Android app to classify hand drawn numbers using Tensorflow machine learning model.
References:
- Tensorflow MNIST Tutorial
- An Intuitive Explanation of CNN
- DeepLearningOnAndroid
- Running Tensorflow models on Anroid
Before creating the App, we must first create a model in tensorflow. The model is created with Python and is then frozen and imported inside Android Studio. The app supports two different classification models; a single layer SoftMax model and a Convolutional Neural Network. The SoftMax model has an final accurary of ~92% while the Convolutional Neural Network increases the accuracy to ~98%.
The SoftMax model code can be found at mnist_model.py.
The input to the model is the MNIST data set, which contains 28x28 pixel images of handwritten numbers. Each image also has a 1 hot vector that defines the class associated with it.

x = tf.placeholder(tf.float32, shape=[None, 784], name='modelInput')
y_ = tf.placeholder(tf.float32, [None, 10],"inputLabels")The weights of the model define how pixel intensity indicates a certain class. For a pixel of high intensity, the weight is positive if it is evidence in favor of the image being in some class and negative if it is not.
W = tf.Variable(tf.zeros([784,10]), name='modelWeights')The bias represents extra evidence that some things are more likely independent of the input. Mathematically, bias allows the activation function to shift to the left or right. A higher bias allows for quicker training but the model is less flexible.
b = tf.Variable(tf.zeros([10]), name='modelBias')The output of the model is given by a layer of SoftMax. This layer acts as an activation function that normalizes the evidence into a probability distribution that an image is in some class. Evidence is given by the function: evidence=x*W + b
y = tf.nn.softmax(tf.matmul(x, W) + b, name='modelOutput')The Convolutional Neural Network model code can be found at mnist_model_cnn.py.
The input of the model is the same as the SoftMax model, except we must reshape the input to use within a convolutional neural net. This is because the tensorflow methods for creating convolutional and pooling layers expect input tensors of shape [batch_size, image_height, image_width, channels].
x_image = tf.reshape(x, [-1, 28, 28, 1])Convolution layers are used to extract features from the input image. They work by convolving a filter around the input image and taking the dot product between them. This produces a feature map.
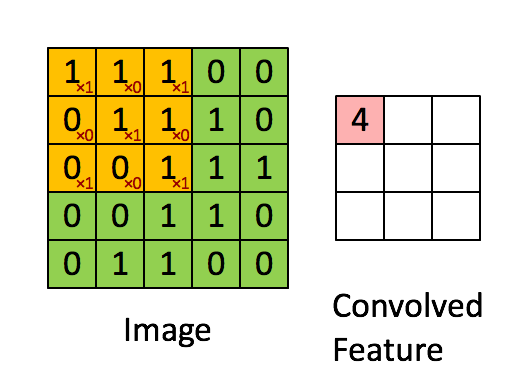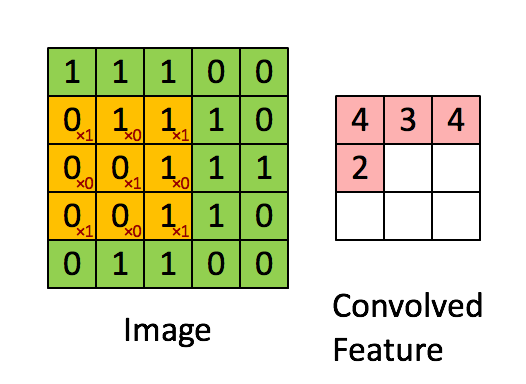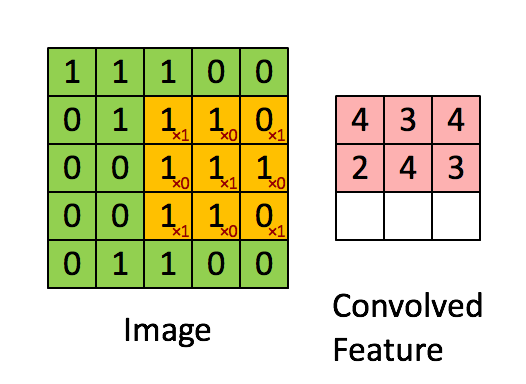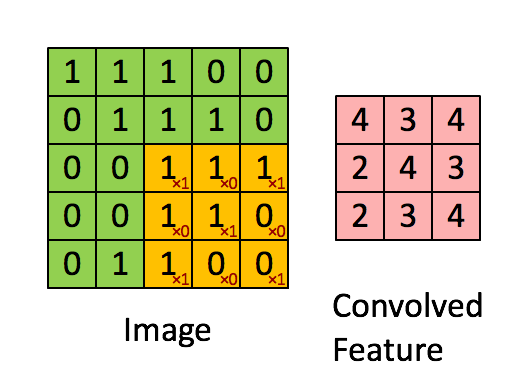
For this layer, we also apply ReLU as the activation function. f(x)=max(0,x)
In this first layer, we are mapping the input image to 32 different 5x5 feature maps.
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)Pooling layers are used to downsample each feature map, while still retaining the most important information. This is mostly done in order to reduce processing time. Pooling layers work by taking the largest value within some defined sub-region of the input data. In this case, we are using a sub-region size of 2x2.

h_pool1 = max_pool_2x2(h_conv1)In this second convolutional layer, we are mapping the output of pooling layer 1 to 64 different 5x5 feature maps.
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)This second pooling layer is used to downsample the output of convolutional layer 2. The shape of h_pool2 at this point should be [number of images, 7, 7, 64], since we created 64 feature maps and downsampled by 2 twice.
h_pool2 = max_pool_2x2(h_conv2)The output of the model is again given by a layer of SoftMax; however, the data is first fed into a fully connected layer which re-shapes it to the output and classifies the input image based on the features created. As the name implies, every node of the previous layer is connected to every node of the next.
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y = tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2, name='modelOutput')In order to train the model, we feed in the training data in batches and periodically feed in some of the test images in order to verify the accuracy of the predictions. Freezing the graph is handled by the tool provided in the tensorflow API.
for i in range(TRAIN_STEPS+1):
print('Training Step:'+str(i))
batch_xs, batch_ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
if i%100==0:
print(' Accuracy = '+ str(sess.run(accuracy, {x: mnist.test.images, y_: mnist.test.labels})*100)+"%" +
' Loss = ' + str(sess.run(cross_entropy, {x: batch_xs, y_: batch_ys}))
)
if i%1000==0:
out = saver.save(sess, SAVED_MODEL_PATH+MODEL_NAME+'.ckpt', global_step=i)
print('Final Accuracy: ' + str(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})))
input_graph = SAVED_MODEL_PATH+MODEL_NAME+'.pb'
input_saver = ""
input_binary = True
input_checkpoint = SAVED_MODEL_PATH+MODEL_NAME+'.ckpt-'+str(TRAIN_STEPS)
output_node_names = 'modelOutput'
restore_op_name = 'save/restore_all'
filename_tensor_name = 'save/Const:0'
output_graph = SAVED_MODEL_PATH+'frozen_'+MODEL_NAME+'.pb'
clear_devices = True
initializer_nodes = ""
freeze_graph.freeze_graph(
input_graph,
input_saver,
input_binary,
input_checkpoint,
output_node_names,
restore_op_name,
filename_tensor_name,
output_graph,
clear_devices,
initializer_nodes,
)