


Table of Contents
- Status
- Running Cockroach
- Get in touch
- Contributing
- Design and Datastore Goal Articulation
- Architecture and Client Architecture

ALPHA
- Gossip network
- Distributed transactions
- Cluster initialization and joining
- Basic Key-Value REST API
- Range splitting
Next Steps
- Raft consensus
- Rebalancing
Getting started is most convenient using a recent version (>1.2) of Docker.
If you don't want to use Docker,
- set up the dev environment (see CONTRIBUTING.md)
make build- ignore the initial calls to
dockerbelow.
Getting a Cockroach node up and running is easy. If you have the cockroach binary, skip over the next shell session. Most users however will want to run the following:
# Get the latest image from the registry. Skip if you already have an image
# or if you built it yourself.
$ docker pull cockroachdb/cockroach
[...]
# Open a shell on a Cockroach container.
$ docker run -t -i -p 8080:8080 cockroachdb/cockroach shell
root@82cb657cdc42:/cockroach#Now we're in an environment that has everything set up, and we start by firing up a node:
$ ./cockroach init -stores ssd="$(mktemp -d /tmp/dbXXX)" &> node.log &
[...]This bootstraps and starts a single-node cluster in the background, with logs sent to node.log.
Now let's talk to this node. The easiest way to do that is to use the cockroach binary - it comes with a simple built-in client:
# Put the values a->1, b->2, c->3, d->4.
$ ./cockroach put a 1 b 2 c 3 d 4
$ ./cockroach scan
"a" 1
"b" 2
"c" 3
"d" 4
# Scans do not include the end key.
$ ./cockroach scan b d
"b" 2
"c" 3
$ ./cockroach del c
$ ./cockroach scan
"a" 1
"b" 2
"d" 4
# Counters are also available:
$ ./cockroach inc mycnt 5
5
$ ./cockroach inc mycnt -3
2
$ ./cockroach get mycnt
2
Check out ./cockroach help to see all available commands.
Cockroach also exposes a REST API. You can use the REST Explorer at localhost:8080 or talk directly to it. Note that if you're using the Docker container, you want to do this in a new shell and not inside the container, which does not have cURL installed.
$ curl -X POST -d "Hello" http://localhost:8080/kv/rest/entry/Cockroach{"header":{"timestamp":{"wall_time":1416616834949813367,"logical":0}}}$ curl http://localhost:8080/kv/rest/entry/Cockroach{"header":{"timestamp":{"wall_time":1416616886486257568,"logical":0}},"value":{"bytes":"SGVsbG8=","timestamp":{"wall_time":1416616834949813367,"logical":0}}}Note that SGVsbG8= equals base64("Hello").
Among other things, you can also scan a key range:
$ curl "http://localhost:8080/kv/rest/range/?start=Ca&end=Cozz&limit=10"{"header":{"timestamp":{"wall_time":1416617120031733436,"logical":0}},"rows":[{"key":"Q29ja3JvYWNo","value":{"bytes":"SGVsbG8=","timestamp":{"wall_time":1416616834949813367,"logical":0}}}]}Note that Q29ja3JvYWNo equals base64("Cockroach").
See build/README.md for more information on the available Docker
images cockroachdb/cockroach and cockroachdb/cockroach-dev.
You can build both of these images yourself:
cockroachdb/cockroach-dev:(cd build ; ./build-docker-dev.sh)cockroachdb/cockroach:(cd build ; ./build-docker-deploy.sh)(this will build the first image as well)
Once you've built your image, you may want to run the tests:
docker run "cockroachdb/cockroach-dev" testmake acceptance
Assuming you've built cockroachdb/cockroach, let's run a simple Cockroach node in the background:
$ docker run -p 8080:8080 -d cockroachdb/cockroach init \
-stores ssd="$(mktemp -d /tmp/dbXXX)"Run docker run cockroachdb/cockroach help to get an overview over the available commands and settings, and see Running Cockroach for first steps on interacting with your new node.
- cockroach-db@googlegroups.com
- #cockroachdb on freenode
See CONTRIBUTING.md
For full design details, see the original design doc.
For a quick design overview, see the Cockroach tech talk slides or watch a presentation:
- Venue: Yelp!, Presented by Spencer Kimball on (9/5/2014).
- Venue: The NoSQL User Group Cologne, Presented by Tobias Schottdorf on (11/5/2014).
- Venue: The Go Devroom FOSDEM 2015, Presented by Tobias Schottdorf on (03/04/2015).
Cockroach is a distributed key/value datastore which supports ACID transactional semantics and versioned values as first-class features. The primary design goal is global consistency and survivability, hence the name. Cockroach aims to tolerate disk, machine, rack, and even datacenter failures with minimal latency disruption and no manual intervention. Cockroach nodes are symmetric; a design goal is one binary with minimal configuration and no required auxiliary services.
Cockroach implements a single, monolithic sorted map from key to value where both keys and values are byte strings (not unicode). Cockroach scales linearly (theoretically up to 4 exabytes (4E) of logical data). The map is composed of one or more ranges and each range is backed by data stored in RocksDB (a variant of LevelDB), and is replicated to a total of three or more cockroach servers. Ranges are defined by start and end keys. Ranges are merged and split to maintain total byte size within a globally configurable min/max size interval. Range sizes default to target 64M in order to facilitate quick splits and merges and to distribute load at hotspots within a key range. Range replicas are intended to be located in disparate datacenters for survivability (e.g. { US-East, US-West, Japan }, { Ireland, US-East, US-West}, { Ireland, US-East, US-West, Japan, Australia }).
Single mutations to ranges are mediated via an instance of a distributed consensus algorithm to ensure consistency. We’ve chosen to use the Raft consensus algorithm. All consensus state is stored in RocksDB.
A single logical mutation may affect multiple key/value pairs. Logical mutations have ACID transactional semantics. If all keys affected by a logical mutation fall within the same range, atomicity and consistency are guaranteed by Raft; this is the fast commit path. Otherwise, a non-locking distributed commit protocol is employed between affected ranges.
Cockroach provides snapshot isolation (SI) and serializable snapshot isolation (SSI) semantics, allowing externally consistent, lock-free reads and writes--both from an historical snapshot timestamp and from the current wall clock time. SI provides lock-free reads and writes but still allows write skew. SSI eliminates write skew, but introduces a performance hit in the case of a contentious system. SSI is the default isolation; clients must consciously decide to trade correctness for performance. Cockroach implements a limited form of linearalizability, providing ordering for any observer or chain of observers.
Similar to Spanner directories, Cockroach allows configuration of arbitrary zones of data. This allows replication factor, storage device type, and/or datacenter location to be chosen to optimize performance and/or availability. Unlike Spanner, zones are monolithic and don’t allow movement of fine grained data on the level of entity groups.
A Megastore-like message queue mechanism is also provided to 1) efficiently sideline updates which can tolerate asynchronous execution and 2) provide an integrated message queuing system for asynchronous communication between distributed system components.

