Whisper WebUI with a VAD for more accurate non-English transcripts (Japanese) #397
Replies: 29 comments 60 replies
-
|
Hey, that looks like a very nice project that you setup. I also encountered the issues in Whisper while trying to transcribe Japanese (incorrect timings, infinite loops) and wanted to try out your CLI with VAD but I always encounter the following error: I'm trying to execute your CLI script like this: Any idea what I'm doing wrong? The first thing that I see when I check the error message is that it says |
Beta Was this translation helpful? Give feedback.
-
|
Looks like I forgot to concat the initial_prompt with the running prompt in each VAD segment. This was not a problem in the WebUI, as you can't specify an initial prompt there, but only in the CLI. I've fixed it now, though. So you can try pulling the repository again. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, is there a reason to prefer the option |
Beta Was this translation helpful? Give feedback.
-
|
Thanks. I'm going to test it right away. |
Beta Was this translation helpful? Give feedback.
-
|
No problem. 😃
Are you using Google Colab? If so, you could do this fairly easily by using the command line directly within the Notebook: Then you can access your Google Drive at /content/drive. For instance, if you want to transcribe a file at AI/Test/out.mka in your own Drive, you can use the following command: This will save the SRT and assorted files next to "out.mka".
|

Beta Was this translation helpful? Give feedback.
-
|
Thanks! Very helpful. |
Beta Was this translation helpful? Give feedback.
-
It is, though using a VAD should reduce this timing problem at a minor cost to accuracy. You can set a VAD in the command line by using the --vad option: |
Beta Was this translation helpful? Give feedback.
-
|
I used silero-vad-expand-into-gaps with the large model. The timing is off especially in the areas when a music, or a background sound starts before dialogue. The sub time starts from the start of the background sound. At least that is my observation so far. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you this seems promising, i tried using it and encountered the following error $ python3 ~/whisper-webui/cli.py --model large --device cuda:0 --task translate --language Japanese --vad silero-vad-skip-gaps ~/x/test.mkv
/home/user/.local/lib/python3.10/site-packages/torch/hub.py:266: UserWarning: You are about to download and run code from an untrusted repository. In a future release, this won't be allowed. To add the repository to your trusted list, change the command to {calling_fn}(..., trust_repo=False) and a command prompt will appear asking for an explicit confirmation of trust, or load(..., trust_repo=True), which will assume that the prompt is to be answered with 'yes'. You can also use load(..., trust_repo='check') which will only prompt for confirmation if the repo is not already trusted. This will eventually be the default behaviour
warnings.warn(
Downloading: "https://github.com/snakers4/silero-vad/zipball/master" to /home/user/.cache/torch/hub/master.zip
Processing VAD in chunk from 00:00.000 to 01:00:00.000
/home/user/.local/lib/python3.10/site-packages/torch/nn/modules/module.py:1130: UserWarning: operator() profile_node %1178 : int[] = prim::profile_ivalue(%1176)
does not have profile information (Triggered internally at ../torch/csrc/jit/codegen/cuda/graph_fuser.cpp:104.)
return forward_call(*input, **kwargs)
/home/user/.local/lib/python3.10/site-packages/torch/nn/modules/module.py:1130: UserWarning: concrete shape for linear input & weight are required to decompose into matmul + bias (Triggered internally at ../torch/csrc/jit/codegen/cuda/graph_fuser.cpp:2076.)
return forward_call(*input, **kwargs)
Processing VAD in chunk from 01:00:00.000 to 01:32:35.000it seems to be working despite the error, however the error persist even after re-running after downloading the silero-vad model any pointers to fix this? the environment in question is wsl2 with cuda |
Beta Was this translation helpful? Give feedback.
-
|
You could add "trust_repo=True" to the load method in the constructor of VadSileroTranscription. This is at line 380 in vad.py in the current version. That will implicitly trust snakers4/silero-vad, and it should prevent the warning from being displayed in the console: I was thinking of doing this myself, but the problem was that using "trust_repo" requires torch v1.12 or later, and I wanted to support older versions of Torch. I tried checking the Torch version dynamically, but that didn't seem to work as expected. But I'll probably look into it again before v1.14 is released and "trust_repo" becomes required. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks, I am mainly concerned about this part though while i can read python code this part is just doesn't click for me :-( |
Beta Was this translation helpful? Give feedback.
-
|
@aadnk Do you have any idea on why this sometimes happens? after running the vad i rerun custom translation on top of the srt and noticed this results. so times the result is mixs of JPN and ENG text jumbled togather, some of those lines are double for example it seems the transcribe translated the text correctly, but it fed back to the text thus resulting into the problem, i have no idea why this is happening. Also as you may have noticed the VAD for some reason generate much higher rate of untranslated text compared to whisper without VAD i am using the silvero-vad |
Beta Was this translation helpful? Give feedback.
-
|
@arabcoders: How short are the segments that are passed to Whisper, by the way? In the default Web-UI, you can see this displayed in the console output under "Processing timestamps", for instance: Perhaps Whisper is hallucinating English in the transcription when the duration is fairly short? If that's the case, then I'd try increasing "VAD - Max Merge Size (s)" and "VAD - Merge Window (s)" (vad_max_merge_size and vad_merge_window in the CLI). That will increase the duration of the segments that are passed to Whisper, which should hopefully reduce the frequency of the issue (given that the non-VAD version is less prone to it). But yeah, if you're still having issues, I'd recommend creating a short program that reproduces the translation problem along with a short sample audio, and making an issue here on GitHub. Perhaps someone at OpenAI or another contributor might have some ideas. |
Beta Was this translation helpful? Give feedback.
-
|
I see here is a fairly complete sample if you have any other pointers |
Beta Was this translation helpful? Give feedback.
-
|
@aadnk Thank you for this non English improvement! |
Beta Was this translation helpful? Give feedback.
-
|
No problem. 👍 But yeah, looks like I forgot to test the default "CMD" in the Dockerfile. But I believe it should work now (commit): sudo docker run -d --gpus all -p 7860:7860 \
--mount type=bind,source=/home/administrator/.cache/whisper,target=/root/.cache/whisper \
--restart=on-failure:15 registry.gitlab.com/aadnk/whisper-webui:latestYou have to update the You can disable this by setting sudo docker run -d --gpus all -p 7860:7860 \
--mount type=bind,source=/home/administrator/.cache/whisper,target=/root/.cache/whisper \
--restart=on-failure:15 registry.gitlab.com/aadnk/whisper-webui:latest
app.py --input_audio_max_duration -1 --server_name 0.0.0.0 |
Beta Was this translation helpful? Give feedback.
-
|
TNX! Works now :) |
Beta Was this translation helpful? Give feedback.
-
|
Made a fork with this low VRAM support for large image. TNX! |
Beta Was this translation helpful? Give feedback.
-
|
It seems like Large-V2 in the most recent version of Whisper is a huge improvement when transcribing Japanese. I tested it on "Macross Frontier - the Movie" as above, and it no longer breaks after 8 minutes: Large-V1 (transcribed at 2022-10-02) - no VAD: Large-V2 (latest version at 2022-12-07): There's still some timing issues after a period of silence, but using a VAD as a workaround may no longer be strictly necessary. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the tips, could you suggest better |
Beta Was this translation helpful? Give feedback.
-
|
@arabcoders, I used 30 seconds for The upside of using a VAD, is that you still avoid some of the timing issues due to non-speech as I mentioned above. For instance, when I ran |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the explanation, i mostly use whisper on Japanese's variety shows some them do include heavy music usage as such, it's kind of almost required to have VAD to realign the recognizer otherwise it starts to generate non-sense. Thanks I'll start with 600s to see how it goes. |
Beta Was this translation helpful? Give feedback.
-
|
@aadnk , would I be able to do batch processing, running a loop command in colab like: for file in drive_folder: Or would this mess up with vad/whisper cache ? |
Beta Was this translation helpful? Give feedback.
-
|
@dgoryeo: The easiest solution is just to use wildcards, which will be expanded to multiple file names by bash: For instance, if the Drive folder contained the files "audio_01.webm", "audio_02.webm", "audio_01.webm", then the command will use Whisper to transcribe all the "webm"-files and output the transcript/SRT/VTT of each in the same folder: Or you can use the latest version of the WebUI, which allows you to upload multiple files in the "Upload Files" section, and download the result as a ZIP file or individual files:
|


Beta Was this translation helpful? Give feedback.
-
|
firstly thank you so much this is what I want! but i wonder i have no code skills etc. i am using google colab and i wonder is there any saving options instead of google drive, i asked it because i do whisper stuff when I go to sleep let the google colab do it, so i dont want to lose any stuff hope it clears do you any idea ? |
Beta Was this translation helpful? Give feedback.
