CLONED from [SurajDonthi] (https://github.com/SurajDonthi/MTMCT-Person-Re-Identification) and adjusted for successful training process in colab.
This repository is inspired by the paper Spatial-Temporal Reidentification (ST-ReID)[1]. The state-of-the-art for Person Re-identification tasks. This repository offers a flexible, and easy to understand clean implementation of the model architecture, training and evaluation.
This repository has been trained & tested on DukeMTMTC-reID and Market-1501 datasets. The model can be easily trained on any new datasets with a few tweaks to parse the files!
You can do a quick run on Google Colab:
Below are the metrics on the various datasets.
| Model | Size | Dataset | mAP | CMC: Top1 | CMC: Top5 |
|---|---|---|---|---|---|
resnet50-PCB+rerank |
Market | 95.5 | 98.0 | 98.9 | |
resnet50-PCB+rerank |
Duke | 92.7 | 94.5 | 96.8 |
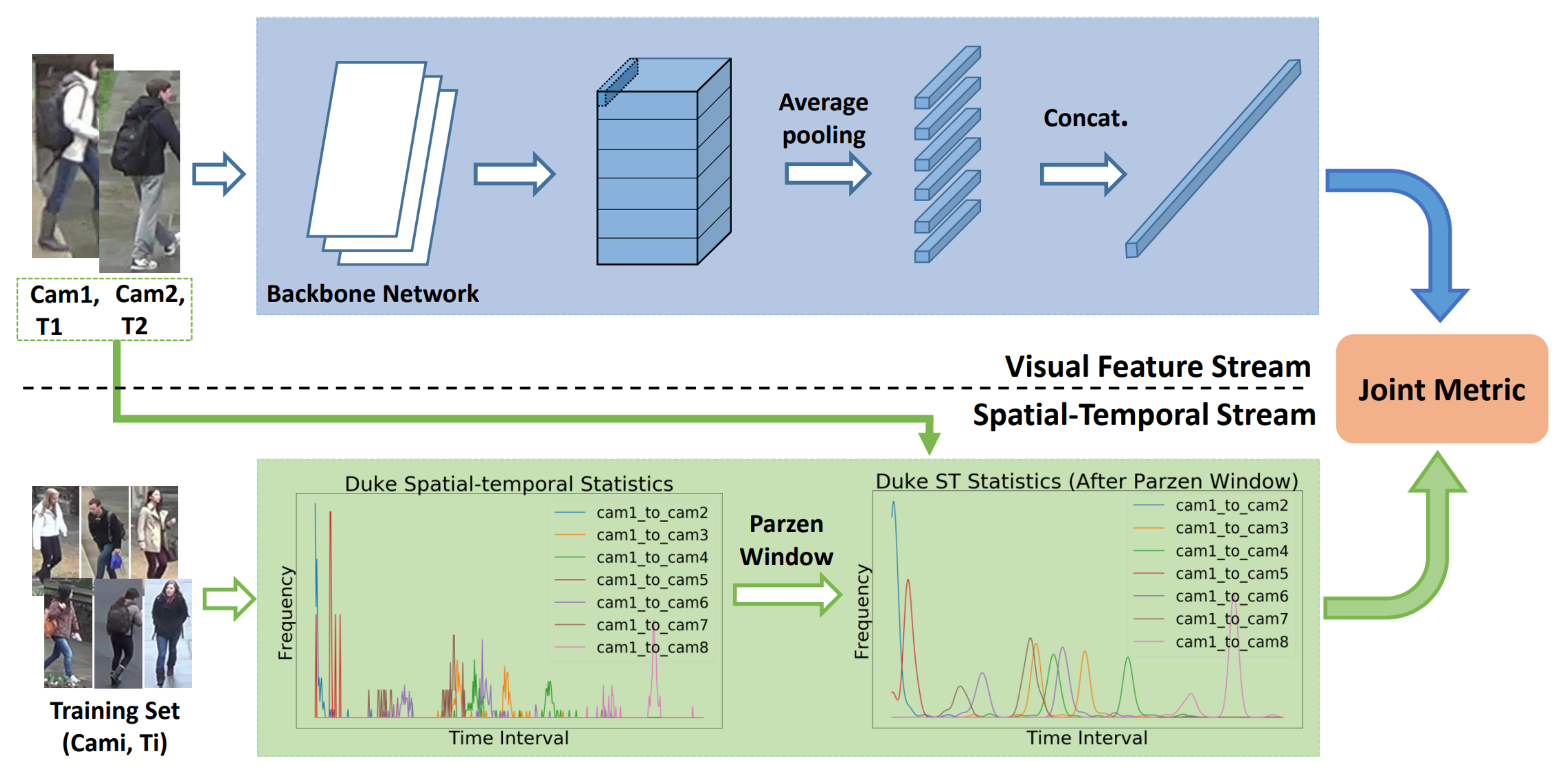
Source: Spatial-Temporal Reidentification(ST-ReID)
- A pre-trained ResNet-50 backbone model with layers up until Adaptive Average Pooling(excluded) is used
During Training
- The last Convolutional layer is broken into 6 (Final output size: 6 x 1) parts and separately used for predicting the person label.
