prenet dropout #50
Comments
|
@xinqipony I never tried to dropout at inference time. However, I think, it shouldn't make a difference. Maybe the way to handle dropout at inference time is somehow wrong at the repo. |
|
It happened as I train TTS with r=1. Attention does not align if I don't run |
|
hi erogol, thanks for your updates, I also tried some solutions to solve this, |
|
Another option would be using last 5 frames as input to prenet, so we know r=5 works just fine, |
|
but in my CMOS test voice quality of r=1 is much better than r > 1, so quality may be impact for r=5 |
|
I have different results currently, mostly alignment does not work well for r=1 due to the above problem. And if I use in train mode in inference, its results are not very reliable since for each run it gives different output due to dropout. |
|
I think the problem here is "dying ReLU". So far, I replaced autoregressive connection with a queue of the last 5 frames instead of feeding only the last frame. It did not change anything but after I also changed PreNet activation function to RReLU and remove dropout things got better. However, I don't know yet if the boost is the combination of the queue and RReLU or just the RReLU. I also higher the learning rate. |
|
@erogol thanks for updates, do you feel voice quality degrade using rrelu and removing dropout thing in inference? cause I tried lrelu, the things are better, but the voice quality is still not good enough as keeping dropout; |
|
so far it is comparable with the original model but it needs more training. How many steps does it take to give good results by your model? |
|
about 120k, I use r=1, activation of prenet is tanh or lrelu, both shows improvement, but not comparable to relu with dropout version, I used wavenet for sample generation, so it sounds more sensitive to me than griffin lim; |
|
@xinqipony which repo do you use for this model ? And do you have loss values to compare? |
|
we write it ourselves original from the tacotron 1 paper and then change to tacotron 2 with tensorflow, input mel is normalized to (-4 , +4) range and the final mse loss would be around 0.13(decoder_loss + mel_loss) |
|
Thx for the details. I use 0, 1 normalization and L1 loss but the architecture is much similar to Tacotron. I found Tacotron2 harder and slower to train., due to the model size. Would you agree? |
|
Sorry to bust into this that late but I had to read the model implementation first. I created a quick schematic for the current decoder to make sure we are all on the same page:
As this discussion seems a bit scattered I would like to gather the information.
Another aspect of the discussion that is not clear to be is:
@ergol what do you refer to when talking about the number of zeros? |
