

This Terraform module creates a Kubernetes Cluster on Hetzner Cloud infrastructure running Ubuntu 22.04. The module aims to be simple to use while providing an out-of-the-box secure and maintainable setup. Thanks to Ubuntu's LTS version we get up to 5 years of peace and quiet before having to upgrade the cluster's operating system!
Terraform module published at: https://registry.terraform.io/modules/identiops/k3s/hcloud
What changed in the latest version? See CHANGELOG.md.
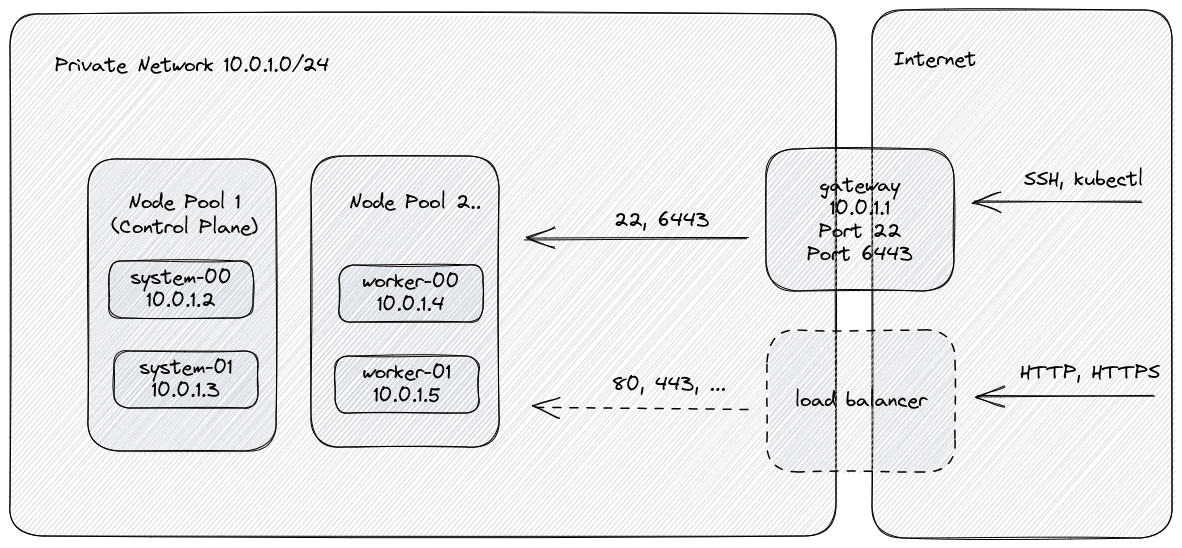
- k3s based Kubernetes cluster.
- Node pools for managing cluster resources efficiently. Pools can be added, resized, and removed at any time.
- Automated Kubernetes update management via System Upgrade Controller.
- Automated operating system updates with automatic system reboots via kured.
- Creation of placement groups for to improve availability.
- Multi-region deployments.
- Secured default configuration:
- Deletion protection for all cloud resources.
- SSH key required for remote access.
- fail2ban limits SSH brute force attacks.
- Cluster nodes have no public network interface.
- Internal firewall active on all nodes for minimal exposure.
- Support for network policies via Cilium.
- CSI hardening guide applied:
- Kernel parameters defined.
- Audit log directory created.
- Network policies, pod security policies, admission policies and the enabling of audit logs are up to the administrator of the cluster to configure.
- Integration of Hetzner Cloud Controller Manager for managing cloud resources from the within the cluster.
- Integration of Hetzner Cloud Storage Interface for managing volumes from the within the cluster.
- Ansible integration with automatically generated inventory.
- Convenience scripts for retrieving the Kubernetes configuration and accessing nodes via SSH and SCP.
- Calculation of monthly costs for every part of the deployment (see
terraform output). - Documentation of common administrative tasks and troubleshooting approaches.
- OIDC support for user authentication. Some configuration is in place, but it hasn't been tested, yet.
- Support for cluster auto scaler.