There are other important axes involved in data-stores which are less well understood and/or explained. There is lots of cross-dependency, but it's safe to segregate two more of them as (a) scan efficiency, and (b) read vs write optimization.
Scan efficiency refers to the number of IO ops required to scan a set of sorted adjacent rows matching a criteria. However, it's a complicated topic, because of the options (or lack of options) for controlling physical order in different systems.
- Some designs either default to or only support "heap organized" physical records (Oracle, MySQL, Postgres, SQLite, MongoDB). In this design, a naive sorted-scan of an index involves one IO op per record.
- In these systems it's possible to "fully cover" a sorted-query in an index with some write-amplification.
- In some systems it's possible to put the primary record data in a sorted btree instead of a heap-table (default in MySQL/Innodb, option in Oracle).
- Sorted-order LSM NoSQL could be considered index-organized-tables, with efficient scans by the row-key. (HBase).
- Some NoSQL is not optimized for sorted-order retrieval, because of hash-bucketing, primarily based on the Dynamo design. (Cassandra, Riak)

Read vs write optimization is a product of the underlying sorted-order data-structure used. Btrees are read-optimized. Hybrid write-deferred trees are a balance of read-and-write optimizations (shuttle-trees, fractal-trees, stratified-trees). LSM separates write-incorporation into a separate step, offering a tunable amount of read-to-write optimization. An "ideal" LSM at 0%-write-incorporation is a log, and at 100%-write-incorporation is a btree.
The topic of LSM is confused by the fact that LSM is not an algorithm, but a design pattern, and usage of LSM is hindered by the lack of a de-facto optimal LSM design. LevelDB/RocksDB is one of the more practical LSM implementations, but it is far from optimal. Popular text-indicies like Lucene are non-general purpose instances of write-optimized LSM.
Further, there is a dependency between access pattern (read-modify-write vs blind-write and write-fraction), cache-hitrate, and ideal sorted-order algorithm selection. At a certain write-fraction and read-cache-hitrate, systems achieve higher total throughput with write-optimized designs, at the cost of increased worst-case read latency. As either write-fraction or read-cache-hitrate approaches 1.0, write-optimized designs provide dramatically better sustained system throughput when record-sizes are small relative to IO sizes.
Given this information, data-stores can be sliced by their sorted-order storage algorithm selection. Btree stores are read-optimized (Oracle, SQLServer, Postgres, SQLite2, MySQL, MongoDB, CouchDB), hybrid stores are read-optimized with better write-throughput (Tokutek MySQL/MongoDB), while LSM-variants are write-optimized (HBase, Cassandra, SQLite3/LSM, Cockroach).

