![]()
![]()




FileCrawler officially supports Python 3.8+.
- List all file contents
- Index file contents at Elasticsearch
- Do OCR at several file types (with tika lib)
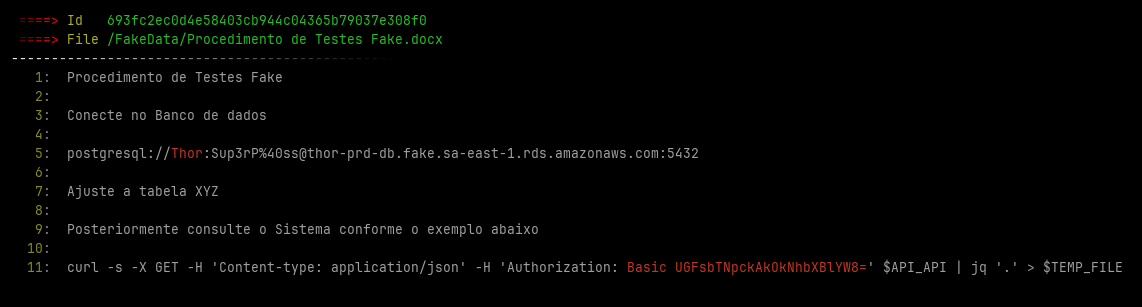
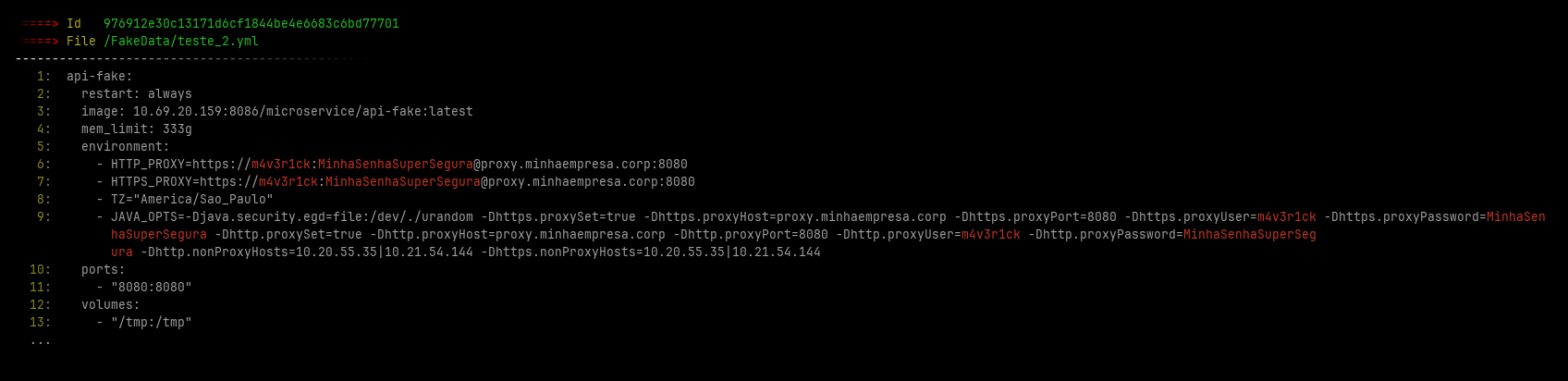
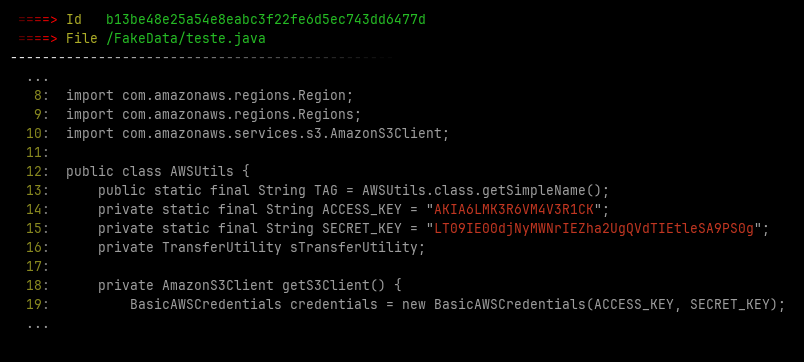
- Look for hard-coded credentials
- Much more...