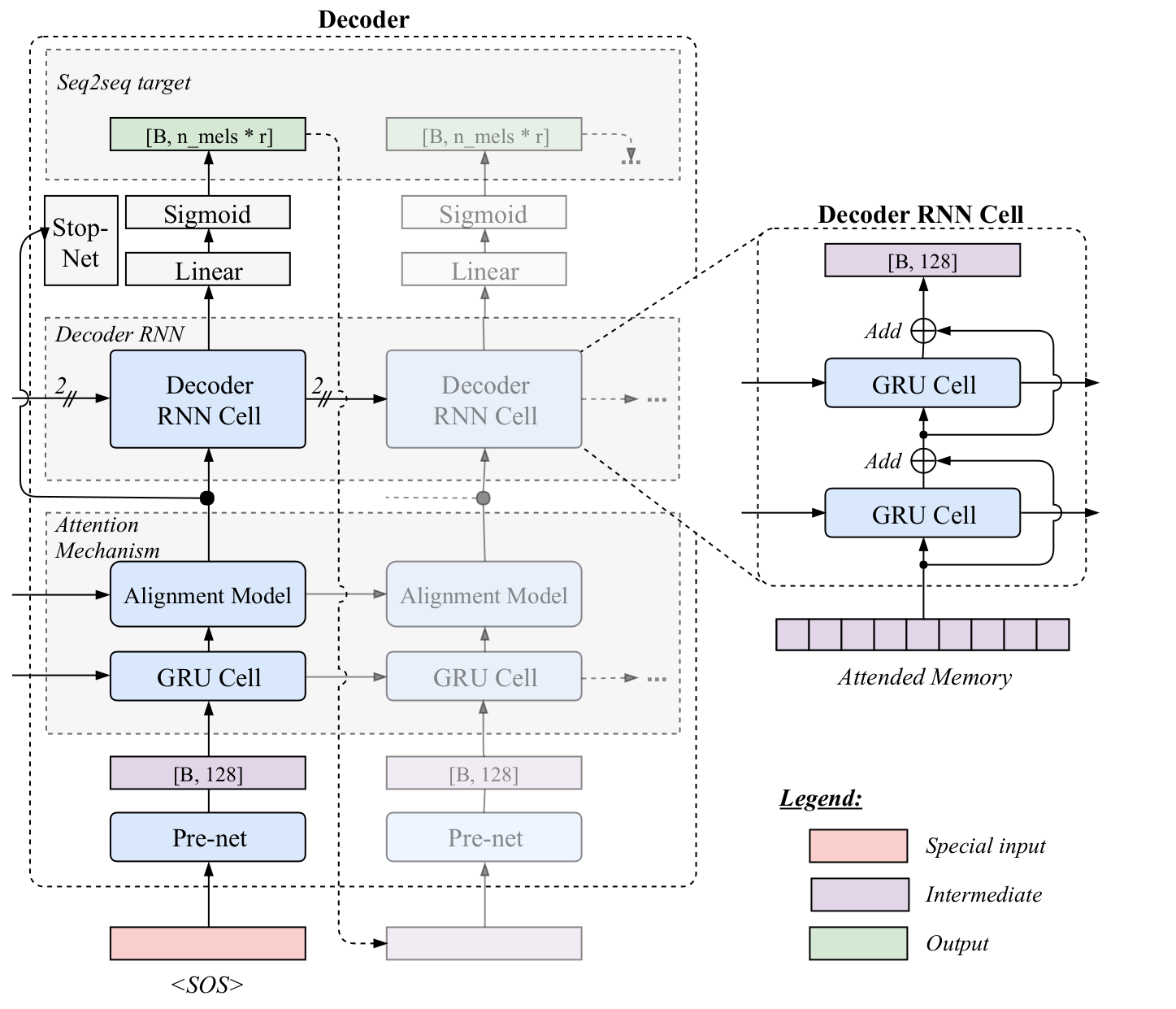
|
@yweweler Your figure depicts TTS decoder perfectly. However, Tacotron2 has some differences. @xinqipony states his findings on Tacotron2. Answer: The best validation mel-spec loss 0.04 -> 0.028 with all these changes. (Note that, I don't know individual effects of each of these updates.)
Answer: The meaning is that, somehow, there is a big difference between number of zero PreNEt outputs between |
Sorry I somehow completely overlooked this.
Could you provide information on the number of training steps and what batch size you used?
That is fairly interesting. I implemented Tacotron 1 myself and experimented with different alignment mechanisms but never hat a similar behavior. |
|
@yweweler here is the config file. This weirdness only happens when r=1. |
yes. |
|
Update: not forgotten yet. |
|
@yweweler the same here, no worries |
|
anyone got better updates on this topic? |
|
@xinqipony I couldn't find anything works better here for all datasets. I like to replace dropout with batchnorm at the next step. I'll share here if it works. |
|
@erogol did you apply the batch norm? I couldn't apply the batch norm for technical reason, so I applied the instance norm, but the resulting audio was horrible, even though the validation loss went significantly lower. |
|
@phypan11 not yet sorry. Probably, attention did not align. Did you compare it? |
|
One solution I found is to train the network with r=5 and then finetune with r=1 with the updates explained here #108 |
|
Here is my solution, very tricky: drop_rate = tf.random_uniform(shape=[1], minval=0, maxval=min(self.drop_rate * 1.5, 0.5), dtype=tf.float32)[0]
x = tf.layers.dropout(dense, rate=drop_rate, training=self.is_training,
name='dropout_{}'.format(i + 1) + self.scope) |
|
@candlewill do you observe voice quality loss? I am trying rrelu, it seems to me the quality has gap; |
|
@candlewill cool you are dropping our dropout :). What was the intuition to come up with that ? |
|
My final solution is to use Batch Normalization in Prenet layer and removing Dropout completely. It works like magic and it also increases the model performance significantly in my case. |
|
Hi @erogol, |
|
Hi @erogol, |
|
@WhiteFu @chapter544 https://github.com/mozilla/TTS/blob/dev-tacotron2/layers/tacotron2.py#L76 |
|
@yweweler , sorry about off-topic, but which was the tool for the #50 (comment) diagram creating? |
I was using another repo previously, and now I am switching to mozilla TTS;
according to my experience, the dropout in decoder prenet also used in inference, without dropout in inference, the quality is bad(tacotron 2), which is hard to understand,
do you get similar experience and why?
The text was updated successfully, but these errors were encountered: