Fix for url.parse() leaving trailing ":" on the protocol/scheme #1580
Conversation
Before:
% node -e 'require("url").parse("http://www.google.com/").protocol'
http:
After:
% node -e 'require("url").parse("http://www.google.com/").protocol'
http
|
Scratch that, I'll update all the tests, too. |
|
Why? |
|
Bad day at the office? Or is today "close-without-reason Tuesday"? I'll resubmit tomorrow - hopefully with better luck. Perhaps there's good science to be had in such experiments! In the mean time, you can mend your possibly bad day with some UCB skits, like this one: http://www.ucbcomedy.com/videos/play/6904/who-poisoned-whose-tea |
|
Sorry, my terseness was not coming from any sort of disrespect or grumpiness. What I mean is, why is this a good change? There's been zero discussion of this idea. It is purely cosmetic but will break lots of node programs. What's the benefit? I closed the issue because, in lieu of some very compelling reason, there's no way this is happening. There's a "reopen" button if such reason can be found, but otherwise, it may as well not take up space on the list. So... Why? |
|
Well, I filed this because I believe I found a bug. I sent it as a pull because it was an easy patch. There's been zero discussion because nobody had filed this bug before. The comment section of github issues and pulls are a great arena for such discussion (and code review). As for a compelling reason, here's a few:
Code samples for each of 4 languages mentioned above: (X) url.js is pretty broken with respect to RFC1738 and real-world url stuff, but much of that is out of scope for this issue. |
|
Specific snippets of grammar from RFC1738: "scheme" above is what url.js calls "protocol" - note how the colon isn't part of the scheme. The scheme grammar includes no allowance for colon characters. |
|
To be fair, I can think of one URL parser that does keep the trailing colon: the browser. F12 + window.location.protocol |
|
Node's url.js borrows its naming conventions from the
The browser is the reference implementation as far as url parsing and resolving is concerned. People who aren't familiar with every relevant RFC (ie, almost everyone) expect it to work the same. |
|
@jordansissel I found this a bit strange as well and it made me write https://github.com/publicclass/addressable which is basically Rubys extended URI gem "addressable" for js. It parses urls closer to the RFC with some extra features found in the ruby gem... |
|
Even if you're ignoring everything else, and only using 'the browser' as your specification/reference, url.js still falls down pretty hard. Further, I'm not sure what you're calling "the browser" (which browser? which version?). Example, google chrome 13 fails to recognize "svn+ssh://foo.com/" as a valid URL, but Firefox 4.0.1 does fine. Additionally, url.js doesn't properly parse data urls, while most modern browsers handle seem to handle this fine, so is url.js really based on a browser, or was it based on some fantasy of what some browser somewhere at some time might maybe have done? Whatever happens, it would be nice if folks like @slaskis didn't have to look at the core / standard library of a given tool and go "that's mad broken, dog" and have to fix a standard, broken thing by making a new third-party thing. (edit: google chrome might recognize svn+ssh://, but the behavior of unknown url schemes seems to be to search them instead of saying 'i don't know what this is') |
|
If we're going to bring IETF spec's into this. Here is the regex that the URI RFC recommends for parsing URI's: http://tools.ietf.org/html/rfc3986#page-51 (I use a modified version of this myself, it's pretty fast and it works well.) /^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))?/Which for the following URL: Results in the following captures: They capture both the trailing colon and the protocol without it. What to do now? ;) |
|
It'd be nice if url.parse handled I'd also like to figure out some deterministic way to handle urls that separate the hostname from a cwd-relative path with It would also be nice if the return value of url.parse was an instance of a class that had a toString method which returned the formatted href, since that's the only omission from what the browser implementations provide. But that's not terribly important. (Incidentally, since
It is not the intent of node to be a batteries-included platform. https://github.com/joyent/node/wiki/node-core-vs-userland Url parsing is an extremely common task that most web servers and clients need to do. There is an existing quorum in the leading JavaScript implementations on how urls are to be parsed, so we're following it at least as closely as any browser follows any other.
It doesn't fetch it, and hyperlinks with svn+ssh hrefs aren't followed. If you configure chrome to open a different application for this protocol, then it'll open that application.
|
Foot-stomp and 'you shall not pass' heard and noted. I withdraw my patch and bug report. |
Hahah. I think @ry is the gandalf character here. You know he once removed url parsing entirely? |
|
@chjj yep, that's the regex I use in addressable. Works a treat :) |
|
@chjj and @isaacs: $1 only collects the scheme's trailing ":" because the grammar for "collecting-parens-but-who-cares" hadn't yet been implemented in POSIX regex :D Read the next section of the RFC; the sentence starting "Therefore, we can determine the value of the five components as ..." is kind of important. "$1" is irrelevant. It is an ex-regex. It has perished. It does not matter. How about the ascii-art section "Syntax Components", or section 3? Given that none of the art there notes the trailing ":" as being remotely important, how about dumping it? How about noting that the only purpose that that section imparts the ":" is "the character between the first part we care about and the second part we care about"? It's a string literal - a character that could, should and must be thrown away in order for code at a higher level to use the library code sensibly! [Edited to remove alcoholic content] |
|
we need to match expectations, the expectation is that this behaves like the browser. we live with the browser's mistakes, that's the web. |
|
A URL parsing lib including a trailing : in the scheme part looks like a bug to me, regardless of the mistakes "the browsers" have made in the past. |
|
yeah, that shit's fucking insane. I don't give a damn about your ideology, any ideology which leads you to write something like that has its head up its ass. |
|
Sorry, nothing personal. Immensely useful library. I use it and love it. But you have got to be fucking kidding me. |
|
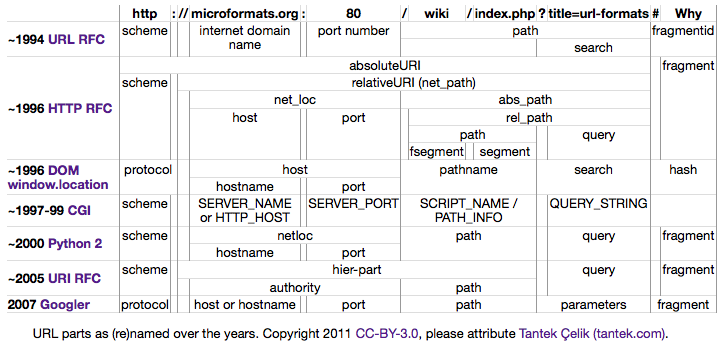
Heh, I read a blog post a few days ago about the differences between various URL parsing/slicing. http://tantek.com/2011/238/b1/many-ways-slice-url-name-pieces Quick reference image: |
|
well, I'll take practical sense over logical sense, head up its ass or not. |
|
Um, guys. Why not just include protocol with the colon (eg "http:") and scheme without it ("http"). That way everyone wins. |
|
I'm a reasonably experienced developer, and my expectation was not that it would include the colon. |
|
@xenomonkey Adding @gilesbowkett I'm not sure who you're insulting. @jwatte How long did it take you to adapt your program to handle the ":" in the protocol property? A whole minute? Less? I'm really not seeing a bug here. |
@isaacs: For me @jordansissel already covered it, but to summarise, convention, standards and some sense of correctness. |
|
@isaacs Upon reflection I think my suggestion is crap (results in bloated code for, as you say, no gain). You're quite right the only reason for doing it would be to make node more similar to other languages and slightly more compliant with the RFC. Either scheme (without the colon) or protocol (with the colon) should be supported but not both. Personally I don't care either way (I'm quite capable of adding/stripping a character from a string if I need to). I would suspect that since node is based on javascript that you should stick with the most expected solution. For javascript programmers than would be to use protocol and leave the colon on the end. |
|
Yeah, what the hell was @gilesbowkett on about? Anyway, I don’t know why everybody’s flipping out about this. @isaacs’ point is perfectly appropriate: Node is JavaScript; Node is intended to parallel the browser; Node is intended to keep everything in userspace code. There is no real argument for the change, except that “some other languages do it this way.” What browsers do ≥ what other languages do, because Node is intended to ape the browser, not those other languages. |
|
@paulbjensen wins 9000 internets! |
|
I HAVE AN OPINION! |
|
MOAR COLONS |
|
What are colons? Are they webscale? 9000 internets is not enough for webscale. |
|
I: think: this: issue: has: not: received: enough: attention:: Too: many: developers: have: been: failing: to: end: every: string: with: a: colon:: |
|
Losers always whine about RFCs and back compat. Bros go home with the prom queen: require.colonsblow = function (moduleName) {
var mod = require(moduleName);
var k, fn;
function colonic(x) {
return (typeof x === 'string' && x.slice(-1) === ':') ? x.slice(0, -1) : x;
}
function wrap(fn) {
return function () {
var result = fn.apply(this, arguments);
var k;
if (result instanceof Array) {
result = result.map(function (v, i, a) {
return colonic(v);
});
} else if (result && typeof result === 'object') {
for (k in result) {
if (result.hasOwnProperty(k)) {
result[k] = colonic(result[k]);
}
}
}
return colonic(result);
};
}
for (k in mod) {
if (mod.hasOwnProperty(k) && typeof mod[k] === 'function') {
mod[k] = wrap(mod[k]);
}
}
return mod;
};
var ballinURLz = require.colonsblow('url');
console.log(ballinURLz.parse('http://your.mom.com/so/fat'));Doneski. This bro is headed to Twin Peaks for shots and steaks. Who's in? No nerds. |
|
Isaacs was the prom queen. |
|
|
Ah, beat me to it. |
|
|

|
|

|
|

|
+1 for getting rid of useless chars |
|
Compatibility with non-standard APIs is stupid. 99% of the users will perform a |
|
@BonsaiDen @sbussard this thread is now closed to serious comments, only jokes are allowed now |
|
At this rate, we might as well just get rid of semicolons too |

|
what other things end with a colon? ... |
|
How do I unparticipate from this 4chanish thread? |
|
|

{kind=link}
|
Below the comment box. Click "Disable notifications for this Pull Request" |
|
What the hell did I just read? |
|
+1 keeping protocol as-is The first is useful for sharing code and APIs between front and back end code. / web front-and-back-end developer since 15 years |
|
What's the point of digging arguments last year? Esp. when it comes to punchuations, it's strictly personal and your opinion is not likely to work. |
|
@github Can you please please give us the ability to close comments on issues after some period of time? This is a textbook example of a thing that is well beyond the point where any good can possibly come from additional conversation. |
Background behind the colon is nodejs/node-v0.x-archive#1580 (be sure to read it all the way)
|
@github -1 on the ability to close comments after some period of time. As a firm believer in free speech, we should not let people stifle constructive conversation. I've been a fan of using github as a source of high quality entertainment for over 5 years, you would be doing your key demographic a disservice in implementing said feature. Also I feel like @gilesbowkett comments were on point. |
|
thanks guys for going so deep into this colon issue. the library really needed some cleansing. felt like it was getting full of waste. |
Before:
% node -e 'require("url").parse("http://www.google.com/").protocol'
http:
After:
% node -e 'require("url").parse("http://www.google.com/").protocol'
http