- Getting Started
- Maintenance
- Ansible: Execute Commands on Nodes
- Add Ingress Controller and Load Balancer
- Add Nodes or Node Pools
- Remove Nodes or Node Pools
- Stop Automated Node Reboots
- Upgrade Operating System
- Update Kubernetes
- Update Cilium
- Update Hetzner Cloud Controller Manager (CCM)
- Update Hetzner Cloud Storage Interface (CSI)
- Update Kured
- Update Metrics Server
- Update System Upgrade Controller
- Deletion
- Troubleshooting
- Related Documentation
- Similar Projects
- Special Thanks
- Terraform or OpenTofu. Note that you'll need Terraform v1.0 or newer to run this project.
bashfor executing the generated scripts.jqfor executing the generated scripts.kubectlfor interacting wthe the Kubernetes cluster.sshfor connecting to cluster nodes.
- Ansible cli for executing commands simultaneously on multiple cluster nodes.
- Cilium cli for verifying and interacting with the Kubernetes networking layer.
- Helm cli for installing and updating components inside the cluster.
- Create a Hetzner Cloud API token.
- Register with Hetzner Cloud.
- Create a new project.
- Navigate to the security settings.
- Select the "API tokens" tab and add a new token with read & write access and a second token with just read access.
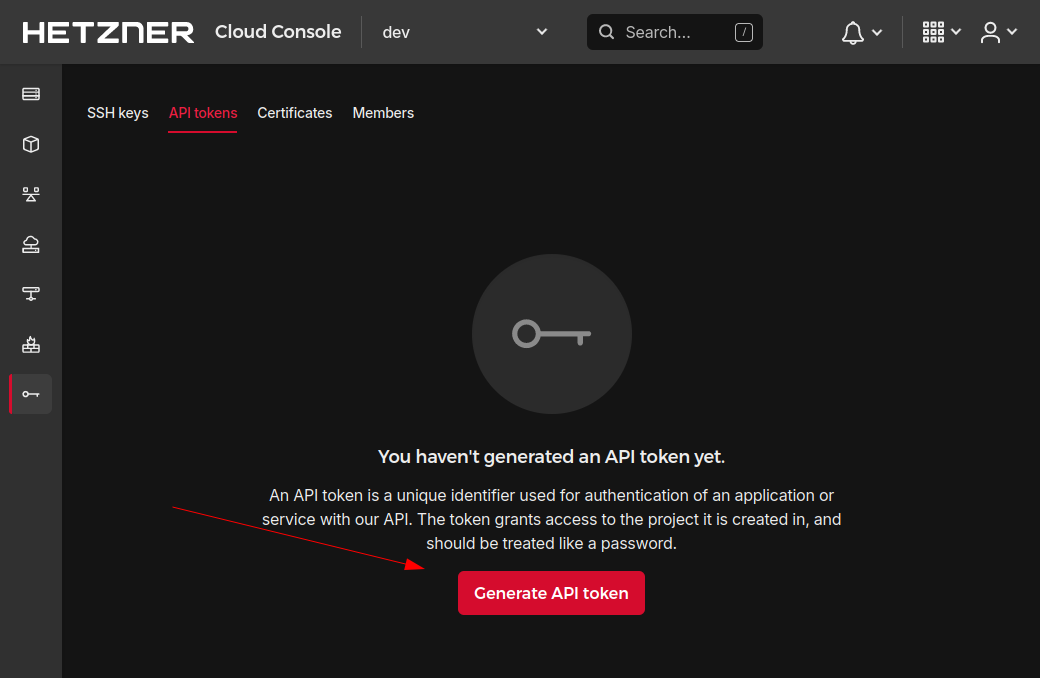
- Store Hetzner Cloud API token locally. Either, pass the tokens to terraform
via an environment variable or create a file called
terraform.tfvars:
# Either, enter your Hetzner Cloud API Token (it will be hidden)
read -sp "Hetzner Cloud API Token: " TF_VAR_hcloud_token
export TF_VAR_hcloud_token
read -sp "Hetzner Cloud API read only Token: " TF_VAR_hcloud_token_read_only
export TF_VAR_hcloud_token_read_only
# Or store the token in terraform.tfvars
touch terraform.tfvars
chmod 600 terraform.tfvars
cat >terraform.tfvars <<EOF
hcloud_token = "XYZ"
hcloud_token_read_only = "ABC"
EOF- Download
examples/1Region_3ControlPlane_3Worker_Nodes/main.tf:curl -LO https://github.com/identiops/terraform-hcloud-k3s/raw/main/examples/1Region_3ControlPlane_3Worker_Nodes/main.tf - Adjust the cluster configuration in
main.tf, e.g.cluster_namedefault_locationk3s_versionssh_keys(to create a new ssh key run:ssh-keygen -t ed25519)node_pools
- For multi-region deployments, there are a few things to consider:
- It is recommended to distribute the control plane nodes across multiple
regions. If 3 control plane nodes shall be used, create 3 node pools and
configure a different
locationfor each pool. - etcd's default configuration expects a low-latency local network. When
distributing nodes across multiple regions, latency will increase. The
timing parameters therefore need to be adjusted, see
etcd Tuning. Set
control_plane_k3s_additional_options, e.g. to--etcd-arg=heartbeat-interval=120 --etcd-arg=election-timeout=1200Measurements between Falkenstein, Nuremberg and Helsinki: I measured a latency of 0.7ms (within Nuremberg region), 3ms (Nuremberg -> Falkenstein), and 24ms (Nuremberg -> Helsinki). - Hetzner doesn't support mounting volumes on servers in another region! The most simple setup is to just distribute the control plane nodes across multiple regions, disable the scheduling of workloads on control plane nodes and keep all worker nodes pools within one region. For better availability of workloads, worker node pools should be distributed across regions. This requires a configuration of taints and tolerations and node affinity to ensure that pods with volumes are schedules in the correct region.