- PDF files
- Microsoft Office files (Word, Excel etc)
- X509 Certificate files
- Image files (Jpg, Png, Gif etc)
- Java packages (Jar and war)
- Disassembly APK Files with APKTool
- Compressed files (zip, tar, gzip etc)
- SQLite3 database
- Containers (docker saved at tar.gz)
- E-mail (*.eml files) header, body and attachments
- Elasticsearch
- Stand-alone local files
- AWS credentials
- Github and gitlab credentials
- URL credentials
- Authorization header credentials
- Send credential found via Telegram
In additional File Crawler save some images with the found leaked credentials at ~/.filecrawler/ directory like the images bellow

apt install default-jre default-jdk libmagic-dev gitInstalling from last release
pip install -U filecrawlerInstalling development package
pip install -i https://test.pypi.org/simple/ FileCrawlerCreate a sample config file with default parameters
filecrawler --create-config -vEdit the configuration file config.yml with your desired parameters
Note: You must adjust the Elasticsearch URL parameter before continue
# Integrate with ELK
filecrawler --index-name filecrawler --path /mnt/client_files -T 30 -v --elastic
# Just save leaks locally
filecrawler --index-name filecrawler --path /mnt/client_files -T 30 -v --local -o /home/out_test$ filecrawler -h
File Crawler v0.1.3 by Helvio Junior
File Crawler index files and search hard-coded credentials.
https://github.com/helviojunior/filecrawler
usage:
filecrawler module [flags]
Available Integration Modules:
--elastic Integrate to elasticsearch
--local Save leaks locally
Global Flags:
--index-name [index name] Crawler name
--path [folder path] Folder path to be indexed
--config [config file] Configuration file. (default: ./fileindex.yml)
--db [sqlite file] Filename to save status of indexed files. (default: ~/.filecrawler/{index_name}/indexer.db)
-T [tasks] number of connects in parallel (per host, default: 16)
--create-config Create config sample
--clear-session Clear old file status and reindex all files
-h, --help show help message and exit
-v Specify verbosity level (default: 0). Example: -v, -vv, -vvv
Use "filecrawler [module] --help" for more information about a command.
$ docker build --no-cache -t "filecrawler:client" https://github.com/helviojunior/filecrawler.git#mainUsing Filecrawler's image:
Goes to path to be indexed and run the commands bellow
$ mkdir -p $HOME/.filecrawler/
$ docker run -v "$HOME/.filecrawler/":/u01/ -v "$PWD":/u02/ --rm -it "filecrawler:client" --create-config -v
$ docker run -v "$HOME/.filecrawler/":/u01/ -v "$PWD":/u02/ --rm -it "filecrawler:client" --path /u02/ -T 30 -v --elastic --index-name filecrawler$ sysctl -w vm.max_map_count=262144
$ docker build --no-cache -t "filecrawler:latest" -f Dockerfile.elk_server https://github.com/helviojunior/filecrawler.git#mainUsing Filecrawler's image:
Goes to path to be indexed and run the commands bellow
$ mkdir -p $HOME/.filecrawler/
$ docker run -p 443:443 -p 80:80 -p 9200:9200 -v "$HOME/.filecrawler/":/u01/ -v "$PWD":/u02/ --rm -it "filecrawler:latest"
#Inside of docker run
$ filecrawler --create-config -v
$ filecrawler --path /u02/ -T 30 -v --elastic --index-name filecrawler This project was inspired of:
Note: Some part of codes was ported from this 2 projects