Scanned receipts OCR is a process of recognizing text from scanned structured and semi-structured receipts, and invoice images. It plays a critical role in streamlining document-intensive processes and office automation in many financial,accounting and taxation area. This problem is different from other OCR tasks like(license plate recognition, handwriting recognition) in that it has higher accuracy requirements to be meaningful and viable.

This project takes reference from here . The dataset considered is this where receipt images with corresponding bounding boxes and the annotations are provided. The problem has twosubtasks-
For detection of text we consider a pretrained CTPN and we finetune it on the training receipt images. CTPN is composed of first 5 conv layers of VGG net followed by an LSTM and a fully connected layer. The total stride is 16 here and thus it produces 1/16th times reduced representation of the image. As we are detecting only horizontal data we consider the output from the VGG net where each point of interest acts as the starting point with a width of 16 and we produce k anchors to represent the height of the region of interest. The relevant regions of interest are identified using an IoU threshold of 0.7 and the continuous horizontal regions which are less than 50 pixels apart and have a vertical overlap of 0.7 and greater are merged into a single group of text. In the fully connected layer the model does a multi-task based optimization to predict the y coordinates through a regression loss and classifies it as text/non text based on a classification loss. Precision over the predicted labels and recall over the ground truth labels is used as an evaluation metric.
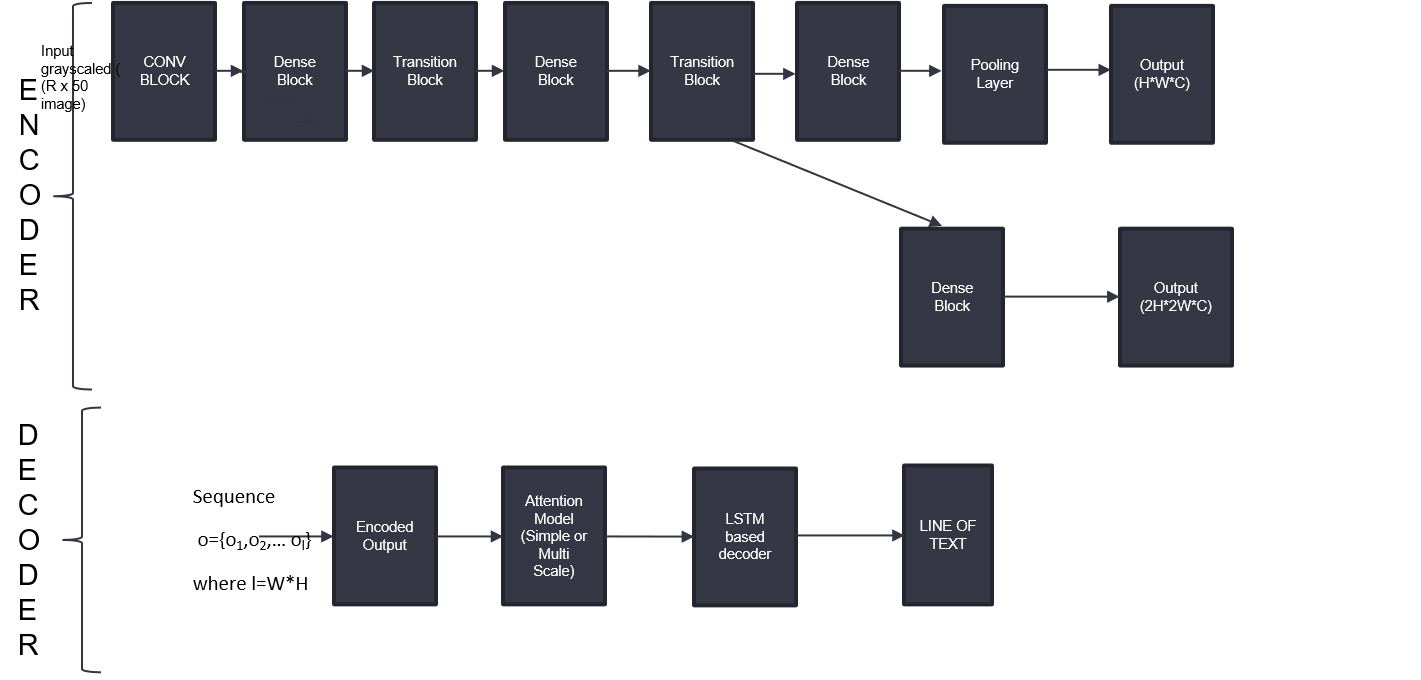
For recognition of text from these localized images which can be alphanumeric or other special characters. The detected bounding boxes of texts are passed through an Attention based Encoder Decoder model to predict the tokens from the character vocabulary in the training dataset. We use a DenseNet based encoder.DenseNet takes as input a grayscaled W X H image and produces the output as W' X H' X C. This can be flattened on the column axis to produce a sequence o={o_{1},o_{2} ... ,o_{l}} where l=(W' * H ') where o_{i} belongs to R^{C} for a single image. Thus the encoder produces a sequence of length l with hidden dimension of C. The decoder uses an LSTM combined with attention which produces the output taking relevant context from the encoder making use of attentions and previous hidden states and character embeddings. Bahdanou attention is used and beam search based decoding is used to produce the target decoded representation. As the DenseNet reduces the height of the image by a factor of 50 when we have growth rate=24 and depth as 16. So as a result the low resolution characters like '.' are lost as a result of pooling the information. So Multi scale attention is also tried with the output representations taken just before the pooling layer concatenated with the original output for the encoder. Recall and Precision is calculated by dividing the number of correct characters by the predictions and the ground truth respectively.
For downloading the pretrained CTPN refer this.
| Text Detection | Precision | Recall |
|---|---|---|
| Single Scale Attention | 77.5 | 77.7 |
| Multi Scale Attention | 78.7 | 80 |



For the text detection part refer the following repo where a pretrained CTPN is available and the same can be finetuned on the receipt images.
Run
pip install -r requirements.txt
to install all the dependencies.
train_dir=r"/home/tejasvi/0325updated.task1train(626p)"
val_dir=r"/home/tejasvi/text.task1_2-test(361p)"
load_model_file=r'./OCR.pt'
max_length=31
row=1000
column=50
n_epochs=15
lr=0.001
bsize=64
embedding_size=180
encoder_dim=180
hidden_size=180
densenet_depth=32
densenet_growthrate=24
For the text recognition part, specify the train_dir and val_dir in Text_Recognition.py. And it can be run using the default parameters. A pretrained model 'OCR.pt' is also provided which works with the default configuration.