-
|
So you'd like to save the transcript/SRT/VTT files to some Cloud drive automatically, in case the Google Colab instance is shut down while you're away from your computer? I think the best solution is just to add support saving the generated files to a specific directory in the WebUI as well, and then automatically save all the files to a Google Drive folder:
I've updated both Whisper WebUI and the Google Colab document to support this - just run the code below "Mount Google Drive", and let the document have write/read access to your Drive. Then run the Whisper command under "Let Whisper use Google Drive as Temp Directory ...". This will start the Web UI, but save all generated files to the "Whisper" folder in your Drive (you may have to create this folder first, before you start the WebUI):
|


Beta Was this translation helpful? Give feedback.
-
|
Your work is incredible, but as a beginner, I really don't know what went wrong. |
Beta Was this translation helpful? Give feedback.
-
|
Looks like Gradio is passing a file to Python's mimetypes.guess_type, which is then returning None, something Gradio is not expecting. I tried a few different file types on my Windows 10 machine, but I'm unable to reproduce the issue. Perhaps you can try running Python is also using the Windows registry to fetch mime types - perhaps there's an issue there? You could try another Windows machine/VM, if you have one available. |
Beta Was this translation helpful? Give feedback.
-
|
Hey bud, absolutely love using your code to translate my japanese shows, as of today i seem to be having some kind of error, the code executes but i never get a subtitle file or transcript, it worked fine yesterday when used, can you confirm? thank you so much :) |
Beta Was this translation helpful? Give feedback.
-
|
There seems to be some issues with executing long-running functions in Gradio 3.13.1 and 3.14.0. I've downgraded to 3.13.0 for now in "requirements.txt", so if you clone/update the repository it should work. If you're running Whisper on Google Colab, you can just deallocate your instance and run all the steps again. |
Beta Was this translation helpful? Give feedback.
-
|
Hello! I followed all the instructions and I can launch the webui, but when I click on "submit" after uploading the file I want to transcribe I get the following error: Any idea how to fix it? Python 3.9.12 |
Beta Was this translation helpful? Give feedback.
-
|
Created a new VM, followed all the instructions at https://gitlab.com/aadnk/whisper-webui/-/blob/main/docs/windows/install_win10_win11.pdf, and I still get the same exact error. |
Beta Was this translation helpful? Give feedback.
-
|
It seems it doesn't like big video files (>1GB). If I split the audio with ffmpeg and use that file instead, whisper runs without any issue. |
Beta Was this translation helpful? Give feedback.
-
|
Have you tried another format beside WAV? You could also encode it lossessly with FLAC using FFMPEG, or perhaps compress it with AAC. Or, you could encode the WAV to the format Whisper expects, which might be smaller: |
Beta Was this translation helpful? Give feedback.
-
|
The original file was a .mp4. I used |
Beta Was this translation helpful? Give feedback.
-
|
Hello, I have been trying to run your setup with AMD gpu. GPU is detected and the WebUI starts correctly: My issue is that after filling everything in the UI and starting the Transcription, I get this error: Complete logs from the python command:
root@sdm:/dockerx/whisper-webui# python app.py --input_audio_max_duration -1 --server_name 127.0.0.1 --auto_parallel True
[Auto parallel] Using GPU devices ['0'] and 8 CPU cores for VAD/transcription.
Running on local URL: http://127.0.0.1:7860
To create a public link, set It seems to attempt using Cuda, and I really don't understand why as this worked for the normal Whisper. |
Beta Was this translation helpful? Give feedback.
-
|
Looks like the problem is in torchaudio, which is used by silero-vad. I presume you've followed these instructions (or something similar) to get Whisper to run on an AMD device? If so, you should try also installing tourchaudio in the same fashion - i.e. by running the command |
Beta Was this translation helpful? Give feedback.
-
|
Yes, exactly, I followed these instructions (on the docker part as this was the only way I could make it detect/using my GPU) I tried both of your commands but it is still failing at the same line. I can't find if there is another pytorch audio related package that is missing. Complete traceback:
Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/gradio/routes.py", line 321, in run_predict
output = await app.blocks.process_api(
File "/opt/conda/lib/python3.8/site-packages/gradio/blocks.py", line 1015, in process_api
result = await self.call_function(fn_index, inputs, iterator, request)
File "/opt/conda/lib/python3.8/site-packages/gradio/blocks.py", line 856, in call_function
prediction = await anyio.to_thread.run_sync(
File "/opt/conda/lib/python3.8/site-packages/anyio/to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "/opt/conda/lib/python3.8/site-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "/opt/conda/lib/python3.8/site-packages/anyio/_backends/_asyncio.py", line 867, in run
result = context.run(func, *args)
File "app.py", line 121, in transcribe_webui
result = self.transcribe_file(model, source.source_path, selectedLanguage, task, vad, vadMergeWindow, vadMaxMergeSize, vadPadding, vadPromptWindow)
File "app.py", line 196, in transcribe_file
process_gaps = self._create_silero_config(NonSpeechStrategy.CREATE_SEGMENT, vadMergeWindow, vadMaxMergeSize, vadPadding, vadPromptWindow)
File "app.py", line 264, in _create_silero_config
self.vad_model = VadSileroTranscription()
File "/dockerx/whisper-webui/src/vad.py", line 406, in __init__
self._initialize_model()
File "/dockerx/whisper-webui/src/vad.py", line 414, in _initialize_model
self.model, self.get_speech_timestamps = self._create_model()
File "/dockerx/whisper-webui/src/vad.py", line 418, in _create_model
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad', model='silero_vad')
File "/opt/conda/lib/python3.8/site-packages/torch/hub.py", line 542, in load
model = _load_local(repo_or_dir, model, *args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch/hub.py", line 569, in _load_local
hub_module = _import_module(MODULE_HUBCONF, hubconf_path)
File "/opt/conda/lib/python3.8/site-packages/torch/hub.py", line 90, in _import_module
spec.loader.exec_module(module)
File "", line 843, in exec_module
File "", line 219, in _call_with_frames_removed
File "/root/.cache/torch/hub/snakers4_silero-vad_master/hubconf.py", line 4, in
from utils_vad import (init_jit_model,
File "/root/.cache/torch/hub/snakers4_silero-vad_master/utils_vad.py", line 2, in
import torchaudio
File "/opt/conda/lib/python3.8/site-packages/torchaudio/__init__.py", line 1, in
from torchaudio import ( # noqa: F401
File "/opt/conda/lib/python3.8/site-packages/torchaudio/_extension.py", line 135, in
_init_extension()
File "/opt/conda/lib/python3.8/site-packages/torchaudio/_extension.py", line 105, in _init_extension
_load_lib("libtorchaudio")
File "/opt/conda/lib/python3.8/site-packages/torchaudio/_extension.py", line 52, in _load_lib
torch.ops.load_library(path)
File "/opt/conda/lib/python3.8/site-packages/torch/_ops.py", line 573, in load_library
ctypes.CDLL(path)
File "/opt/conda/lib/python3.8/ctypes/__init__.py", line 373, in __init__
self._handle = _dlopen(self._name, mode)
OSError: libroctx64.so.1: cannot open shared object file: No such file or directory
Just in case I also tried the newest stable pytorch ROCm (5.2) but it ends like that as well. |
Beta Was this translation helpful? Give feedback.
-
|
I haven't got an AMD GPU to test on at the moment, but have you followed all the installation instructions for the rocm/pytorch Docker container? But, silero-vad is actually not using the GPU to perform any inference. It's purely a single-threaded CPU operation - in fact, this is why I spawn multiple Python processes when "--auto-parallel" is "True" to execute silero-vad in parallel. In your case, it will spawn up to 8 processes ("8 CPU cores for VAD/transcription"). So another possibe solution to this, might be to hide the GPU for the "silero-vad" Python processes using "CUDA_VISIBLE_DEVICES=-1". That is, if you followed the installation procedure for ROCM, and it is correctly installed and configured for Docker. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your answer! Yes I had followed everything but it seemed that the ROCm installation didn't even have the file Many thanks for your implementation, it works very well now and it is easy to use ! It will help me a lot for my Japanese studies! |
Beta Was this translation helpful? Give feedback.
-
|
Hi how can I transcribe english audio and translate to another language? If I choose translate it always outputs in english. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much for creating this and putting it together in such an easy-to-use package. |
Beta Was this translation helpful? Give feedback.
-
|
Hello @aadnk is there a way to use fine tuned model with your webui? Something like this - https://huggingface.co/clu-ling/whisper-large-v2-japanese-5k-steps |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much for your work! I've been waiting to test thing for a while now. I tried all kinds of Japanese fine tune model on a real time translation whisper and the model i provided earlier work decently better than vumichien, but there are still some parts are not fully translated. Either way now I can test all of them and see if it any better than large-v2 from OpenAi. Thank you! |
Beta Was this translation helpful? Give feedback.
-
|
@whizyre , the Huggingface leaderboard doesn't seem to list the model whisper-large-v2-japanese-5k-steps. Is that because it has not been trained on Common Voice 11 Japanese (ja)? At any rate I'd be very keen to hear the results of your experiment. @aadnk , thanks for making this config available. It is very helpful! |
Beta Was this translation helpful? Give feedback.
-
|
Hi @aadnk , would it be possible to set Whisper hyperparameters in the config file, e.g : The usecase I am thinking about is: to define config files for various audio classes/types, group audios of similar type in one folder, place the corresponding config file in each folder, and to run CLI on each folder to process all files. |
Beta Was this translation helpful? Give feedback.
-
|
@dgoryeo: Sure, I've added all the other hyperparameters/configuration options to You can now set the following additional configuration options:
|
Beta Was this translation helpful? Give feedback.
-
|
Wow, thanks a lot @aadnk !!! |
Beta Was this translation helpful? Give feedback.
-
|
i want to ask this too
<https://www.avast.com/sig-email?utm_medium=email&utm_source=link&utm_campaign=sig-email&utm_content=webmail>
Virus-free.www.avast.com
<https://www.avast.com/sig-email?utm_medium=email&utm_source=link&utm_campaign=sig-email&utm_content=webmail>
<#DAB4FAD8-2DD7-40BB-A1B8-4E2AA1F9FDF2>
…On Wed, 22 Mar 2023 at 06:37, fznx922 ***@***.***> wrote:
also while on this topic i was able to find this model
https://huggingface.co/vumichien/whisper-large-v2-mix-jp which seems like
it had been trained on more steps?
—
Reply to this email directly, view it on GitHub
<#397 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AUOZO4DT5WHNYGB6JF3B4NLW5I3R5ANCNFSM6AAAAAARMAHQRE>
.
You are receiving this because you are subscribed to this thread.Message
ID: ***@***.***>
|
Beta Was this translation helpful? Give feedback.
-
|
can i use your new code to this .. i mean the code that i can use any model ... |
Beta Was this translation helpful? Give feedback.
-
|
Yes, you should be able to use a VAD with any models - just ensure that If you want to use the command line, you can select a VAD with the python cli.py --model MYCUSTOMMODEL --vad silero-vad --language Japanese "https://www.youtube.com/watch?v=4cICErqqRSM"Where |

Beta Was this translation helpful? Give feedback.
-
|
Hello aadnk, great work on this project. I initially installed it on my computer running Windows 11, and it worked flawlessly. I also tested it on an older hardware setup with CentOS 7 and two K80 GPUs, and it performed admirably. I wanted to inquire about the diarization aspect of the project. Let me explain: Whisper is doing an excellent job at transcribing, and the VAD is efficiently assisting with synchronization. However, when two people speak simultaneously, the transcriptions sometimes become mixed. I came across another project that addresses this issue: https://github.com/MahmoudAshraf97/whisper-diarization/blob/main/diarize.py. Do you think it's possible to combine both projects? If so, when would be the optimal time to implement diarization? For instance, if I apply diarization after the VAD, the results may improve, but I won't be able to "colorize" different transcriptions throughout the entire clip or movie. Thanks in advance! |
Beta Was this translation helpful? Give feedback.
-
|
Hey Aadnk I've been using your version of faster whisper and was wondering because faster whisper supported word level time stamps if that could improve the transcription quality for japanese? not sure if its possible or if you had tested this already but just a thought i was trying to go about trying it, but currently dont know where to start or if it would conflict with your scripting already, again thank you for all your hard work mate, love your variation on whisper :)! |
Beta Was this translation helpful? Give feedback.
-
|
Whisper recently added a |
Beta Was this translation helpful? Give feedback.
-
|
Could you add the --word_timestamps option? |
Beta Was this translation helpful? Give feedback.
-
|
Sure, I've added this in commit f55c594f. You can now set the A bit of a note on highlight_words - it is implemented in the Whisper WebUI itself, as it's apparently not supported yet on the released version of Whisper or Faster Whisper, and it is a really useful feature for creating karaoke subtitles. Enabling "word_timestamps" will also improve the line-breaking algorithm, as it can now attempt to only create line-breaks on words as determined by Whisper. |
Beta Was this translation helpful? Give feedback.
-
|
when i run new app.py, i got this error and quit: (whisper) A:\AI\whisper-webui>python app.py --whisper_implementation faster-whisper --input_audio_max_duration -1 --server_name 127.0.0.1 --auto_parallel True |
Beta Was this translation helpful? Give feedback.
-
|
i was able to fix the issue by replacing it with |
Beta Was this translation helpful? Give feedback.
-
|
@fznx922: @zx3777: But I believe this should be fixed now, by specifying that |
Beta Was this translation helpful? Give feedback.
-
|
win10 gpu faster-whisper mode When I use it for slightly longer audio with long gap with no speech, dont use VAD, when transcribing, sometimes it gets stuck and just won't move anymore, or it gets stuck for a long time and then ends abruptly. The dialogue after the jam is not recognized, and the timeline for outputting subtitles only goes up to the time of the jam. After getting stuck, nothing is output in srt file For example, this mp3 file:https://cyberfile.me/6h1c ,use for "medium/korean", no vad, it will stuck at a certain time almost evertime. When I use the original whisper to recognize the same audio and sometimes it gets stuck, but it will continue after a while and Never had a situation like the above. |
Beta Was this translation helpful? Give feedback.
-
|
Strange, I am able to transcribe and translate this file on a 2080 Super (8 GB VRAM) and a 2080 Ti (11 GB). Perhaps your GPU doesn't have enough VRAM for this particular file? Here's the resulting transcript/translation, if you want to compare with your output I have also sometimes accidentally paused the command line window by selecting some text in Windows (related StackOverflow) - perhaps that could be an issue here as well? |
Beta Was this translation helpful? Give feedback.
-
|
thank you very much . my gpu is 3060ti 8g, It should not be a vram problem, and I have ruled out the window paused problem. |
Beta Was this translation helpful? Give feedback.
-
|
when i use VAD , sometimes it gets stuck like this. But not every time it gets stuck, the same audio sometimes gets stuck and sometimes doesn't:
|
Beta Was this translation helpful? Give feedback.
-
|
When auto_parallel True is removed and single-core cpu is used, it can work normally. But much slower than six cores. What exactly is the problem? |
Beta Was this translation helpful? Give feedback.
-
|
Use dual cores at most, and more will get stuck. The number of occurrences of "Using cache found in C:\ Users\ xX/.cache\ torch\ hub\ snakers4_silero-vad_master" must match the number of cores of cpu, otherwise there will be problems. Is it a problem with the python version? I use Python 3.10.8, but the one you recommended in the tutorial is 3.9.12. |
Beta Was this translation helpful? Give feedback.
-
|
I can't reproduce this with Python 3.10.8, so I doubt it. And unfortunately, unless I can reproduce this, it's really difficult to fix. If you've followed my tutorial on Windows, I'd suggest trying the following:
Alternatively, you could just run the Whisper WebUI on Google Colab instead (link). It is free up to a certain usage level. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks a lot for your help, I'll give it a try. |
Beta Was this translation helpful? Give feedback.
-
|
Today, when i use fast-whisper, it gets stuck like this. I try to change config, but it do not work: Traceback (most recent call last): Sorry, we can't find the page you are looking for. |
Beta Was this translation helpful? Give feedback.
-
|
It seems to be working now, might just have been a problem at HuggingFace.co |
Beta Was this translation helpful? Give feedback.
-
|
Hello, I absolutely love your project! I am currently encountering a problem, I want to generate video subtitles by pasting the URL of the video. But will get |

Beta Was this translation helpful? Give feedback.
-
|
Hello! Since the GUI can write out the timestamps of when something is being spoken, is there a way for it to use these timestamps to chunk out the sections in the audio file that has speech and save it as an speech_only.wav audio file? |
Beta Was this translation helpful? Give feedback.
-
|
Sounds like the job of a separate tool, so I wrote a simple CLI that takes an audio file and a SRT, and outputs only the sections that are referenced by the SRT file:
Example command: Or with the EXE: |
Beta Was this translation helpful? Give feedback.
-
|
You are an absolute legend (especially for the language learning community) thank you! |
Beta Was this translation helpful? Give feedback.
-
|
Hello! I forked code from https://gitlab.com/aadnk/whisper-webui/-/tree/main, and ran it locally in Linux system. With a video link which it could be parsed in the huggingface demo provided by the original author, it seemed that the local service had not taken effect, terminal had no output and UI was always displayed in the calculation process. Have you ever encountered such a situation or did you know how to handle it?
Thanks |


Beta Was this translation helpful? Give feedback.
