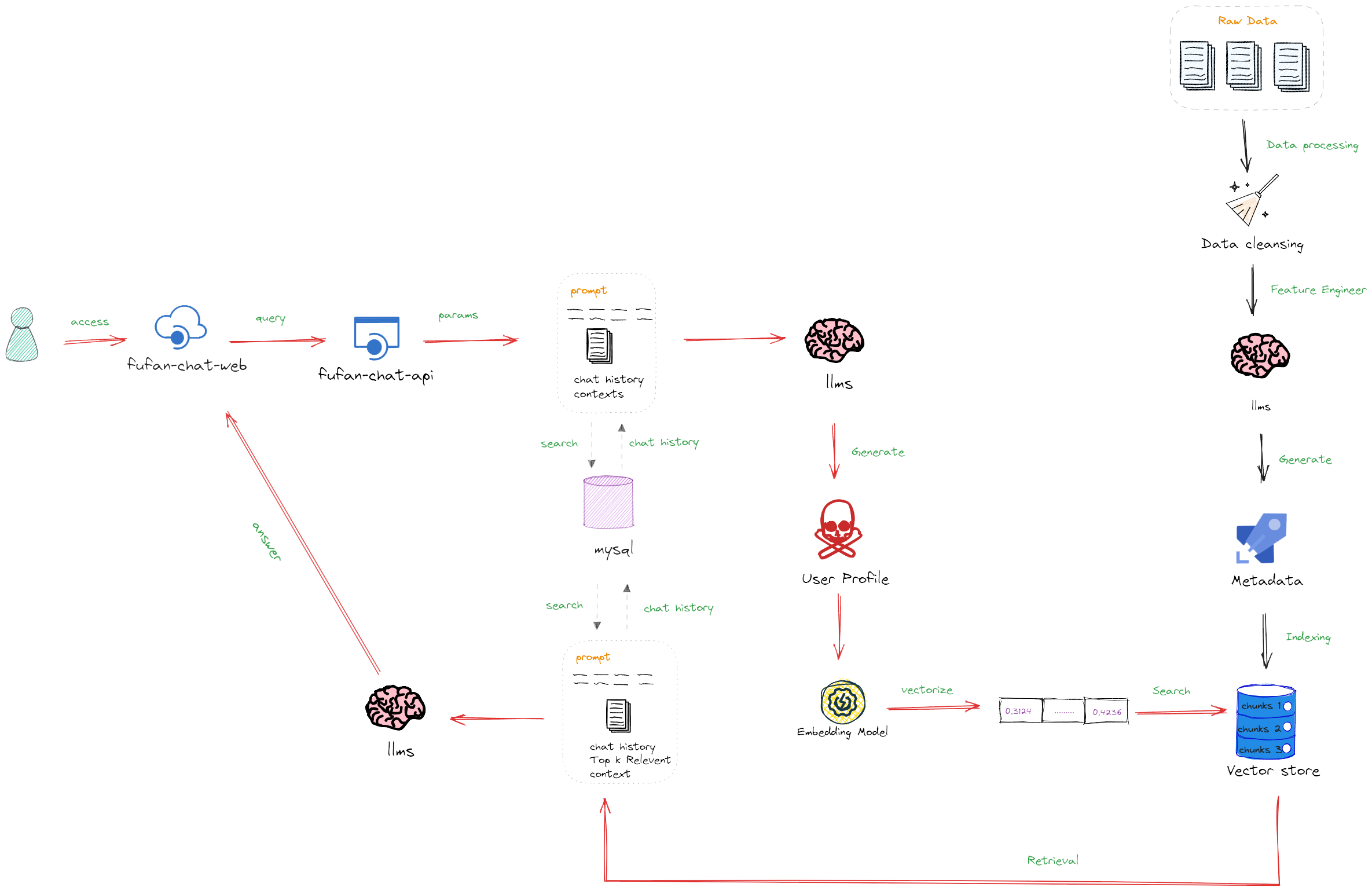
Fufan-chat-api is an intelligent Q&A system for local knowledge bases developed using large model technologies. This system implements five core scenarios of large model application deployment: general domain knowledge Q&A with large models, local private knowledge base Q&A, real-time internet search Q&A, AI Agents Q&A, and large model recommendation systems. Additionally, the system includes a complete RAG evaluation scheme and process, and supports Docker container deployment, offering highly flexible and efficient application deployment options.
This project is a secondary development based on the 👉LangChain-chatchat v0.2 version, where the original architecture was optimized using a frontend-backend separation design. The backend is developed entirely in Python, while the frontend utilizes the modern Vue3 framework. The frontend repository that this project interfaces with is👉 fufan-chat-web
- Comprehensive Functionality: Includes general domain knowledge Q&A with large models, local private knowledge base Q&A, real-time internet search Q&A, AI Agents Q&A, and large model recommendation systems.
- Data Preprocessing: Processes from zero to one and refines millions of public Wiki corpora, Markdown, PDF, and other types of private corpora.
- User Permission Management: Implements fine-grained user access control to efficiently ensure data security and privacy.
- Flexible Integration with Base Large Models: Supports integration with mainstream online and open-source large models, ensuring system adaptability and forward-thinking capabilities.
- Database Integration: Integrates relational databases and vector databases to optimize data access efficiency and query response times.
- Efficient and Complete RAG Evaluation System: Features a complete RAG evaluation pipeline that provides robust support for model assessment and optimization. See 👉 FlashRAG for reference.
- Docker Container Deployment: Supports Docker container deployment, simplifying the deployment process and enhancing the system's portability and maintainability.
Video coming soon.............
FuFan-chat-api provides a comprehensive user registration and login mechanism, ensuring system security and a personalized experience for each user. The main features of this module include:
- User Registration: Allows new users to create accounts. Once registered, users can access the system through the front-end login interface.
- User Validation: Conducts preliminary user validation at the front-end. Illegitimate users are prevented from accessing the intelligent Q&A system, ensuring system security.
- Session Management and Knowledge Base Access: Logged-in users can access system-predefined sessions and their personally created sessions. Additionally, users can utilize their own knowledge bases for Q&A, with strict limitations on each user’s data access to ensure the privacy of personal data.