- Depending on the selected server regions the
network_zonesetting should be adjusted. - Hetzner's load balancers are bound to one region. Therefore, a multi-regional cluster with one load balancer is not sufficent for dealing with zone outages. The load balancer would go down with the region it's hosted in. If a protection against zone outages is required, a global load balancer should be deployed elsewhere, as described by Google.
- It is recommended to distribute the control plane nodes across multiple
regions. If 3 control plane nodes shall be used, create 3 node pools and
configure a different
- Initialize the configuration:
terraform init - Apply the configuration:
terraform apply - Grab a coffee and enjoy the servers popping up in Hetzner's cloud console. Wait for about 5 minutes.
- Test SSH access to the cluster:
./ssh-node cluster- ATTENTION: don't hammer the cluster with failing SSH requests, or you'll be banned by your cluster automatically! If the request fails, because the cluster node isn't ready yet, wait another minute.
- Once SSH connection is established, double check that everything is working
as expected:
- Did the node initialization finish successfully?
cloud-init status - Is the cluster up and running?
kubectl cluster-info
- Did the node initialization finish successfully?
- If the tests were successful, retrieve the Kubernetes configuration and
store it locally:
./setkubeconfig - Forward the cluster port locally since it's not exposed to the Internet by
default. Do this every time you want to interact with the cluster:
./ssh-node gateway - Test cluster access from your local machine:
kubectl get nodes
Enjoy your new cluster! 🚀
Start using your favorite Kubernetes tools to interact with the cluster. One of the first steps usually involves deploying an ingress controller since this configuration doesn't ship one.
In addition, a few convenience scripts were created to help with maintenance:
setkubeconfig: retrieves and stores the Kubernetes configuration locally.unsetkubeconfig: removes the cluster from the local Kubernetes configuration.ls-nodes: lists the nodes that are part of the cluster for access viassh-nodeandscp-node.ssh-node: SSH wrapper for connecting to cluster nodes.scp-node: SCP wrapper for connecting to cluster nodes..ssh/config: SSH configuration for connecting to cluster nodes..ansible/hosts: Ansible hosts configuration for executing commands on multiple nodes in parallel.
This module automatically generates an
Ansible inventory
in file .ansible/hosts. It can be leveraged to interact with the nodes and
node pools of the cluster.
Example: Execute a command on all control plane nodes
ANSIBLE_INVENTORY="$PWD/.ansible/hosts" ansible all_control_plane_nodes -a "kubectl cluster-info"Since this module doesn't ship an ingress controller, one of the first configurations applied to the cluster is usually an ingress controller. Good starting points for an ingress controller are:
The ingress controller, like the rest of the cluster, is not directly exposed to the Internet. Therefore, it is necessary to add a load balancer that is directly exposed to the Internet and has access to the local network of the cluster. The load balancer is added to the cluster simply by adding annotations to the ingress controller's service. Hetzner's Cloud Controller Manager will use the annotations to deploy and configure the load balancer.
The following annotations should be used:
- Resource name:
load-balancer.hetzner.cloud/name: "ingress-lb" - Protocol, just
tcp- the ingress controller will take care of the HTTP connection:load-balancer.hetzner.cloud/protocol: "tcp" - Location, same as the one used for the cluster:
load-balancer.hetzner.cloud/location: "nbg1" - Connection to the servers, must be set to
true:load-balancer.hetzner.cloud/use-private-ip: "true" - Size, see options:
load-balancer.hetzner.cloud/type: "lb11" - See list of all supported Load Balancer Annotations.
