{kind=link}
Our GitHub repository showcases a pioneering project titled "Speech Emotion Recognition System with CNN and MFCC"—an innovative approach to real-time emotion detection from audio signals. By harnessing the power of Convolutional Neural Networks (CNN) and the effectiveness of Mel Frequency Cepstral Coefficients (MFCC), this project seeks to advance the field of emotion recognition technology.
Emotions are fundamental to human communication and interaction. Accurately identifying and interpreting emotions in real-time scenarios is a complex challenge with profound implications across various sectors, including human-computer interaction, mental health, customer service, and entertainment.
This project, implemented in Python 3 using Jupyter Notebook and TensorFlow Keras, the project is developed as a web application using Streamlit, offering two prediction options: uploading audio files and recording audio directly within the Streamlit application. Users can upload audio files in WAV and MP3 formats with unlimited file uploads and a maximum file size of 200 MB for emotion prediction. Additionally, users can record their audio directly within the Streamlit application, with the system predicting the emotion from the recorded audio. The recording is limited to a duration of up to 10 seconds.
The heart of our system lies in the integration of MFCC, a robust technique for feature extraction from audio signals. MFCC captures the power spectrum of a sound, enabling the system to detect subtle nuances in speech that correspond to different emotional states. The features extracted by MFCC are fed into a CNN, which excels at identifying complex patterns and making accurate classifications.
- Zero Crossing Rate (ZCR): Measures how often the audio signal crosses the zero line, useful for distinguishing types of sounds like speech and music.
- Chroma STFT: Captures the harmonic content of the audio signal, useful for identifying pitches and chords in music.
- Mel-frequency Cepstral Coefficients (MFCC): Represents the short-term power spectrum of the audio signal, widely used in speech and music recognition.
- Root Mean Square Energy (RMSE): Measures the energy of the audio signal, indicating the loudness or intensity of the sound.
- Spectral Contrast: Measures the difference between peaks and valleys in the spectrum, useful for identifying timbral textures and harmonic characteristics.
- Spectral Contrast: Measures the difference between peaks and valleys in the spectrum, useful for identifying timbral textures and harmonic characteristics.
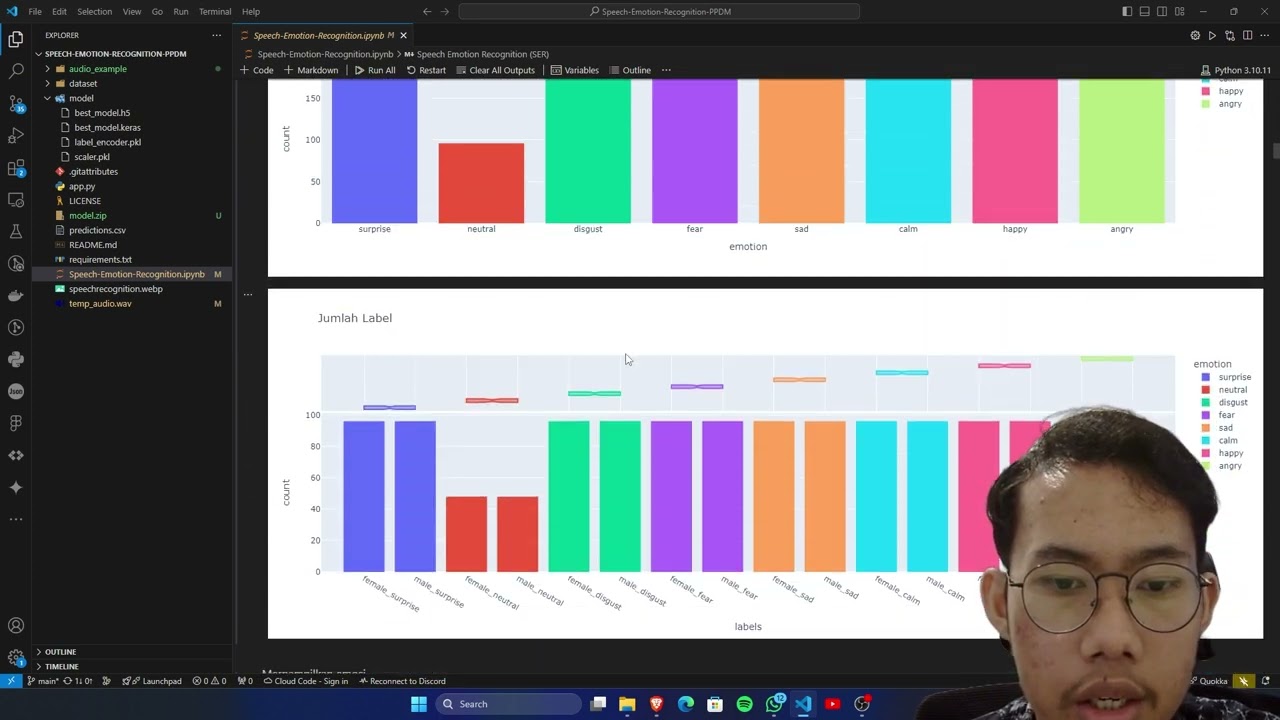
Our model is trained on the RAVDESS (Ryerson Audio-Visual Database of Emotional Speech and Song) dataset. This dataset is renowned for its high-quality recordings and diverse emotional expressions, providing a solid foundation for training and evaluating our emotion recognition system. RAVDESS includes a wide range of emotions expressed through speech, such as calm, happy, sad, angry, fearful, disgusted, surprised, and neutral.
Source: RAVDESS
To use this project, follow these steps below:
-
Clone the repository or download az ZIP because model has big file size:
git clone https://github.com/mdprana/Speech-Emotion-Recognition-PPDM.git
cd Speech-Emotion-Recognition-PPDM -
Install dependencies from requirements.txt:
pip install -r requirements.txt
-
Adjust the path location with your path (optional)
# Adjust the model path scaler = load('..yourpath/scaler.pkl') encoder = load('..yourpath/label_encoder.pkl') model = load_model('..yourpath/best_model.h5') # Adjsut the image path st.image('..yourpath/speechrecognition.webp')
-
Run the Streamlit application:
streamlit run app.py
-
You can upload and make prediction using audio from
example_audiofolder
Upload Audio Section

Emotion Prediction with Single audio file upload

Emotion Prediction with Multiple audio file upload

Record Audio Section

Emotion Recognition with Record Audio

This project represents a significant step forward in the field of emotion recognition, offering a powerful tool for understanding human emotions through speech. Explore our GitHub Repository for more project.
Mata Kuliah Pengantar Pemrosesan Data Multimedia
Program Studi Informatika
Universitas Udayana
Tahun Ajaran 2023/2024