- The total loss of the 6 part predictions are calculated for backpropagation & weights update.
During Testing/Evaluation/Deployment
- Only the visual feature stream up until Adaptive Average Pooling is used.
- The feature vector of the query image is compared against all the feature vectors of the gallery images using a simple dot product & normalization.
- The Spatio-Temporal distribution is used to calculate their spatio-temporal scores.
- The joint score is then calculated from the feature score and the spatio-temporal scores.
- The Cumulated Matching Score is used to find the best matching for person from the gallet set.
Run the below commands in the shell.
- Clone this repo, cd into it & install setup.py:
git clone https://github.com/SurajDonthi/MTMCT-Person-Re-Identification
cd MTMCT-Person-Re-Identification
pip install -r requirements.txt- Download the datasets. (By default you can download & unzip them to
data/raw/directory)
You can get started by training this model. Trained models will be available soon!
Dependencies
This project requires pytorch>=1.5.0, torchvision>=0.6.0, pytorch-lightning=1.1.1, tensorboard, joblib and other common packages like numpy, matplotlib and csv.
NOTE: This project uses pytorch-lightning which is a high-level interface to abstract away repeating Pytorch code. It helps achieve clean, & easy to maintain code with hardly any learning curve!
Run the below command in the shell.
python -m mtmct_reid.train --data_dir path/to/dataset/ --dataset 'market' \
--save_distribution path/to/dataset/st_distribution.pkl --gpus 1 --max_epochs 60For a detailed list of arguments you can pass, refer to hparams.csv
Log files are created to track the training in a new folder logs. To monitor the training, run the below command in the shell
tensorboard --logdir logs/Using commandline:
python -m mtmct_reid.eval model_path 'path/to/model' --dataset 'market' \
--query_data_dir 'path/to/query_data/' --gallery_data_dir 'path/to/gallery_data' \
--st_distribution_path 'path/to/spatio-temporal_distribution' \
--batch_size 64 --num_workers 4 --re_rank TrueThe evaluation metrics used are mAP (mean Average Precision) & CMC (Cumulated Matching Characteristics)
Finding the best matches during testing:
Step 1: From a given dataset, compute it's Spatial-Temporal Distribution.
Requires: cam_ids, targets(labels), frames, MODEL is not required!
Step 2: Compute it's Gaussian smoothed ST-Distribution.
Requires: cam_ids, targets(labels), frames, MODEL is not required!
Step 3: Compute the L2-Normed features that is generated from the model.
Requires: Features - Performed once training is finished!
Step 4: Compute the Joint Scores.
Requires: Smoothed Distribution & L2-Normed Features, cam_ids, frames
Step 5: Optionally perform Re-ranking of the Generated scores.
Requires: Joint Scores
Step 6: Compute mAP & CMC (Cumulated Matching Characteristics; for Rank-1,Rank-5, Rank-10) for each query.
Requires: Reranked/Joint Scores, (query labels & cams), (gallery labels & cams)
References:
[1] - Spatial-Temporal Reidentification(ST-ReID)
[2] - Beyond Parts Models: Person Retrieval with Refined Part Pooling
Related repos:
The model logic is mainly based on this repository.