Furthermore, for domain names to work, it is required to point DNS records to the IP address of load balancer. external-dns is a helpful tool that can automate this task from within the cluster. For this to work well with Ingress resources, the ingress controller needs to expose the published service information on the Ingress resources.
The number of nodes in a node pool can be increased at any point. Just increase
the count and apply the new configuration via terraform apply. After a few
minutes the additional nodes will appear in the cluster.
In the same way, node pools can be added to the configuration without any precaution.
Removing nodes requires the following steps:
- Identify the nodes and node pools that shall be removed. If the number of
nodes in a node pool needs to be decreased, the nodes will be removed from
the highest to the lowest number. Example: when the number of nodes in pool
systemis decreased from3to2, nodecluster-system-02will be removed and nodescluster-system-01andcluster-system-00will remain. - Drain all nodes that will be removed of pods:
kubectl drain cluster-system-02 - Wait until all pods have been migrated to other nodes before continuing.
- If you drained the wrong node, you can reactivate the node with:
kubectl uncordon cluster-system-02
- If you drained the wrong node, you can reactivate the node with:
- Update the terrafrom configuration and apply it:
terraform apply- Review the plan to verify that the drained nodes will be deleted.
- Delete nodes from cluster:
kubectl delete node cluster-system-02
Nodes are rebooting automatically when they receive updates that require a reboot. The kured service triggers reboots of nodes one by one. Reboots can be disabled system-wide by annotating the Daemonset, see https://kured.dev/docs/operation/.
WARNING: untested!
An operating system update is not recommended, e.g. from Ubuntu 22.04 to 24.04. Instead, the corresponding nodes should be replaced!
- Set new image as
default_image. Attention: before changing the default image, make sure that each node pool has its own oppropriateimagesetting. - Delete the node in the Hetzner Console
- Reapply the configuration:
terraform apply
The gateway will reappear again within a few minutes. This will disrupt the Internet access of the cluster's nodes for tasks like fetching package updates. However, it will not affect the services that are provided via load balancers!
After redeploying the gateway, ssh connections will fail because a new
cryptopraphic has been generated for the node. Delete the deprecated key from
the .ssh/known_hosts file, open a new ssh connection and accept the new public
key.
Nodes should not be updated manually via agt-get, but be replaced. For control
plane nodes, it is recommended to create a back-up of the etcd data store on an
external s3 storage, see k3s Cluster Datastore.
- For control plane pools only: Create a new etcd snapshot, see k3s etcd-snapshot.
- Then, perform the following steps on consecutively on all existing node pools until they have all been replaced.
Start the replacement with the node pool with the cluster_can_init setting:
- Ensure that there's another control plane node pool. If there's no other
control plane node pool, create a temporary one that is deleted after the
successful replacement of the node pool with the
cluster_can_initsetting. - When the second control plane node pool is up and running, the node pool with
the
cluster_can_initsetting must be deleted and replaced in one application of the configuration.- Ensure that the
cluster_init_action.initandcluster_init_action.resetsettings are disabled. - Drain the old nodes:
kubectl drain node-xyz - Once all pods have been migrated, delete the old nodes:
kubectl delete node node-xyz - Then rename the node pool to achieve deletion and replacement in one configuration change.
- Apply the configuration:
terraform apply - Once the new control plane node pool with the
cluster_can_initsetting is again up and running, the temporary control plane node pool can be deleted.
- Ensure that the
Perform these steps for all remaining node pools:
- Add a new node pool and set the
imagesetting to the new version. - Once the new node pool is up and running, drain the old nodes:
kubectl drain node-xyz - Once all pods have been migrated, delete the old nodes:
kubectl delete node node-xyz - Remove the node pool from the terraform configuration.
- Reapply the configuration:
terraform apply
- Determine the next Kubernetes version, see k3s channels, k3s images tags, and k3s upgrade image tags.
- Write the upgrade plan, see instructions and examples.
- Apply an upgrade plan.
- Update the
imagevariable in the configuration for future nodes to be deployed with the correct image.
