Performance and Optimizing
Below are notes on optimization of spiffs.
All performance graphs and collected from spiffs running on a Cortex CPU: STM32F103VET6 @ 72MHz. The code has a home-spun preemptive OS. The SPI bus is running at 36MHz, and the SPI communication is interrupt and DMA driven. The SPI flash chip is a Micron M25P16.
Code can be found here. Spiffs is configured according to this.
Spiffs can be configured in many ways. Looking at the structure, spiffs normally do not complain even if things are oddly configured. The penalty is efficiency, either in flash usage or in time.
Following statements are guidelines.
Spiffs needs two free logical blocks. Hence, having less than 6 logical blocks is suboptimal. Having a great deal of logical blocks (more than 512) is valid, but spiffs will need to process a lot of data and this takes time. It might be better to have bigger logical blocks giving less number of blocks.
Considering logical block size and logical page size, one block should have at least eight pages per block. More is better. Upper limit is untested, but more than 1024 pages per block will probably be suboptimal. 32 to 512 pages per block feels reasonable.
Remember, it is perfectly valid to have a logical block size that spans multiple physical blocks. It is not necessary to span 2^n physical blocks, any multiple will do. Though, the size of the entire spiffs file system must be an integer multiple of the logical block size.
This all depends on how large your file system is, the median size of your files, and how the files are accessed and modified. To find your global maximum: test, test, test.
Then again, as mentioned, spiffs swallows pretty much. If you're not having problems with speed you should perhaps not spend too much time testing around.
Spiffs crunches pretty much data from time to time. Stating the obvious, use compiler optimizations.
If you have some spare tightly coupled memory, you might want to put spiffs work buffer there. If there is even more room, put the cache there also. Still got free space - toss in the file descriptor buffer as well.
If you only run one spiffs instance, some cpu cycles can be saved using the SPIFFS_SINGLETONconfig.
Configs SPIFFS_CACHE (read cache) and SPIFFS_CACHE_WR (write cache).
Enabling read cache is highly recommended, and gives a performance boost at the cost of some memory. The more pages you can give, the better. However, spiffs only supports up to 32 cache pages. Giving more is waste of ram.
Also, enabling write cache is a very good thing to do. Otherwise, one must take care when writing data as all writes will be written through directly. Without write cache, only largest possible quantity of data should be written at any time. A loop like the following would wear the spi flash extremely without write cache:
// Bad example when not having write cache enabled
int write_one_million_fibonacci_numbers(void) {
spiffs_file fd = SPIFFS_open(fs, "fib", SPIFFS_O_CREAT | SPIFFS_O_TRUNC | SPIFFS_O_RDWR, 0);
if (fd <= 0) return SPIFFS_errno(fs);
int i = 1000000;
int a = 0;
int b = 1;
while (i--) {
// calc fibonacci number
int c = a + b;
a = b;
b = c;
// DO NOT DO THIS WITHOUT WRITE CACHE
// write one number at a time
if (SPIFFS_write(fs, fd, (u8_t *)&c, sizeof(int)) < SPIFFS_OK) {
(void)SPIFFS_close(fs, fd);
return SPIFFS_errno(fs);
}
}
if (SPIFFS_close(fs, fd) < SPIFFS_OK) return SPIFFS_errno(fs);
return SPIFFS_OK;
}Instead of above, you should buffer as much data numbers as you can, and then write the buffer. But only without write cache. Otherwise, above is ok. The write cache will buffer it for you.
If you have space for read cache pages, then in 99.999% of all cases you should also enable SPIFFS_CACHE_WR. It will not cost extra memory.
Opening a file given a filename will have spiffs search all blocks' first pages (the lookup pages) for object index headers - the file headers. Each found file header is then visited to see if the filename matches.
If lucky, the file is found quickly. If unlucky, lots of data needs to be filtered before the file is found.
There are a bunch of ways speeding this up.
If your application needs to frequently open and close files, and files are opened in a manner of temporal locality, enable config
SPIFFS_TEMPORAL_FD_CACHE
Temporal locality in our case simply means that if a file was opened briefly before, it is likely to be opened again.
Examples could be some log file, being opened and updated often; or a http server that uses same css for all html pages: each access to an html file will also need to open the css file.
Let's construct a model of the latter example, the http server, on an ESP8266 for instance. Spiffs is configured to having 4*2kB logical block and 256 byte pages on 1 MB of the spi flash.
Cache is enabled, and spiffs is given eight cache pages and four file descriptors.
Our example has seven html files on the server residing on spiffs, each file being a couple of kilobytes. Each html file refers to a common css file. When a user accesses an html page, the http server implementation opens that html file, reads it, and the closes it. After that the css is opened, read, and closed.
Each html page have a certain probability of being visited by users.
| File | Hit probability |
|---|---|
| 1.html | 25% |
| 2.html | 20% |
| 3.html | 16% |
| 4.html | 12% |
| 5.html | 8% |
| 6.html | 5% |
| 7.html | 4% |
Running this in the testbench by randomizing access according to above probabilities 10.000 times, we get:
| Sum HAL read accesses | Sum read bytes from spi flash | |
|---|---|---|
| no temporal cache | 1595258 | 389395837 |
| with temporal cache | 276361 | 63361517 |
In this example, spiffs is more than 80% more efficient opening files when it comes to number of HAL spi flash read accesses and number of read bytes from the spi flash with temporal cache enabled.
The temporal fd cache piggybacks on the file descriptor update mechanism. The more file descriptors you have, the more file locations will be remembered. As a result of this, if you open all file descriptors at some point, all cache history is lost.
The price you pay for the temporal cache is six extra bytes per file descriptor and some cpu cycles.
It is recommended to always enable SPIFFS_TEMPORAL_FD_CACHE.
There is a quick way not wasting time opening files - do not close them. If you have but a few files that must be accessed quickly, and have the memory for it, you can simply open those files in the beginning and never close them.
Opened files are tracked - if the file is moved, the file descriptor is updated internally. Actually, it is valid to open the same file in multiple file descriptors. They will all be updated upon changes to the spi flash.
Just make sure to call SPIFFS_fflush after SPIFFS_write (i.e. where your SPIFFS_close should have been).
Say you have three file descriptors and ten files, named "0", "1" till "9". If these files are always opened and closed in sequence from "0" to "9", multiple times, the temporal cache will be sidelined. This kind of access pattern is not temporal enough as we have only three descriptors.
Or you may simply have critical files that must be opened within a certain time.
If opening files is too slow in such cases, it is possible to implement your own cache for these files.
Assuming these files are created, we can scan for them and store the page index for each and one of them in an array. We also hook in a callback function to spiffs - SPIFFS_set_file_callback_func. This provides us with notifications when file headers are modified. Thus, we can track our cached files and update our cache. With this, we simply use SPIFFS_open_by_page which will open the file on O(1) time.
// Example of rolling your own cache for files that must be opened swiftly
#define NBR_OF_CACHE_FILES (10)
typedef struct {
spiffs_obj_id obj_id; // the file id
spiffs_page_ix pix; // the file header location
} spiffs_cache_entry;
static spiffs_cache_entry own_cache[NBR_OF_CACHE_FILES];
static const char *CACHED_FNAMES[NBR_OF_CACHE_FILES] = {
"0","1","2","3","4","5","6","7","8","9"
};
static void spiffs_cb(spiffs *fs, spiffs_fileop_type op,
spiffs_obj_id obj_id, spiffs_page_ix pix);
int start(void) {
// here goes code for initializing spiffs and mount it
...
// register our callback function to spiffs
(void)SPIFFS_set_file_callback_func(fs, spiffs_cb);
init_cache();
}
// populate cache, first time
int init_cache(void) {
int res;
int i;
for (i = 0; i < NBR_OF_CACHE_FILES; i++) {
const char *fname = CACHED_FNAMES[i];
spiffs_cache_entry *entry = &own_cache[i];
spiffs_stat s;
res = SPIFFS_stat(fs, fname, &s);
if (res != SPIFFS_OK) {
break;
}
entry->obj_id = s.obj_id;using
entry->pix = s.pix;
}
return res;
}
// open one of our cached file by giving index in cache map
// index 0 will thus open file "0", index 1 will open "1" etc
spiffs_file open_cached_file(const int index, spiffs_flags flags) {
if (own_cache[index].pix == 0) {
// file deleted, return bad fd
return -1;
}
spiffs_file fd = SPIFFS_open_by_page(fs, own_cache[index].pix, flags, 0);
return fd;
}
// callback function implementation - update cache if any of our files
// were touched
// no SPIFFS_nn calls within here please
static void spiffs_cb(spiffs *fs, spiffs_fileop_type op,
spiffs_obj_id obj_id, spiffs_page_ix pix) {
int i;
for (i = 0; i < NBR_OF_CACHE_FILES; i++) {
spiffs_cache_entry *entry = &own_cache[i];
if (entry->obj_id != obj_id) {
continue;
}
switch (op) {
case SPIFFS_CB_UPDATED:
entry->pix = pix;
break;
case SPIFFS_CB_SPIFFS_CB_DELETED:
// our cached file was deleted
case SPIFFS_CB_CREATED:
// our old cached file was deleted and now spiffs is reusing
// the obj.id for a new file - should never get here
default:
// huh?
entry->pix = 0; // file no longer valid, clear cache mark
break;
}
break;
}
}If possible, read chunks of data instead of byte per byte. There is cpu overhead issuing the read command. Of course, this is all depending on what kind of processor you're running on.
Slow example, reading byte per byte:
uint8_t byte;
while (SPIFFS_read(fs, fd, &byte, 1) >= SPIFFS_OK) {
process_one_byte(byte);
}Fast example, reading chunks of 256 bytes:
uint8_t data[256];
int32_t len;
while ((len = SPIFFS_read(fs, fd, &data, sizeof(data))) >= SPIFFS_OK) {
int32_t i;
for (i = 0; i < len; i++) {
process_one_byte(data[i]);
}
}On the stm32 test platform, following graph is from reading a 512kB file with different chunk sizes. The time is measured in milliseconds. The red boxes defines the chunk size for each reading.
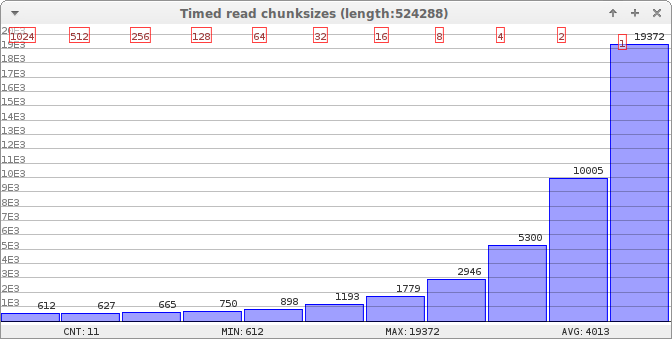
Reading a 512kB file with different chunksizes. Times are in milliseconds.
This translates to following read speeds:
| Chunk size | Bytes per second |
|---|---|
| 1024 | 856680 |
| 512 | 836185 |
| 256 | 788403 |
| 128 | 699051 |
| 64 | 583840 |
| 32 | 439470 |
| 16 | 294709 |
| 8 | 177966 |
| 4 | 98922 |
| 2 | 52403 |
| 1 | 27064 |
TODO
TODO tip: call gc in beforehand
write bigger chunks if possible.
Below is a time graph of writing 100000 bytes on an 1 megabyte file system, 256 bytes a time. The file system is pretty full - roughly 80% filled, the rest being deleted files. The high spikes comes from the garbage collector, making room for the data. It can be seen that the spikes become more frequent as the system gets more crammed. Write speed is 1384 bytes per second.
