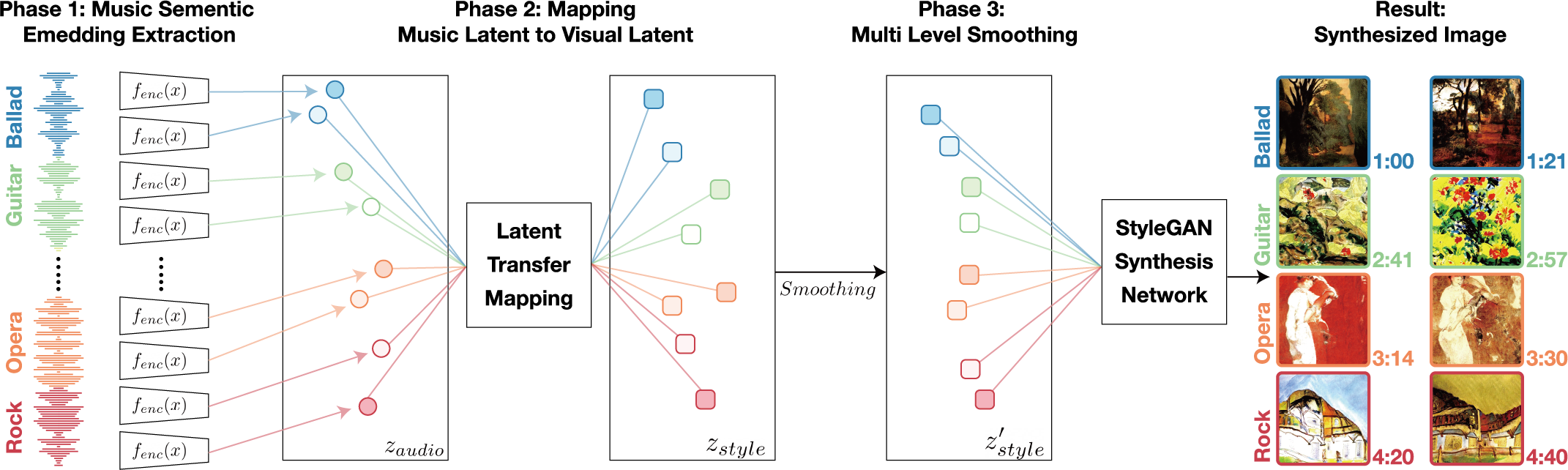
This is repository for TräumerAI: Dreaming Music with StyleGAN, which is submitted to NeurIPS 2020 Workshop for Creativity and Design The model will automatically generate a music visualization video for the selected audio input, using StyleGAN2 trained with WikiArt and audio-visual mapping based on our manual-labeled data pairs.
The model was tested on following environment
- PyTorch == 1.6.0
- cuda == 10.1
These are required Python libraries
- pydub==0.24.1
- librosa==0.8.0
- numba==0.48
- torchaudio==0.6.0
- ninja==1.10.0.post2
- av==8.0.2
During the video generation, ffmpeg command is used. If ffmpeg is not installed, please install ffmpeg as follow:
$ sudo apt-get update
$ sudo apt-get install ffmpeg
This repository uses submodule for music embedder.
$ git submodule init
$ python3 generate.py --audio_path sample/song_a.mp3 sample/song_b.mp3 --fps=30 --audio_fps=5
- --audio_path: input audio file for generating video. several files can be used as inputs
- --fps: frame per second of the generated video. default=15
- --bitrate: bitrate (video quality) of the generated video. default=1e7
- --audio_fps: frame per second for audio embedding (Assert fps % audio_fps == 0). default==3
The generated video will be saved in sample/ .
We have tested input files in m4a and mp3. Currently only 16 bit audio file is supported. Otherwise, the audio will not be decoded correctly.
The weights for the WikiArt pre-trained model is available here. The origin source is https://github.com/pbaylies/stylegan2 which is converted from TensorFlow to PyTorch
The npy data of 100 pairs of music clip and selected image among generation is available here
The pre-trained model is from https://github.com/pbaylies/stylegan2
The PyTorch implementation of StyleGAN2 and the following explanation is from https://github.com/rosinality/stylegan2-pytorch
Model details and custom CUDA kernel codes are from official repostiories: https://github.com/NVlabs/stylegan2
Codes for Learned Perceptual Image Patch Similarity, LPIPS came from https://github.com/richzhang/PerceptualSimilarity
To match FID scores more closely to tensorflow official implementations, I have used FID Inception V3 implementations in https://github.com/mseitzer/pytorch-fid