Repository containing comparisons between different out-of-the-box machine learning algorithms in some classic datasets.
The name is a sort of joke for a very established concept: to try different classic algorithms in a dataset to experiment and see how each one behaves.
It's an attempt to answer some questions:
- How does different models compare to each other in equal conditions?
- What's the impact of fine-tuning (using Grid Search or other methods) the models?
- What's the impact of data normalization in different models?
- Is it ok to use out-of-the-box scikit-learn's models?
- When to use Machine Learning after all? Are there situations where is better not to use ML models?
The idea for this project came from Elite Data Science's blog, in this particular list of projects. The concept of a gladiator, with several algorithms competing on similar terms, is fairly commomn, so there's other sources that use this term.
Bellow is a brief of the datasets, the models and the final scores. More information, further conclusions and analysis can be found in the READMEs inside their subfolders in this repository.
The first dataset that I'll apply this concept is the well known MNIST dataset. As the classes are balanced, the metric used to evaluate the models is accuracy. The models created were:
- Support Vector Classifier
- Random Forest
- K-Nearest Neighbors Classifier
- MLP Classifier
- Gradient Boosting Classifier
- Logistic Regression
- Perceptron
- Ridge Classifier
- Ridge Classifier CV
- Bernoulli Naive Bayes
- Gaussian Naive Bayes
- Decision Tree
One surprise is how well KNN model did in comparison with other more robust methods.
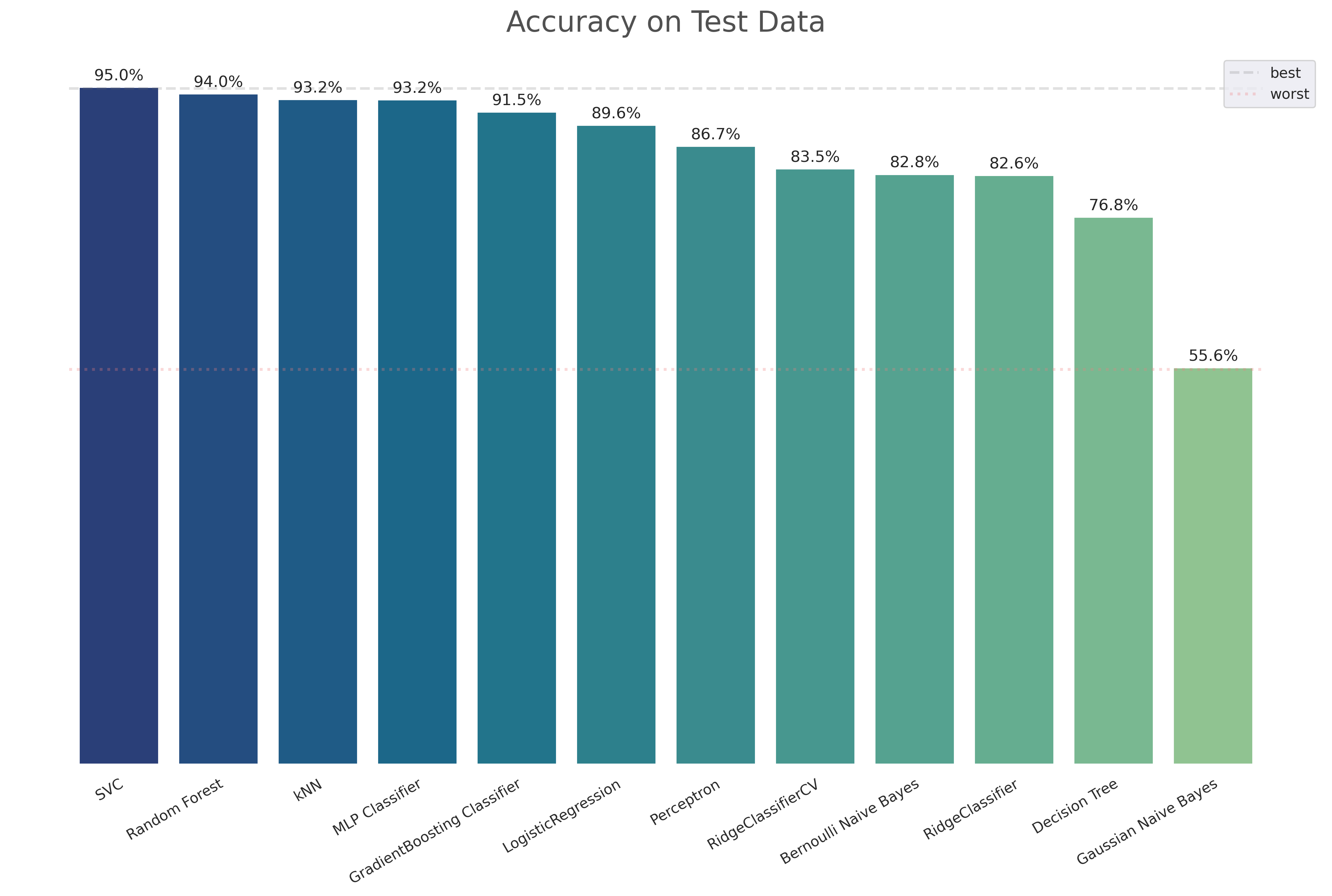 Accuracy on test data with out-of-the-box sklearn algorithms. No optimization was made. The training data was a subset of 5000 random images from the MNIST dataset, and the test data was a subset of 2000 random images.
Accuracy on test data with out-of-the-box sklearn algorithms. No optimization was made. The training data was a subset of 5000 random images from the MNIST dataset, and the test data was a subset of 2000 random images.
The notebook is avaiable in the MNIST subfolder and also on Google Colab.
The models used to predict the class of the Fashion MNIST's clothes are:
- Deep Neural Network
- Convolutional Neural Network
- CNN with Transfer Learning from the VGG16 Model
No surprises here. The CNN model did better than the DNN and the Transfer Learning model did (marginally) better than the CNN one.
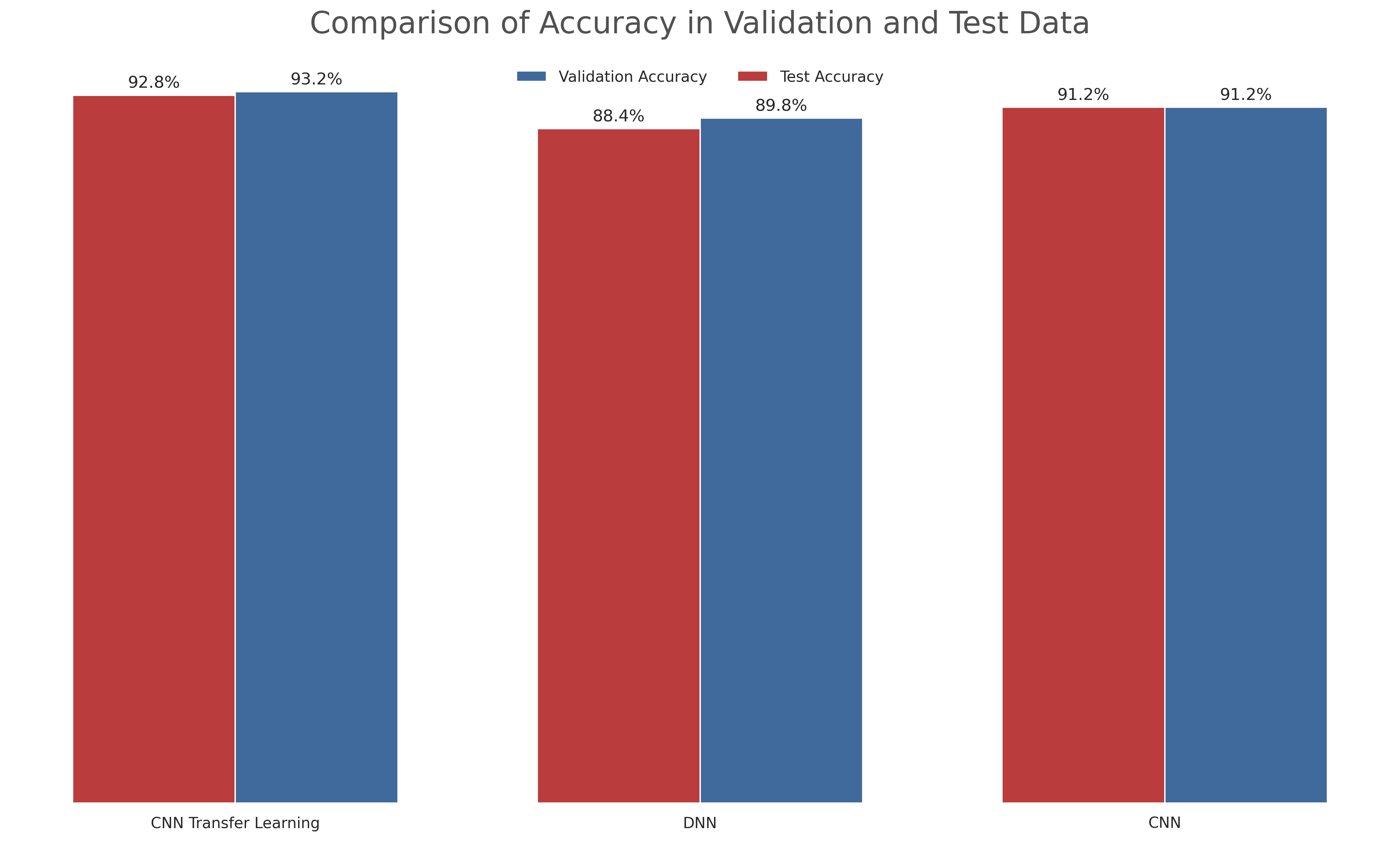 All models were trained, validated and tested with the same datasets.
All models were trained, validated and tested with the same datasets.
The notebook is avaiable in the Fashion MNIST subfolder and also on Google Colab.
For this classic dataset, the models created were:
- Dummy Classifier - an instance of sklearn that is used purely to stablish a baseline to the real models.
- Bernoulli Naive Bayes
- K-Nearest Neighbors Classifier
- SGD Classifier
- Logistic Regression
- Ridge Classifier
- Support Vector Classifier
- Decision Tree
- Random Forest
- XGBoost Classifier
- Neural Network (Deep Neural Network)
Here is the final plot, a comparison of the validation accuracy score both with normalized and unnormalized data:
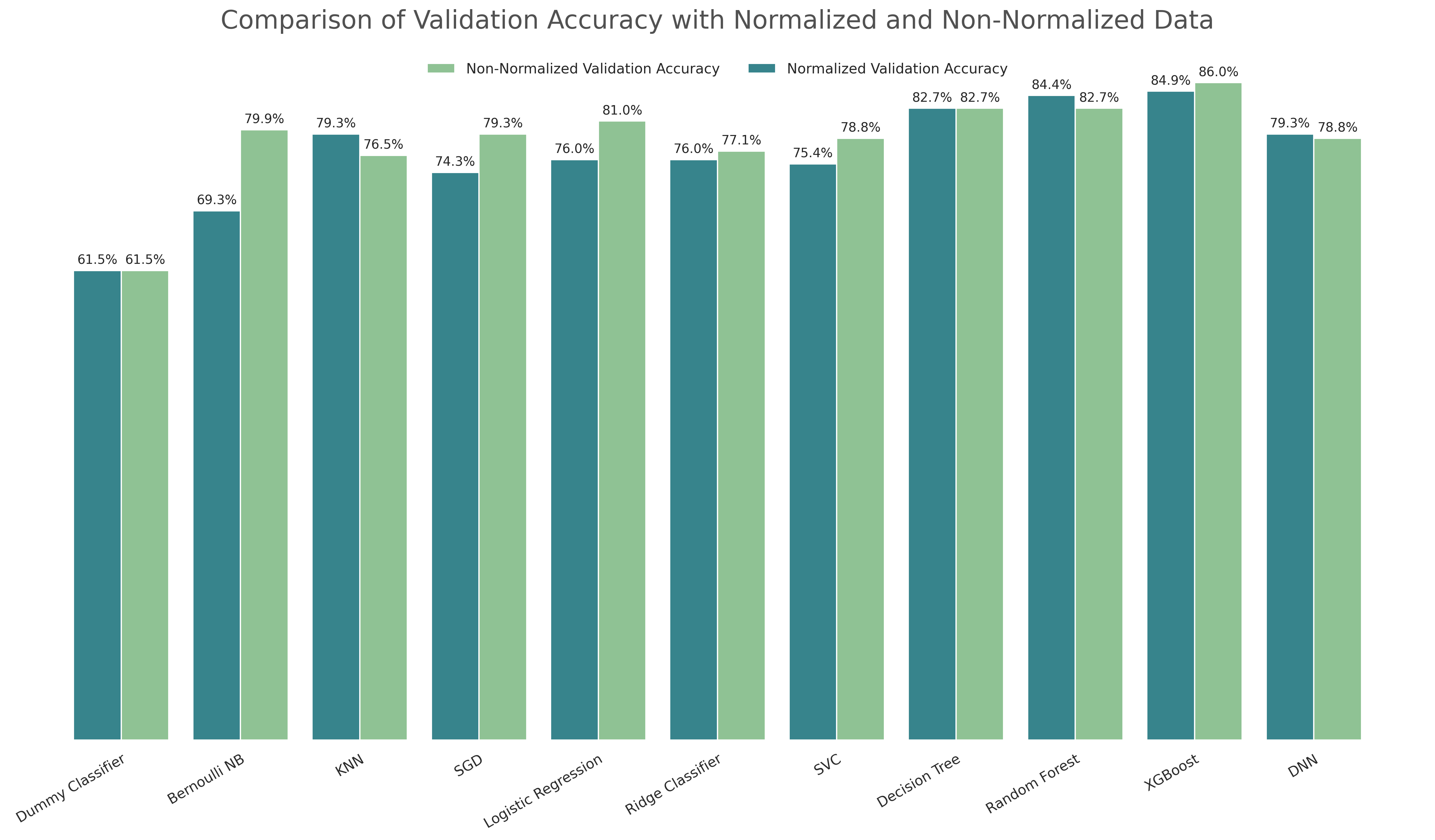 Comparison Between the Validation Accuracy using Normalized and Unnormalized Data
Comparison Between the Validation Accuracy using Normalized and Unnormalized Data
The Wine Quality Dataset is related to red and white variants of the Portuguese "Vinho Verde" wine. The data can be found in Kaggle (only the Red Wine variant) and the UCI Machine Learning Repository.
The task can either be classification or regression. For this comparison I chose to treat the dataset as a classification problem, to see if the wine is good (quality equal or above 7) or bad (otherwise).
The dataset is not balanced, because there are many more examples of normal wines than of excellent and poor ones, and the authors of the dataset state that "we are not sure if all input variables are relevant. So it could be interesting to test feature selection methods.", so a robust EDA could improve the results (or straight up replace the ML models).
This is a good examples of a scenario where the use of Machine Learning may not be the best path to take. Using out-of-the-box algorithms and only performing normalization in the data (without an extensive exploratory data analysis/feature engineering) yelded the results bellow. The high scores of the dummy classifier indicates that the logic behind the classification could be extracted without training and deploying a sofisticated machine learning model.
