Segment Anything Model (SAM) has achieved impressive results for natural image segmentation with input prompts such as points and bounding boxes. Its success largely owes to massive labeled training data. However, directly applying SAM to medical image segmentation cannot perform well because SAM lacks medical knowledge — it does not use medical images for training. To incorporate medical knowledge into SAM, we introduce SA-Med2D-20M, a large-scale segmentation dataset of 2D medical images built upon numerous public and private datasets. It consists of 4.6 million 2D medical images and 19.7 million corresponding masks, covering almost the whole body and showing significant diversity. This paper describes all the datasets collected in SA-Med2D-20M and details how to process these datasets. Furthermore, comprehensive statistics of SA-Med2D-20M are presented to facilitate the better use of our dataset, which can help the researchers build medical vision foundation models or apply their models to downstream medical applications. We hope that the large scale and diversity of SA-Med2D-20M can be leveraged to develop medical artificial intelligence for enhancing diagnosis, medical image analysis, knowledge sharing, and education.
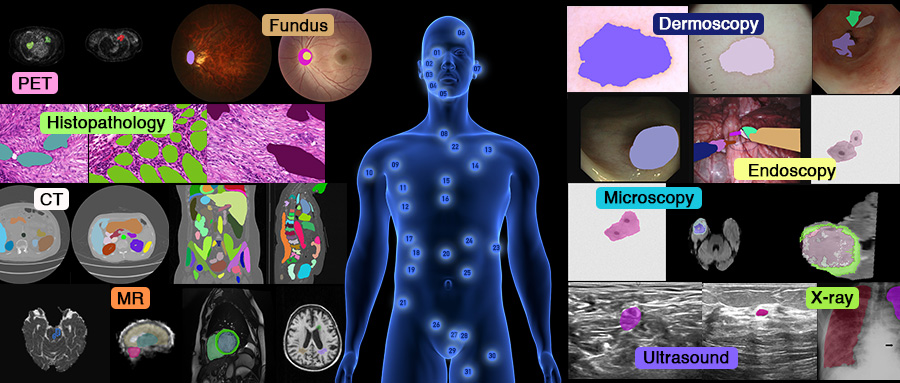
- The visual appearance of natural images and medical images is substantially different as reviewed below. The huge domain gap can be attributed to the data collection methods: medical images are collected from specific protocols and scanners and are presented as different modalities (electrons, lasers, X-rays, ultrasound, nuclear physics, and magnetic resonance) due to their particular clinical purpose.

- Publicly available datasets for medical image segmentation are often limited in data size. Even the largest medical datasets are a fraction of the size and diversity of benchmark datasets in general computer vision and NLP. Figure below shows the data size gap between different research areas. More importantly, these public datasets often focus on a single environment, modality, or anatomical structure, thus with limited diversity. It is vital to build a large-scale dataset with diverse medical images, which will help to advance medical image analysis as successfully as computer vision and NLP.

- SA-Med2D-20M is the largest medical segmentation dataset by far. SA-Med2D-20M is also expected to encompass a wide range of modalities and categories. It takes advantage of numerous public datasets on the web sources (TCIA, OpenNeuro, NITRC, Grand Challenge, Synapse, CodaLab, GitHub, etc) to collect as many public medical segmentation datasets as possible.
The dataset contains 10 modalities, 31 main organs, and 271 labeled classes. This covers almost all object types in the currently available public datasets, aiming to address the deficiency of data in medical imaging. We hope that a large-scale dataset of medical segmentation is a helpful resource for developing advanced foundation models in medical image analysis.

The distribution of the datasets is depicted below. As illustrated in left figure, over 120 datasets fall short of reaching 10,000 images or 100,000 masks. Furthermore, even the most extensive dataset in our collection contains fewer than 100,000 images and 1,000,000 masks, respectively. As a result, it is challenging to collect and release such a large and diverse medical image dataset. Figure right presents the case distribution across various body parts in the SA-Med2D-20M dataset.

SA-Med2D-20M includes 10 modalities, as detailed in table below. CT and MR modalities are predominant in both the number of images and masks, it is mainly attributed to their widespread presence in public medical image segmentation datasets and the 3D dimension of CT and MR scans, which yields a high volume of slices when segmented across three axes.

- The SA-Med2D-20M dataset could be downloaded from here.
The related official code is available here.
The evaluation metric of SA-Med2D-20M are flexible for users. It could be Dice, HD95 and so on.
This project is released under the Apache 2.0 license.
@article{ye2023sa,
title={SA-Med2D-20M Dataset: Segment Anything in 2D Medical Imaging with 20 Million masks},
author={Ye, Jin and Cheng, Junlong and Chen, Jianpin and Deng, Zhongying and Li, Tianbin and Wang, Haoyu and Su, Yanzhou and Huang, Ziyan and Chen, Jilong and Jiang, Lei and others},
journal={arXiv preprint arXiv:2311.11969},
year={2023}
}
@misc{cheng2023sammed2d,
title={SAM-Med2D},
author={Junlong Cheng and Jin Ye and Zhongying Deng and Jianpin Chen and Tianbin Li and Haoyu Wang and Yanzhou Su and
Ziyan Huang and Jilong Chen and Lei Jiangand Hui Sun and Junjun He and Shaoting Zhang and Min Zhu and Yu Qiao},
year={2023},
eprint={2308.16184},
archivePrefix={arXiv},
primaryClass={cs.CV}
}