-
|
I was able to reproduce this on an older version Ubuntu (20.04.4 LTS). But it seems to be caused by an issue in Gradio, which was fixed when I updated it to the latest version: I'll see if I can't switch to 3.38.0 in the repository as well. UPDATE: I've updated to Gradio 3.38.0 - try pulling the repository again, and installing the requirements. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your suggestion ! After I update the gradio, the local service works. |
Beta Was this translation helpful? Give feedback.
-
|
@aadnk Thanks for this great tool, I've noticed that when enabling the |
Beta Was this translation helpful? Give feedback.
-
|
Hey Aadnk :) any chance yet to see what the difference / accuracy in performance in v2 vs v3 model on your application in transcribing japanese? thanks 👍 |
Beta Was this translation helpful? Give feedback.
-
|
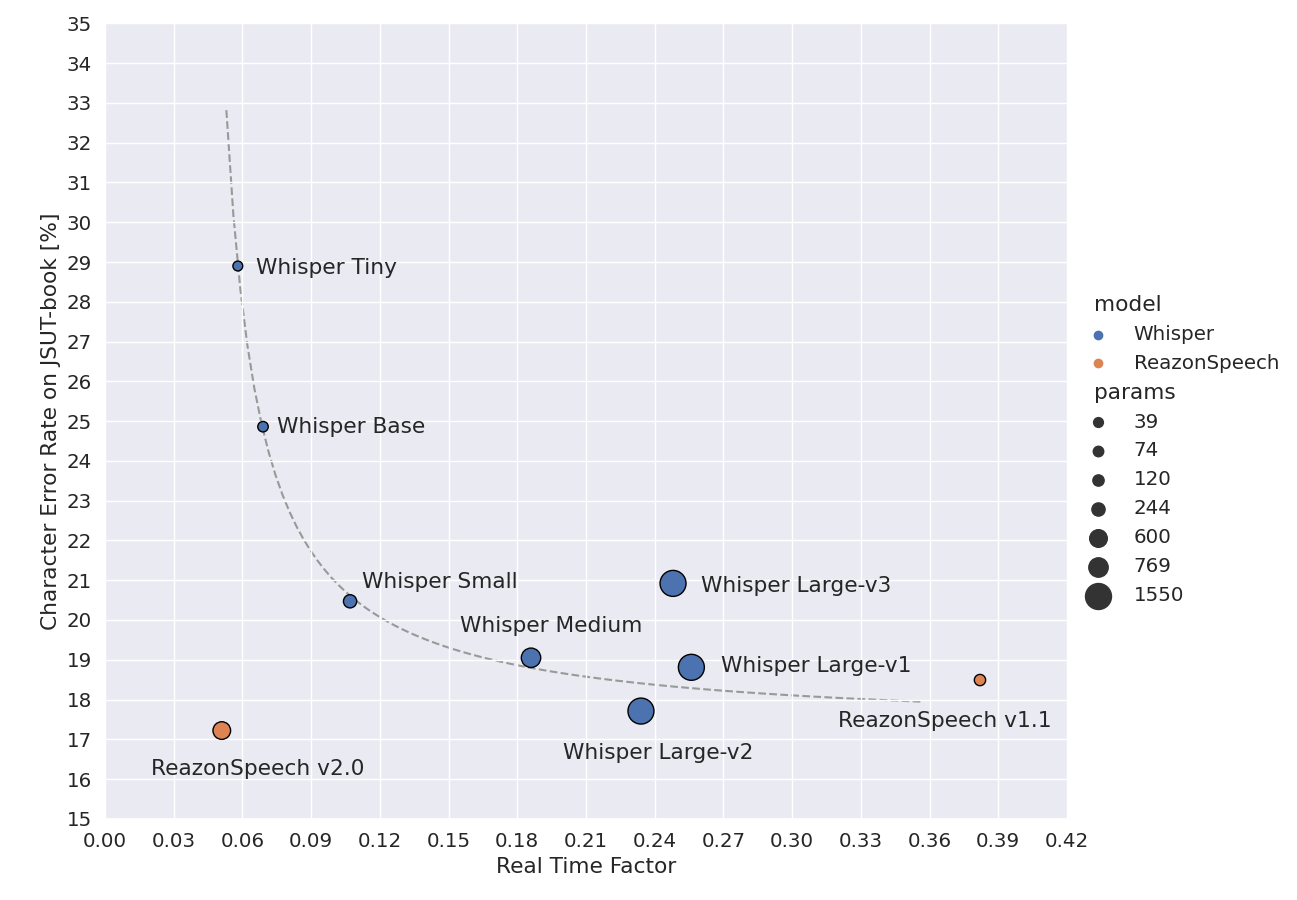
v2 is better than v3,Reference source:https://research.reazon.jp/projects/ReazonSpeech/index.html |
Beta Was this translation helpful? Give feedback.
-
|
Would it be possible to implement Stable-TS? It's a wrapper on whisper/faster_whisper that has much better timing and grouping of subtitles than default whisper. It also provides some nice helper functions to manipulate the transcription (changing timing, finding/replacing/removing characters/words) (they also have their own functions to write to srt files, and highlight words, similar to what you already have). I've been able to kind of mash your code with theirs by copying your code into my repo and editing the fasterWhisperContainer.py to run Stable-ts instead. fasterWhisperContainer.py Update There are a few caveats I had to make:
|
Beta Was this translation helpful? Give feedback.
-
|
YOUR whisper on googlecolab have some error |
Beta Was this translation helpful? Give feedback.
-
|
what should i do? |

{kind=link}
Beta Was this translation helpful? Give feedback.
-
I've found Whisper to be an incredible free tool for transcribing audio, so I've made my own WebUI which integrates directly with YT-DLP for direct YouTube transcripts, and allows for easy downloads of a transcript or an SRT/VTT file. It also supports more accurate transcripts for languages other than English using a VAD.
There's also support for parallel execution on multiple GPUs, using the
--auto_parallel Trueoption (see the README for more information):Installation instructions:
You can also use the CLI version, which is identical to the Whisper CLI except that you can also use URL's rather than file paths, and specify a VAD (more about this below). Also note that it's relatively easy to host this WebUI on Google Colab, if you don't have enough GPU horsepower locally to run it yourself.
I've also added support for Docker. You can even download the containers directly from GitLab (see the README for more information):
VAD
Using a VAD is necessary, as unfortunately Whisper suffers from a number of minor and major issues that is particularly apparent when applied to transcribing non-English content - from producing incorrect text (wrong kanji), setting incorrect timings (lagging), to even getting into an infinite loop outputting the same sentence over and over again.
Default Whisper
For instance, when I tried to transcribe the Japanese movie "Macross Frontier - the Movie" i, it got stuck after 00:01:46, endlessly outputting the lines "宇宙に向かう", "アスクワード", "マスコミネットの調査を進めるこの時点で":
I tried using an FFMPEG command to convert the 5 channel audio to better emphasize the center channel with most of the audio dialog, but Whisper still got stuck after 00:08:05, endlessly outputting lines with only the number "2":
However, I was able to avoid some of these issues by manually splitting the original movie into 10 minute chunks, run Whisper in each chunk, and then merge the resulting transcripts together into one long transcript (SRT).
Using Silero VAD
I've been tinkering with my WebUI since the public release of Whisper, and I think I've found a solution using Silero VAD which dramatically improves the accuracy of both the text and timings of long transcripts in Japanese. Just take a look at the transcript for the Macross Frontier movie as an example:
There's still a few repeated lines, but these are hallucinations that occur during silent periods. Other than that, it's actually usable as opposed to just running Whisper on the whole audio.
Essentially, this is done by detecting continuous sections of speech using Silero VAD, then (for performance reasons) merge sections into up to 30 seconds chunks when sections are 5 seconds or less apart. I also pass previous detected text as prompt, if the text is close enough (prompt window is up to 3 seconds by default). Next, I also try to split each chunk such that it includes about 1 second of padding before and after, to ensure that Whisper is properly able to detect words in the beginning and end of each chunk. Finally, Whisper is run on each chunk and the output is automatically merged into one single transcript.
This is enough to mostly completely fix the issues with Japanese text, and I've even been able to run Whisper on 7+ hour videos with no major issues, for instance on this 07:21:20 video by Korone on YouTube:
You can view this transcript directly on YouTube using the addon Substital.
Downsides
The downside is that Whisper might be less accurate when transitioning between each chunk, but in the case of Japanese this is certainly more than worth the trade off when by default Whisper is not able to handle more than a couple of minutes before encountering the issues above. It's also potentially a bit slower.
For English content, however, this trade off may not be worth it, but it could still be depend on the content. I tried using this method on a recent episode of Taskmaster (S14E01), but it didn't seem to improve the timings by much, and it also introduced a few errors during these chunk border (mishearing Dara Ó Briain for instance). Still, it was not noticeably worse or better than regular Whisper.
Beta Was this translation helpful? Give feedback.
All reactions