FuFan-chat-api is compatible with a variety of high-performance open-source large models and online large model APIs as base models. This system version primarily uses ChatGLM3-6b, glm-4-9b-chat, and the online GLM-4 API interface. It allows users to flexibly integrate other models according to their actual needs, supporting mainstream models such as OpenAI GPT, Qwen2, as well as integration frameworks like Vllm and Ollama.
We have utilized the 👉 FastChat open-source project framework to deploy models, optimizing support for the glm4-9b-chat model. Although the FastChat framework was initially not compatible with glm4-9b-chat, we have manually fixed issues including streaming output and self-ask self-answer loops. Now, the glm4-9b-chat model is fully functional and stable. For the specific architecture, see 👉 FastChat Service Startup Logic and 👉 FastChat Request Handling Logic.
{kind=link}
{kind=link}
To facilitate users to extend or test new models, we provide detailed code examples. Through these examples, users can understand how to integrate new models into the system, further enhancing the system’s functionality and flexibility.
The general knowledge Q&A feature of the FuFan-chat-api fully utilizes the native conversational capabilities of large models. This function is based directly on large models and is integrated with the LangChain application framework to create a unified large model conversation interface. It enhances the memory capabilities of large model sessions by reading historical dialogue records from the MySQL database for specified users and dialogue windows in real time. For the specific architecture, see 👉General Domain Knowledge Q&A Logic Diagram.
{kind=link}
- Multi-turn Dialogue Support: Users can engage in continuous dialogue, with the system maintaining the context of the conversation to enhance coherence.
- Session History Memory: By remembering users' historical dialogues, the system can provide more personalized and accurate responses, greatly enhancing user experience.

Building upon the general knowledge Q&A process, we have introduced functionality for loading and retrieving from local knowledge bases using RAG technology with large models to enhance the quality of Q&A. This feature allows integration of large models with private data, effectively addressing limitations in large model knowledge. For the specific architecture, see 👉 Local RAG Knowledge Q&A Development Logic.
{kind=link}
We utilize Faiss for storing vector indexes, providing efficient retrieval capabilities for the system. The system is equipped with knowledge bases including millions of public Wiki corpora and private corpora (in PDF format), enhancing data breadth and depth. For the specific architecture, see 👉 Vector Database Integration Logic.
{kind=link}
- Multi-turn Dialogue Support: Maintains coherence across multiple interactions.
- Historical Memory Functionality: Enhances conversation personalization and relevance through historical session records.
- System Prompt Role: Introduces a system prompt role to guide user interactions, providing a more humane interactive experience.
- Real-time Faiss Vector Data Retrieval: Utilizes Faiss vector database for fast and efficient data retrieval, optimizing answer accuracy.

This feature integrates real-time online retrieval, a very mainstream large model application in AI search today. We ensure the efficiency and accuracy of information retrieval through more detailed process handling, which performs well even under domestic network conditions. For the specific architecture, see 👉 Online Real-Time Retrieval Q&A Logic.
{kind=link}
- Information Retrieval via 👉 Serper API Google Search: Utilizes the search capabilities built with the Serper API to retrieve webpage information in real-time based on the user’s query.
- Preliminary Re-ranking: The system filters initial search results, selecting the top N webpages most relevant to the query.
- Information Indexing: Rule-based extraction of the selected webpage content is performed, followed by indexing and storage in the Milvus vector database, preparing for subsequent retrieval operations.
- Vector Retrieval: Executes retrieval within the Milvus vector database to quickly find information chunks (Chunks) most relevant to the user’s query.
- Answer Generation: Integrates the retrieved information chunks into a complete prompt, from which it generates precise answers to meet the user's query needs.

