Windows page fault disk i/o slow on first load #705
Comments
|
I'm sorry page fault disk i/o on Windows is going slow for you! The best we can do here is find some trick to coax better performance out of your Windows executive. Could you please try something for me? Take this code: HANDLE proc;
WIN32_MEMORY_RANGE_ENTRY entry;
proc = GetCurrentProcess();
entry.VirtualAddress = addr;
entry.NumberOfBytes = length;
if (!PrefetchVirtualMemory(proc, 1, &entry, 0)) abort();And put it at the end of the Do you have a spinning disk? If you do, then another thing we could try if prefetch doesn't work, is having a loop where we do a volatile poke of each memory page so they're faulting sequentially. That could help the executive to dispatch i/o in a way that minimizes disk head movement. Although it's more of a long shot. Other than those two things, I'm not sure how we'd help your first case load times. The good news though is that subsequent runs of the LLaMA process will go much faster than they did before! |
|
There is still time to revert all this mess and go back to the previous model format. I'm not saying mmapping couldn't or shouldn't be implemented, but that there is a right way and a wrong way and the current way is simply wrong. Unnecessarily padding the model files with overhead what amounts to basically "anti-compression" or "bloat" and making them incompatible when there are proper ways to achieve this like with the new kv_cache storing/loading mechanism implemented in #685 which wouldn't introduce any regressions. |
|
I got similar issue as you, although on linux. Loading speed is unsatifying with current approach. |
|
@anzz1 100% agree with you there |
|
I think FILE_MAP_LARGE_PAGES should be used as a dwDesiredAccess in MapViewOfFileEx and SEC_LARGE_PAGES on flProtect in CreateFileMapping because I think 1000 megabyte requests are better than 1000000 kilobyte requests. |
|
I don't know if it helps, but there is also a mmap64 function for loading larger files. |
|
|
|
Read https://learn.microsoft.com/en-us/windows/win32/memory/creating-a-file-mapping-using-large-pages |
|
Allocating huge pages using mmap You can allocate huge pages using mmap(...MAP_HUGETLB). Either as a anonymous mapping or a named mapping on hugetlbfs. The size of a huge page mapping needs to be a multiple of the page size. For example to create an anonymous mapping of 8 huge pages of the default size of 2 MiB on AMD64 / x86-64: void *ptr = mmap(NULL, 8 * (1 << 21), PROT_READ | PROT_WRITE, |
|
@x02Sylvie I noticed that the new conversion tool creates files with a lot of fragments (in my case I measured 3m fragments in the 65B model). This is not much of a problem with an SSD, but with an spinning disk it may increase load times dramatically. Can you try defragmenting the disk or model file? |
Linux requires that you decide ahead of time what percent of memory is going to be devoted to huge pages and nothing else. With LLaMA that means you'd have to give up the lion's share of your memory, just so that when you run the llama command on occasion it goes maybe 10% faster? A:t best? I haven't measured it, because the last time I tried doing this, I totally nuked my system. I imagine this huge page thing might be nice if you've got something like a Postgres database server where it can have a more clearly defined subset of memory that's your work area. But I'm pretty doubtful that, given Linux's huge TLB design, and its requirement of special privileges and systems configuration, that it's really something worth focusing on. |
|
Out of curiosity, have you done this? Because I could imagine myself getting interested in huge pages if you can share the numbers you're seeing which demonstrate its helpful. If someone can say, "I ran it myself, measured inference time, and it went 2x faster" then I'd totally give it another shot. Since that'd be worth having. I'm just skeptical that will really happen. |
|
I just need time and I do not have it right now sorry. I will try to solve this by creating a new pull request, but I have to rival with #711 |
Using reserved pages in hugetlbfs only makes sense for very specialized applications and systems. As an alternative, it is still possible to suggest the use of huge pages through the transparent huge page mechanism, by calling |
|
@x02Sylvie Cn you please confirm that |
|
It is CreateFileMappingA problem and mmap problem due to large pages are not used (1 mb pages), instead 4 kb pages are used I need time to mmap to use large pages instead of pages. 1000000 kilobyte requests vs 1000 megabyte requests problem. |
|
@x02Sylvie Can you please try compiling with the following patch and report back with the benchmark results? diff --git a/llama.cpp b/llama.cpp
index 8789071..dbac5cf 100644
--- a/llama.cpp
+++ b/llama.cpp
@@ -321,10 +321,10 @@ static void *mmap_file(const char *fname, uint64_t *mm_length) {
fileSize.QuadPart = -1;
GetFileSizeEx(hFile, &fileSize);
int64_t length = fileSize.QuadPart;
- HANDLE hMapping = CreateFileMappingA(hFile, NULL, PAGE_READONLY, 0, 0, NULL);
+ HANDLE hMapping = CreateFileMappingA(hFile, NULL, PAGE_READONLY | SEC_LARGE_PAGES, 0, 0, NULL);