Cockroach implements a layered architecture, with various subdirectories implementing layers as appropriate. The highest level of abstraction is the SQL layer (currently not implemented). It depends directly on the structured data API (structured/). The structured data API provides familiar relational concepts such as schemas, tables, columns, and indexes. The structured data API in turn depends on the distributed key value store (kv/). The distributed key value store handles the details of range addressing to provide the abstraction of a single, monolithic key value store. It communicates with any number of cockroach nodes (server/), storing the actual data. Each node contains one or more stores (storage/), one per physical device.
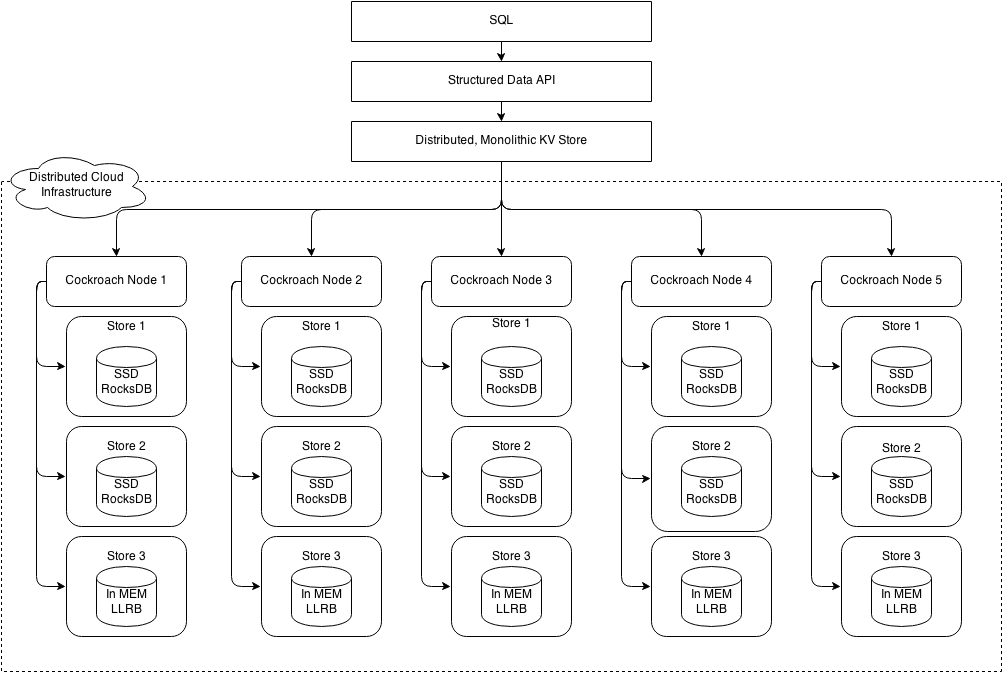
Each store contains potentially many ranges, the lowest-level unit of key-value data. Ranges are replicated using the Raft consensus protocol. The diagram below is a blown up version of stores from four of the five nodes in the previous diagram. Each range is replicated three ways using raft. The color coding shows associated range replicas.

Cockroach nodes serve client traffic on two primary HTTP endpoints: a RESTful endpoint which treats key/value pairs and sequences of key/value pairs as resources; and a fully-featured key/value DB API which accepts requests as either application/x-protobuf or application/json. Client implementations consist of an HTTP sender (transport) and a transactional sender which implements a simple exponential backoff / retry protocol, depending on Cockroach error codes.
The REST and DB client gateways accept incoming requests and send them through a transaction coordinator, which handles transaction heartbeats on behalf of clients, provides optimization pathways, and resolves write intents on transaction commit or abort. The transaction coordinator passes requests onto a distributed sender, which looks up index metadata, caches the results, and routes internode RPC traffic based on where the index metadata indicates keys are located in the distributed cluster.
In addition to the gateways for external REST and DB client traffic, each Cockroach node provides the full key/value API (including all internal methods) via a Go RPC server endpoint. The RPC server endpoint forwards requests to one or more local stores depending on the specified key range.
Internally, each Cockroach node uses the Go implementation of the Cockroach client in order to transactionally update system key/value data; for example during split and merge operations to update index metadata records. Unlike an external application, the internal client eschews the HTTP sender and instead directly shares the transaction coordinator and distributed sender used by the REST and DB client gateways.