This feature innovatively integrates large language models (LLMs) into the recommendation systems of the education industry to enhance the personalization and accuracy of recommendations. The system is specifically designed for the educational sector and includes the following key steps:
- Feature Engineering: Utilizes the powerful processing capabilities of LLMs to extract and optimize features from educational content. This step enhances the recommendation system's ability to parse educational data, making the recommendations more precise.
- Real-time User Profile Generation: Combines LLMs with users' historical behavior data to dynamically generate detailed user profiles. These profiles are continuously updated to accurately capture changes in users' preferences and needs.
- Real-time Recommendation Based on Behavior and Profile: Generates personalized educational content recommendations based on users' historical chat records and the real-time updated user profile, aiming to improve users' learning efficiency and satisfaction.
- Deep Feature Understanding: Through the deep learning capabilities of LLMs, the system can better understand the core features of educational content.
- Dynamic User Profiles: Real-time updated user profiles ensure the timeliness and relevance of recommendations.
- Personalized Recommendations: Based on detailed user data and behavior analysis, the recommendation system can provide highly personalized content to meet specific learning needs.
In the initial introduction of the Agent Q&A feature, the early version was tested based on LangChain-chatchat v0.2. The results did not meet our expectations, prompting us to decide on necessary optimizations and adjustments.
- Initial Implementation: The early version of our system primarily inherited the source code implementation of LangChain-chatchat v0.2 as the basis for Agent Q&A.
- Feature Integration: To enhance real-time capability and efficiency, we optimized and integrated the Serper API's real-time internet tools, enhancing the system's online search and data processing capabilities.
- Planned Upgrade: Considering the significant improvements in Agent Q&A with the LangChain-chatchat v0.3 version, we plan to refer to and adopt its latest implementation methods. This will include a comprehensive adjustment and optimization of the existing Q&A pathways to enhance overall performance.
We are actively developing and testing new versions to provide a smoother and more intelligent Agent Q&A experience. Stay tuned for the release of our latest version, which is expected to significantly improve user interaction quality and system response speed.

- GLM-4 API Streaming Output: Fixed defects in the streaming output feature of the GLM-4 API, enhancing the model's real-time interaction capabilities.
- LangChain Memory Asynchronous Loading: Optimized memory management to support asynchronous data processing, improving overall system performance.
- Error When Adding Indexes in Milvus: TypeError: 'NoneType' object is not subscriptable
- Official Bug in New Version: LangChain Issue #24116
- Solution: Temporarily resolve by forcing the installation of
pip install langchain-core==0.2.5, ignoring version dependency conflicts, and waiting for the official LangChain fix.
- LLM Recommendation System Course List Index Parsing Error: Error parsing JSON for document index 1
Ensure the following software or services are installed and properly configured:
- Python (version 3.10 or higher)
- MySQL (version 5.7 or higher)
- Milvus (version 2.3.7 or higher)
-
Clone the repository and install dependencies:
git clone https://github.com/fufankeji/fufan-chat-api.git cd fufan-chat-api pip install -r requirements.txt -
Deploy and start the MySQL service locally:
-
Initialize the relational database tables:
python /fufan-chat-api/server/db/create_all_model.py
-
Initialize the Faiss vector database:
python /fufan-chat-api/server/knowledge_base/init_vs.py
-
Deploy and start the Milvus vector database locally (if required):
-
Start the backend service:
python startup.py
Request URL: http://{server_ip}:8000/docs

Using Postman or another HTTP client tool to access the API endpoint:
To make a POST request to your API, first ensure that you replace the placeholder URL with the actual IP address and port number where your service is running. Here's how you might structure the request using a generic example:
http://192.168.110.131:8000/api/chat
{
"query":"What is machine learning?",
"conversation_id":"18b352a0-42de-419c-ada1-a0fa44dbee1d",
"model_name":"chatglm3-6b"
}We welcome contributions to the project via GitHub pull requests or issues. Any form of contribution is highly appreciated, including feature improvements, bug fixes, or documentation enhancements.化。
fufan_chat_api has launched version 1.0 and will continue to iterate and update. If you're interested, you're welcome to join our technical discussion group. For any other questions, scan to add Little Cute (WeChat: littlelion_1215) and reply with "RAG" for more details👇