- Available versions: https://github.com/cilium/cilium
- Update instructions: https://docs.cilium.io/en/stable/operations/upgrade/
helm repo add cilium https://helm.cilium.io/
helm repo update
helm upgrade --reuse-values cilium cilium/cilium -n kube-system --version '<NEW_VERSION>'values.yaml:
# Documentation: https://artifacthub.io/packages/helm/cilium/cilium
# WARNING: needs to be in line with the cluster configuration
routingMode: native
ipv4NativeRoutingCIDR: 10.0.0.0/8
ipam:
operator:
clusterPoolIPv4PodCIDRList: 10.244.0.0/16
k8sServiceHost: 10.0.1.1
k8sServicePort: "6443"
operator:
replicas: 2- Available versions: https://github.com/hetznercloud/hcloud-cloud-controller-manager#versioning-policy
- Update instructions: https://github.com/hetznercloud/hcloud-cloud-controller-manager/blob/main/CHANGELOG.md
helm repo add hcloud https://charts.hetzner.cloud
helm repo update
helm upgrade --reuse-values hcloud-ccm hcloud/hcloud-cloud-controller-manager -n kube-system --version '<NEW_VERSION>'values.yaml:
# Documentation: https://github.com/hetznercloud/hcloud-cloud-controller-manager/tree/main/chart
# WARNING: needs to be in line with the cluster configuration
networking:
enabled: true
clusterCIDR: 10.244.0.0/16
additionalTolerations:
# INFO: this taint occurred but isn't coveryd by default .. and caused the
# whole cluster to not start properly
- key: node.kubernetes.io/not-ready
value: NoSchedule- Available versions: https://github.com/hetznercloud/csi-driver/blob/main/docs/kubernetes/README.md#versioning-policy
- Update instructions: https://github.com/hetznercloud/csi-driver/blob/main/CHANGELOG.md
helm repo add hcloud https://charts.hetzner.cloud
helm repo update
helm upgrade --reuse-values hcloud-csi hcloud/hcloud-csi -n kube-system --version '<NEW_VERSION>'values.yaml:
# Documentation: https://github.com/hetznercloud/csi-driver/tree/main/chart
storageClasses:
- name: hcloud-volumes
defaultStorageClass: true
retainPolicy: Retain- Available versions: https://artifacthub.io/packages/helm/kured/kured
- Update instructions: https://github.com/kubereboot/kured
helm repo add kubereboot https://kubereboot.github.io/charts
helm repo update
helm upgrade --reuse-values kured kubereboot/kured -n kube-system --version '<NEW_VERSION>'values.yaml:
# Documentation: https://artifacthub.io/packages/helm/kured/kured
configuration:
timeZone: Europe/Berlin
startTime: 1am
endTime: 5am
rebootDays:
- mo
- tu
- we
- th
- fr
- sa
- su
tolerations:
- key: CriticalAddonsOnly
operator: Exists- Available versions: https://artifacthub.io/packages/helm/metrics-server/metrics-server
- Update instructions: https://github.com/kubernetes-sigs/metrics-server
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm repo update
helm upgrade --reuse-values metrics-server metrics-server/metrics-server -n kube-system --version '<NEW_VERSION>'values.yaml:
# Documentation: https://artifacthub.io/packages/helm/metrics-server/metrics-server- Available versions: https://github.com/rancher/charts/tree/dev-v2.9/charts/system-upgrade-controller
- Update instructions: https://github.com/rancher/system-upgrade-controller
helm repo add rancher https://charts.rancher.io
helm repo update
helm upgrade --reuse-values system-upgrade-controller rancher/system-upgrade-controller -n cattle-system --version '<NEW_VERSION>'values.yaml:
# Documentation: https://github.com/rancher/system-upgrade-controller
# Documentation: https://github.com/rancher/charts/tree/dev-v2.9/charts/system-upgrade-controller
global:
cattle:
psp:
enabled: falseAfter applying the Terraform plan you'll see several output variables like the load balancer's, control plane's, and node pools' IP addresses.
terraform destroy -forceBe sure to clean up any CSI created Block Storage Volumes, and CCM created NodeBalancers that you no longer require.