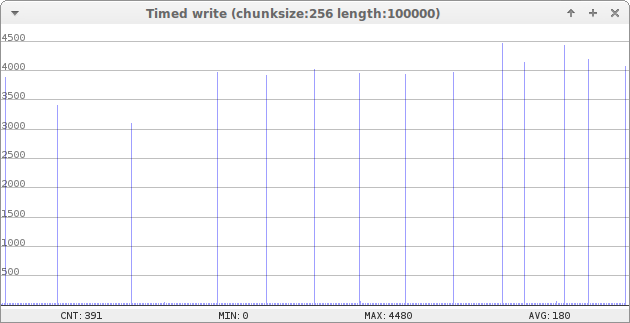
Writing 100000 bytes on an almost full system, 256 bytes a time. Times are in milliseconds.
Same write, but on a formatted system, is represented below. Now, the largest spikes represent a rewrite or creation of an index page. In this case, two pages needs to be written instead of one, so in this case the time is roughly doubled. However, no garbage collections are needed. Write speed in this case is 6330 bytes per second.
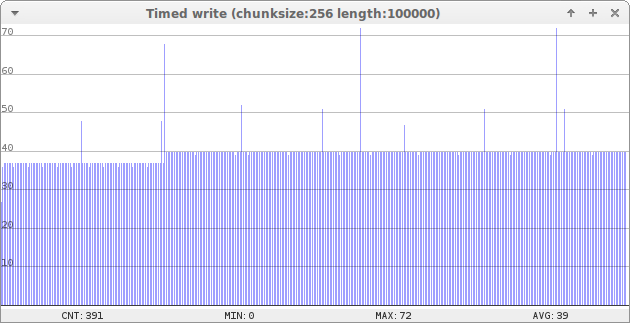
Writing 100000 bytes on formatted system, 256 bytes a time. Times are in milliseconds.
These stack figures are collected from the hardware testbench.
Including in this stack usage is formatted prints, the spi driver, and some OS stuff. Rather than having a totally clean measurement of the stack usage without any noise, I personally prefer a more real-world measurement. The latter statement is heavily depending on that I otherwise would have to rewrite everything, and I'm far too lazy for that.
Compiler: arm-none-eabi-gcc (GCC) 5.3.0, Cortex-M3
Optimizer flags: -Os
| Function | Stack usage in bytes |
|---|---|
SPIFFS_write (gc required) |
960 |
SPIFFS_gc |
760 |
SPIFFS_write (no gc required) |
576 |
SPIFFS_read |
552 |
SPIFFS_remove |
520 |
SPIFFS_open (non-existing file) |
432 |
SPIFFS_open (read) |
432 |
SPIFFS_rename |
416 |
SPIFFS_mount |
376 |
SPIFFS_gc_quick |
344 |
SPIFFS_format |
312 |
SPIFFS_check |
TBD |
Below is a table of the more important build time configurations and the generated binary size for all combinations. The table is generated by object-dumping the elf file and summing up all symbol sizes stemming from the spiffs source folder.
This table can be used to get a rough picture of needed flash footprint for incorporating spiffs.
Compiler: arm-none-eabi-gcc (GCC) 5.3.0, Cortex-M3
Optimizer flags: -Os
| READ_ONLY | SINGLETON | CACHE | IX_MAP | TEMPORAL_FD_CACHE | MAGIC | Binary size |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 4986 |
| 1 | 1 | 0 | 0 | 0 | 1 | 5086 |
| 1 | 1 | 0 | 0 | 1 | 0 | 5248 |
| 1 | 1 | 0 | 0 | 1 | 1 | 5348 |
