{kind=link}
This project is a versatile web scraping tool with two interfaces: a Flask-based web application and a terminal-based script. Both tools are designed to scrape various types of content from a specified URL and save them to designated folders.
-
Web Application:
- Scrapes text from
<p>and header tags (<h1>,<h2>, etc.) - Extracts all hyperlinks from the page
- Downloads images, videos, audio files, and documents based on user selection
- Saves scraped content to specified folders
- Provides a user-friendly interface for scraping configuration
- Scrapes text from
-
Terminal Script:
- Allows scraping of text, links, and media (images, videos, audio files) directly from the terminal
- Asks for the URL, types of content to scrape, and the locations to save the scraped content
- Python 3.x
- Flask
- Requests
- BeautifulSoup4
-
Clone the repository:
git clone https://github.com/mandarwagh9/web-scraper.git cd web-scraper -
Create and activate a virtual environment (optional but recommended):
python -m venv venv source venv/bin/activate # On Windows use `venv\Scripts\activate`
-
Install the required packages:
pip install -r requirements.txt
Create a requirements.txt file with the following content:
Flask==2.2.2
requests==2.28.2
beautifulsoup4==4.12.2
-
Run the Flask application:
python app.py
-
Open your web browser and navigate to:
http://127.0.0.1:5000 -
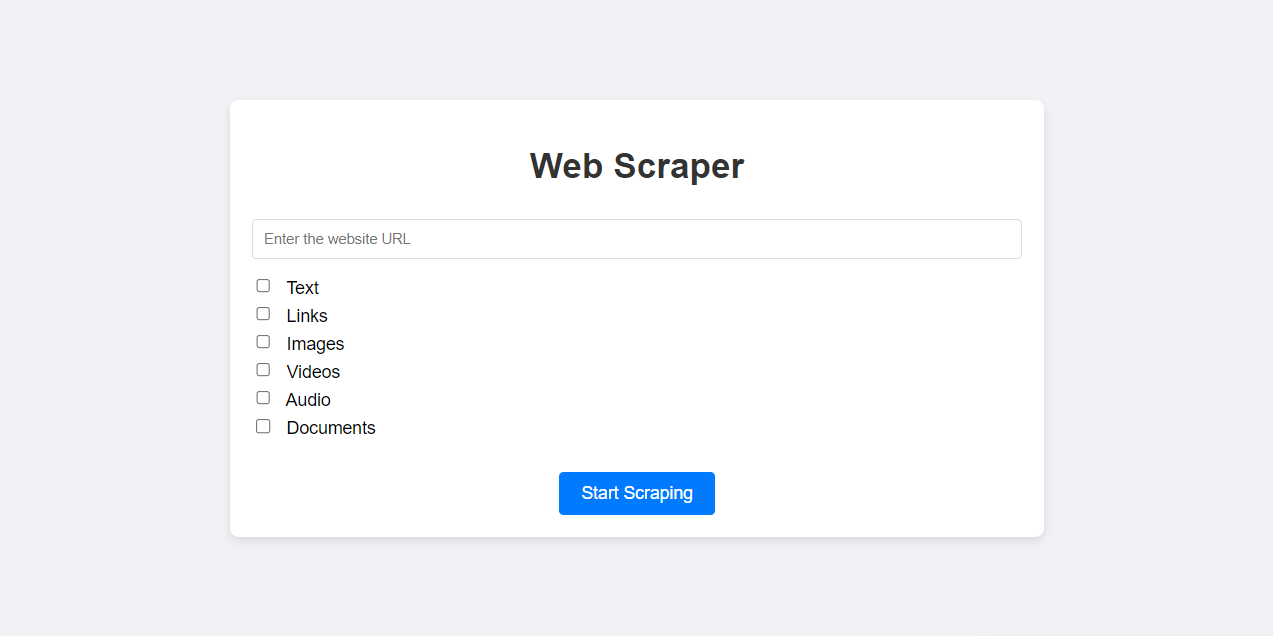
Use the form to specify the URL and choose the types of content you want to scrape. You can select:
- Text
- Links
- Images
- Videos
- Audio
- Documents
-
Specify the folders where you want to save each type of content. For optional fields, leave them blank if you don't want to save that type of content.
-
Click the "Start Scraping" button to begin the scraping process. A popup will appear to notify you when the scraping is complete.
-
Run the terminal script:
python terminal_scraper.py
-
Follow the prompts in the terminal:
- Enter the URL to scrape
- Choose the types of content you want to scrape by entering the corresponding numbers (e.g., text, links, media)
- Provide the folder names for each type of content (if applicable)
-
The script will process the URL and save the scraped content to the specified folders. You will be notified once the scraping is complete.
Feel free to submit issues or pull requests. Please make sure to follow the coding style and include relevant tests with your contributions.
- Fork the repository
- Create a new branch (
git checkout -b feature-branch) - Commit your changes (
git commit -am 'Add new feature') - Push to the branch (
git push origin feature-branch) - Create a new Pull Request
This project is licensed under the MIT License - see the LICENSE file for details.
Let me know if there's anything else you'd like to add or adjust!