Ensure gateway is set up correctly: ./ssh-node gateway
iptables -L -t nat
# Expected output:
# Chain PREROUTING (policy ACCEPT)
# target prot opt source destination
#
# Chain INPUT (policy ACCEPT)
# target prot opt source destination
#
# Chain OUTPUT (policy ACCEPT)
# target prot opt source destination
#
# Chain POSTROUTING (policy ACCEPT)
# target prot opt source destination
# MASQUERADE all -- 10.0.1.0/24 anywhereufw status
# Expected output:
# Status: active
#
# To Action From
# -- ------ ----
# 22,6443/tcp ALLOW Anywhere
# 22,6443/tcp (v6) ALLOW Anywhere (v6)
#
# Anywhere on eth0 ALLOW FWD Anywhere on ens10
# Anywhere (v6) on eth0 ALLOW FWD Anywhere (v6) on ens10ufw statusdate
echo $LANG# Retrieve status
cloud-init status
# Verify configuration
cloud-init schema --system
# Collect logs for inspection
cloud-init collect-logs
tar xvzf cloud-init.tar.gz
# Inspect cloud-init.log for error messages
# Quickly find runcmd
find /var/lib/cloud/instances -name runcmd
sh -ex PATH_TO_RUNCMDEnsure cluster is set up correctly: ./ssh-node cluster
ip r s
# Expected output:
# default via 10.0.0.1 dev ens10 proto static onlink <-- this is the important line
# 10.0.0.0/8 via 10.0.0.1 dev ens10 proto dhcp src 10.0.1.2 metric 1024
# 10.0.0.1 dev ens10 proto dhcp scope link src 10.0.1.2 metric 1024
# 169.254.169.254 via 10.0.0.1 dev ens10 proto dhcp src 10.0.1.2 metric 1024ping 1.1.1.1
# Expected output:
# PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
# 64 bytes from 1.1.1.1: icmp_seq=1 ttl=53 time=4.60 ms
# 64 bytes from 1.1.1.1: icmp_seq=2 ttl=53 time=6.82 ms
# ...host k3s.io
# Expected output:
# k3s.io has address 185.199.108.153
# k3s.io has address 185.199.110.153
# k3s.io has address 185.199.111.153
# k3s.io has address 185.199.109.153
# ...k3s kubectl get nodes
# Expected output:
# k3s.io has address 185.199.108.153
# k3s.io has address 185.199.110.153
# k3s.io has address 185.199.111.153
# k3s.io has address 185.199.109.153
# ...This command only works after installing the cilium cli.
cilium status
# Expected output:
# /¯¯\
# /¯¯\__/¯¯\ Cilium: OK
# \__/¯¯\__/ Operator: OK
# /¯¯\__/¯¯\ Envoy DaemonSet: disabled (using embedded mode)
# \__/¯¯\__/ Hubble Relay: disabled
# \__/ ClusterMesh: disabled
#
# Deployment cilium-operator Desired: 1, Ready: 1/1, Available: 1/1
# DaemonSet cilium Desired: 3, Ready: 3/3, Available: 3/3
# Containers: cilium Running: 3
# cilium-operator Running: 1
# Cluster Pods: 9/9 managed by Cilium
# Helm chart version: 1.14.5
# Image versions cilium quay.io/cilium/cilium:v1.14.5@sha256:d3b287029755b6a47dee01420e2ea469469f1b174a2089c10af7e5e9289ef05b: 3
# cilium-operator quay.io/cilium/operator-generic:v1.14.5@sha256:303f9076bdc73b3fc32aaedee64a14f6f44c8bb08ee9e3956d443021103ebe7a: 1This command only works out of the box on the first node of the control plane
node pool with the cluster_can_init setting.
k3s check-config
# Expected output:
# ...
# STATUS: passsystemctl status k3s.service
journalctl -u k3s.service- hcloud-kube-hetzner very popular k3s stack based on openSUSE MicroOS.
- hcloud-k3s Original project that this project has been forked from.
- hetzner-cloud-k3s A fully
functional, super cheap Kubernetes cluster in Hetzner Cloud in 1m30s or less
- Not terraform-based.
- Scripts that make it easy to manage a cluster.
- hetzner-k3s A CLI tool to create
and manage Kubernetes clusters in Hetzner Cloud using the lightweight
distribution k3s by Rancher. Successor of
hetzner-cloud-k3s.
- Not terraform-based.
- k-andy Zero friction Kubernetes stack
on Hetzner Cloud.
- Terraform-based stack.
- Distributed across multiple Hetzner sites and data centers.
- Support for multiple control-plane servers.
- terraform-hcloud-kube-hetzner. Optimized and Maintenance-free Kubernetes on Hetzner Cloud in one command!
- The initiators of and contributors to this project for getting the k3s cluster running via terraform.
- And to God for providing and enabling me to do my share of this work. Solo Deo Gloria.