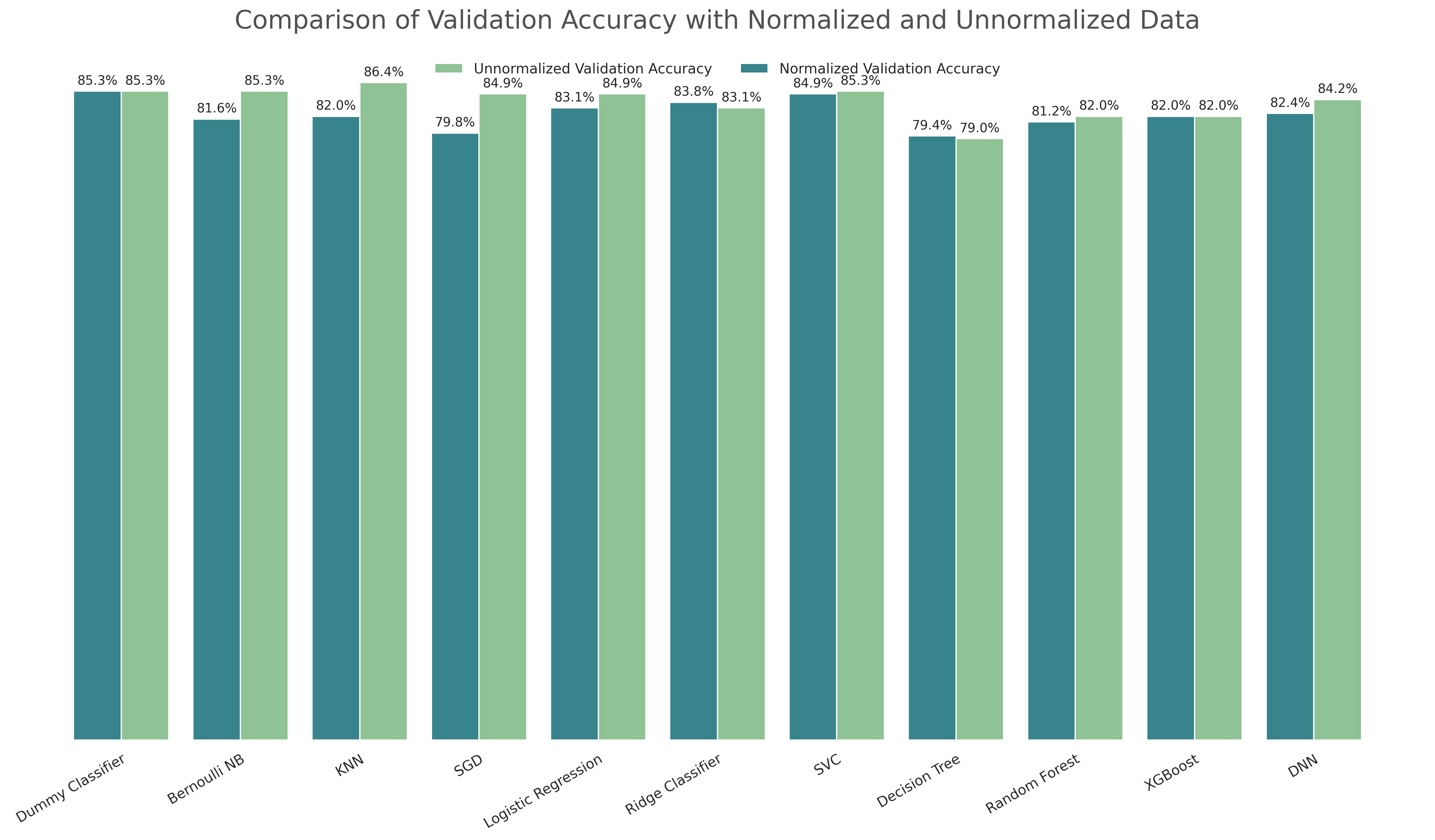 Wine Quality Models' Accuracy Comparison in Validation and Training (Cross Validation)
Wine Quality Models' Accuracy Comparison in Validation and Training (Cross Validation)
I plan to do similar analysis with House Prices and TMDB Box Office datasets.