CloseHandle(hFile);
if (!hMapping) return 0;
- void *addr = MapViewOfFile(hMapping, FILE_MAP_READ, 0, 0, 0);
+ void *addr = MapViewOfFile(hMapping, FILE_MAP_READ | FILE_MAP_LARGE_PAGES, 0, 0, 0);
CloseHandle(hMapping);
if (!addr) return 0;
#else |
|
@prusnak Hello, The result is following, llama_model_load: failed to mmap '.\models\13B\ggml-alpaca-13b-q4-ggjt.bin' Reverting those two additions makes it load without error but slow as regular. I tried running program as administrator, same result |
|
Try to decode: |
|
Specifically "(the hFile parameter is a handle to an executable image or data file)" contradicts "this attribute is not supported for file mapping objects that are backed by executable image files or data files" |
|
It seems we have to align the mapping size to use large pages. @x02Sylvie can you please try again this code? (maybe you will need to run the code as admin? but please try running as normal user too) diff --git a/llama.cpp b/llama.cpp
index 8789071..e0508fe 100644
--- a/llama.cpp
+++ b/llama.cpp
@@ -321,10 +321,14 @@ static void *mmap_file(const char *fname, uint64_t *mm_length) {
fileSize.QuadPart = -1;
GetFileSizeEx(hFile, &fileSize);
int64_t length = fileSize.QuadPart;
- HANDLE hMapping = CreateFileMappingA(hFile, NULL, PAGE_READONLY, 0, 0, NULL);
+ SIZE_T largePageMinimum = GetLargePageMinimum();
+ uint64_t alignedLength = (length + largePageMinimum - 1) / largePageMinimum * largePageMinimum;
+ LARGE_INTEGER alignedFileSize;
+ alignedFileSize.QuadPart = alignedLength;
+ HANDLE hMapping = CreateFileMappingA(hFile, NULL, PAGE_READONLY | SEC_LARGE_PAGES, alignedFileSize.HighPart, alignedFileSize.LowPart, NULL);
CloseHandle(hFile);
if (!hMapping) return 0;
- void *addr = MapViewOfFile(hMapping, FILE_MAP_READ, 0, 0, 0);
+ void *addr = MapViewOfFile(hMapping, FILE_MAP_READ | FILE_MAP_LARGE_PAGES, 0, 0, 0);
CloseHandle(hMapping);
if (!addr) return 0;
#else |
|
You forgot about: } |
Same result so far both run as admin and non-admin ERROR_INVALID_PARAMETER My windows version: Maybe something's up with my windows, it'd be great if we had someone test on their windows side of things if code also fails to run there |

|
It fails on mine except for hFile = INVALID_HANDLE_VALUE; |
|
To Windows users complaining about slowdown: before developers can fix it, they need to understand the reason why it is slow. There was one plausible and easily-testable hypothesis expressed in the comments above: HDD + non-linear access pattern. The non-linear access pattern might happen due to multiple threads racing for the portion of the weights that they need. If my guess is correct, then:
As always with hypothesis testing, feedback from users who actually experience the bug is important. I don't have a Windows PC with HDD, and therefore can't help. |
|
In windows memory mapping each read creates a page fault and read from disk, if calculating how many times read from disk happens it can be decreased with larger pages or lock memory before the read. |
|
3 gb/s without mmap read compared to 500 mb/s read with mmap |
With how many threads? SSDs, you know, also prefer large linear reads. |
|
I tried with 1 and 8 threads same result 500 mb/s read |
NVMe was invented because SSDs prefer parallel IO |
|
There is also a good way, first map the file then create multiple async read requests to one mb allocated memory in ram. |
|
Solved first model loading time in #734 |
Better to use an explicit hint: Though I suspect this is unnecessary if you use |
I came up with this untested code snippet: #740 - needs more testing |
|
@x02Sylvie How much RAM do you have on your machine? |
|
Hi, My PR #801 will likely be merged soon. It includes a change that should theoretically fix the regression reported here, but I'd like to confirm that it actually does so. If you're one of the people experiencing this issue, I'd love if you could test the PR and report how it affects performance. If possible, please do the following:
Thanks in advance! |
|
This issue was closed because it has been inactive for 14 days since being marked as stale. |
Hello,
As of #613 I have experienced significant regression in model loading speed (I'm on windows, compiled msvc llama.cpp, llama.cpp is located on HDD to prevent SSD wear in my case)
It takes roughly 15 minutes for model to load first time after each computer restart/hibernation, during this time my HDD usage is at 100% and my non-llama.cpp read/write operations are slowed down on my pc
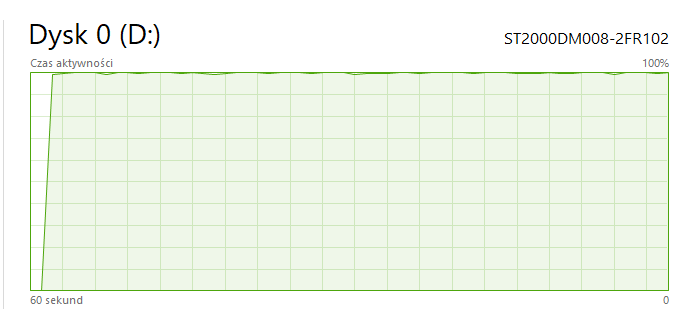
Before that, previous commits took 60 - 180 seconds at worst to load model first time, and after first loading occured, model loaded within 5 - 10 seconds on each program restart until pc reboot/hibernation
Before Commit:

After:
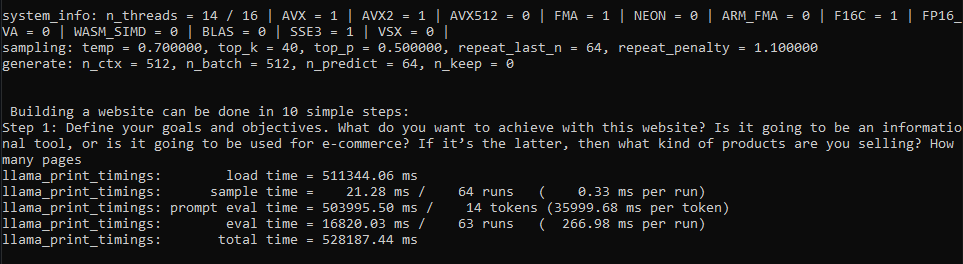
I see reason why model might load faster for some while slower (like my case) for others after recent changes, therefore in my opinion best solution is adding parameter that lets people disable llama.cpp's recent model loading changes if thats possible
The text was updated successfully, but these errors were encountered: