Pytorch implementation of Online hyperparameter optimization (OHO) code provided by Daniel Jiwoong Im, Cristina Savin, and Kyunghyun Cho.
An online hyperparameter optimization algorithm that is asymptotically exact and computationally tractable, both theoretically and practically. Our framework takes advantage of the analogy between hyperparameter optimization and parameter learning in recurrent neural networks (RNNs). It adapts a well-studied family of online learning algorithms for RNNs to tune hyperparameters and network parameters simultaneously, without repeatedly rolling out iterative optimization. This procedure yields systematically better generalization performance compared to standard methods, at a fraction of wallclock time. (https://arxiv.org/abs/2102.07813)
For more information, see
@article{Im2021OHO,
title={Online hyperparameter optimization by real-time recurrent learning},
author={Im, Daniel Jiwoong and Savin, Christina and Cho, Kyunghyun},
journal={arXiv preprint arXiv:2102.07813},
year={2021}
}If you use this in your research, we kindly ask that you cite the above arxiv paper.
Packages
pip install -e .
Entry code for MNIST:
cd metaopt/mnist
## Global-OHO
python -u main.py --is_cuda 1 --mlr 0.00001 --lr 0.1 --lambda_l2 0.0000 --opt_type sgd --update_freq 1 --save 1 --model_type mlp --num_epoch 100 --batch_size_vl 100 --save_dir [YOUR DIRECTORY]
## Full-OHO (hyperparameter sets per every layer)
python -u main.py --is_cuda 1 --mlr 0.00001 --lr 0.1 --lambda_l2 0.0000 --opt_type sgd --update_freq 1 --save 1 --model_type amlp --num_epoch 100 --batch_size_vl 100 --save_dir [YOUR DIRECTORY]
## Layer-wise OHO
python -u main_quotient.py --opt_type sgd --mlr 0.000001 --lr 0.1 --lambda_l2 0.0 --save 1 --num_epoch 100 --batch_size_vl 100 --update_freq 1 --reset_freq 0 --num_hlayers 4 --save_dir [YOUR DIRECTORY]
Entry code for CIFAR10
cd metaopt/cifar
## Global-OHO
python -u main.py --is_cuda 1 --ifold 0 --mlr 0.00001 --lr 0.1 --lambda_l2 0.0000 --opt_type sgd --update_freq 1 --save 1 --model_type rez18 --num_epoch 300 --batch_size_vl 1000 --update_lambda 1 --save_dir [YOUR DIRECTORY]
## Full-OHO (hyperparameter sets per every layer)
python -u main.py --is_cuda 1 --ifold 0 --mlr 0.00001 --lr 0.1 --lambda_l2 0.0000 --opt_type sgd --update_freq 1 --save 1 --model_type arez18 --num_epoch 300 --batch_size_vl 1000 --update_lambda 1 --save_dir [YOUR DIRECTORY]
## Layer-wise OHO
python -u main_quotient.py --opt_type sgd --mlr 0.000005 --lr 0.01 --lambda_l2 0.0000 --opt_type sgd --update_freq 1 --batch_size_vl 1000 --update_lambda 1 --save 1 --save_dir [YOUR DIRECTORY]
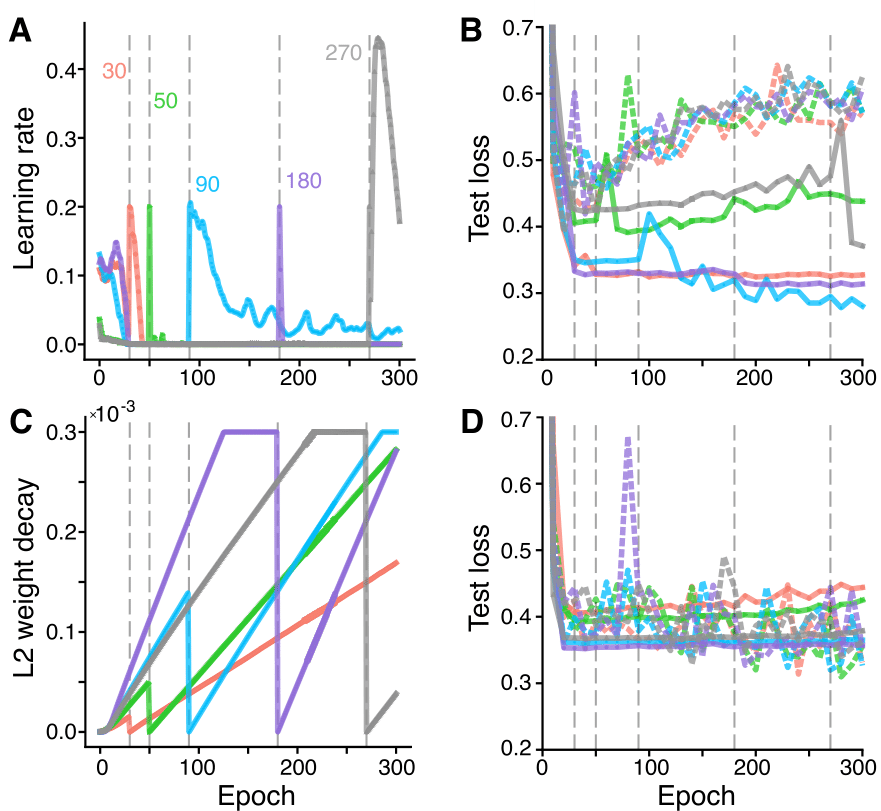
The performance against random search and Bayeisan hyper-parameter optimization :
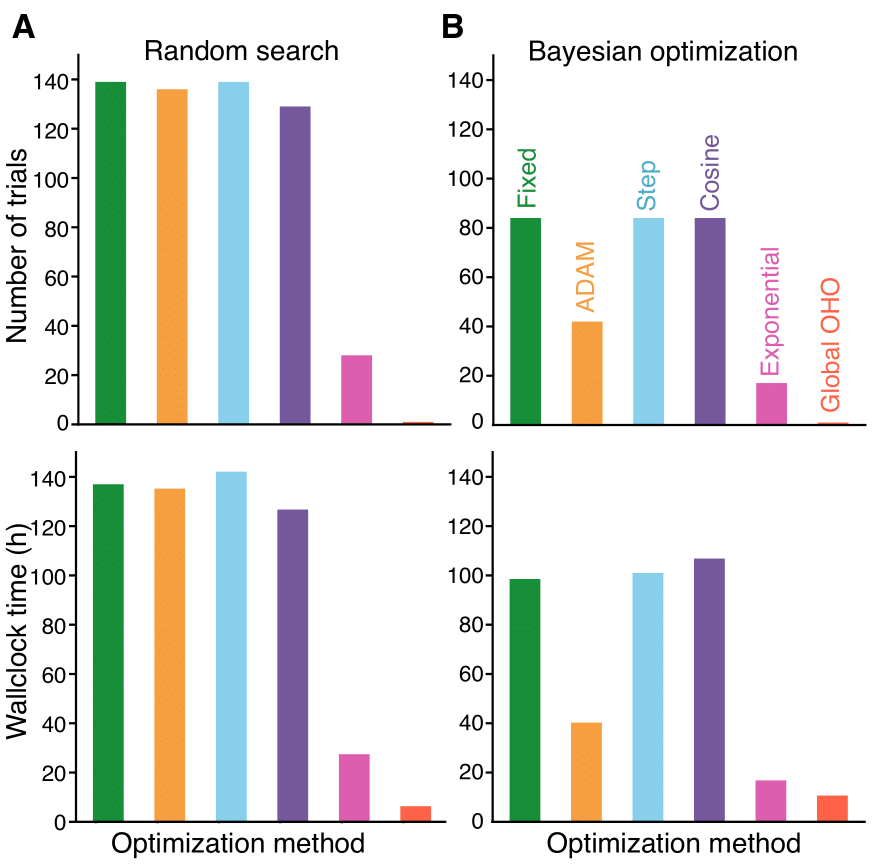
The test loss distribution over hyper-parameters
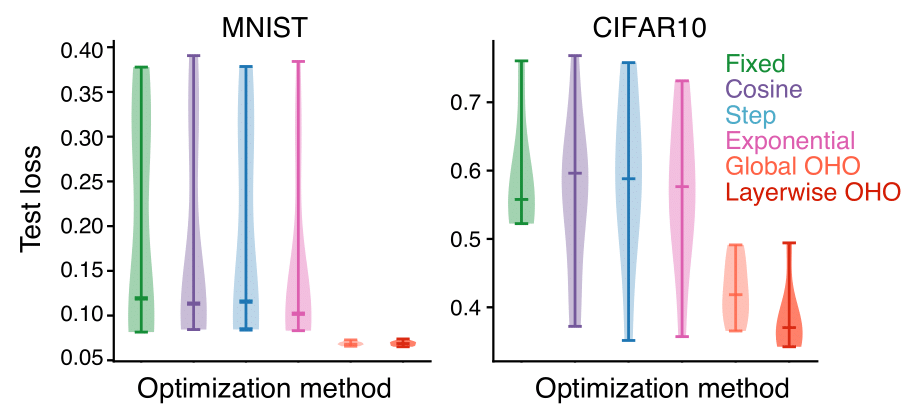
The performance ranging from Global-OHO and Layerwise-OHO
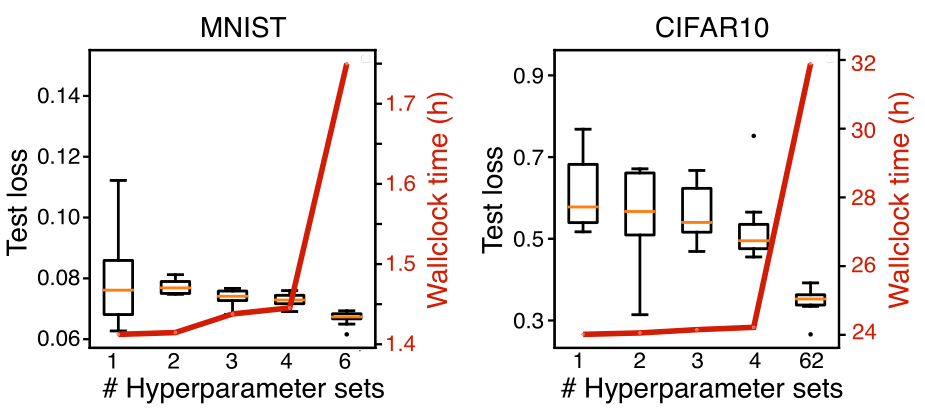
The resiliency demo