| 1 | 1 | 0 | 1 | 0 | 0 | 6278 |
| 1 | 1 | 0 | 1 | 0 | 1 | 6378 |
| 1 | 1 | 0 | 1 | 1 | 0 | 6532 |
| 1 | 1 | 0 | 1 | 1 | 1 | 6632 |
| 1 | 1 | 1 | 0 | 0 | 0 | 6278 |
| 1 | 1 | 1 | 0 | 0 | 1 | 6390 |
| 1 | 1 | 1 | 0 | 1 | 0 | 6536 |
| 1 | 1 | 1 | 0 | 1 | 1 | 6648 |
| 1 | 1 | 1 | 1 | 0 | 0 | 7586 |
| 1 | 1 | 1 | 1 | 0 | 1 | 7698 |
| 1 | 1 | 1 | 1 | 1 | 0 | 7840 |
| 1 | 1 | 1 | 1 | 1 | 1 | 7952 |
| 1 | 0 | 0 | 0 | 0 | 0 | 5552 |
| 1 | 0 | 0 | 0 | 0 | 1 | 5980 |
| 1 | 0 | 0 | 0 | 1 | 0 | 5842 |
| 1 | 0 | 0 | 0 | 1 | 1 | 6266 |
| 1 | 0 | 0 | 1 | 0 | 0 | 6968 |
| 1 | 0 | 0 | 1 | 0 | 1 | 7392 |
| 1 | 0 | 0 | 1 | 1 | 0 | 7250 |
| 1 | 0 | 0 | 1 | 1 | 1 | 7674 |
| 1 | 0 | 1 | 0 | 0 | 0 | 6932 |
| 1 | 0 | 1 | 0 | 0 | 1 | 7372 |
| 1 | 0 | 1 | 0 | 1 | 0 | 7214 |
| 1 | 0 | 1 | 0 | 1 | 1 | 7654 |
| 1 | 0 | 1 | 1 | 0 | 0 | 8356 |
| 1 | 0 | 1 | 1 | 0 | 1 | 8796 |
| 1 | 0 | 1 | 1 | 1 | 0 | 8638 |
| 1 | 0 | 1 | 1 | 1 | 1 | 9078 |
| 0 | 1 | 0 | 0 | 0 | 0 | 20928 |
| READ_ONLY | SINGLETON | CACHE | IX_MAP | TEMPORAL_FD_CACHE | MAGIC | Binary size |
| 0 | 1 | 0 | 0 | 0 | 1 | 21072 |
| 0 | 1 | 0 | 0 | 1 | 0 | 21206 |
| 0 | 1 | 0 | 0 | 1 | 1 | 21350 |
| 0 | 1 | 0 | 1 | 0 | 0 | 22220 |
| 0 | 1 | 0 | 1 | 0 | 1 | 22364 |
| 0 | 1 | 0 | 1 | 1 | 0 | 22490 |
| 0 | 1 | 0 | 1 | 1 | 1 | 22634 |
| 0 | 1 | 1 | 0 | 0 | 0 | 23450 |
| 0 | 1 | 1 | 0 | 0 | 1 | 23610 |
| 0 | 1 | 1 | 0 | 1 | 0 | 23724 |
| 0 | 1 | 1 | 0 | 1 | 1 | 23884 |
| 0 | 1 | 1 | 1 | 0 | 0 | 24758 |
| 0 | 1 | 1 | 1 | 0 | 1 | 24918 |
| 0 | 1 | 1 | 1 | 1 | 0 | 25028 |
| 0 | 1 | 1 | 1 | 1 | 1 | 25188 |
| 0 | 0 | 0 | 0 | 0 | 0 | 23144 |
| 0 | 0 | 0 | 0 | 0 | 1 | 23640 |
| 0 | 0 | 0 | 0 | 1 | 0 | 23450 |
| 0 | 0 | 0 | 0 | 1 | 1 | 23942 |
| 0 | 0 | 0 | 1 | 0 | 0 | 24556 |
| 0 | 0 | 0 | 1 | 0 | 1 | 25048 |
| 0 | 0 | 0 | 1 | 1 | 0 | 24854 |
| 0 | 0 | 0 | 1 | 1 | 1 | 25346 |
| 0 | 0 | 1 | 0 | 0 | 0 | 25744 |
| 0 | 0 | 1 | 0 | 0 | 1 | 26260 |
| 0 | 0 | 1 | 0 | 1 | 0 | 26042 |
| 0 | 0 | 1 | 0 | 1 | 1 | 26558 |
| 0 | 0 | 1 | 1 | 0 | 0 | 27172 |
| 0 | 0 | 1 | 1 | 0 | 1 | 27688 |
| 0 | 0 | 1 | 1 | 1 | 0 | 27470 |
| 0 | 0 | 1 | 1 | 1 | 1 | 27986 |