
-
Following the pandemic, the airline industry suffered a massive setback, with ICAO estimating a 371 billion dollar loss in 2020, and a 329 billion dollar loss with reduced seat capacity. As a result, in order to revitalise the industry in the face of the current recession, it is absolutely necessary to understand the customer pain points and improve their satisfaction with the services provided.
-
This data set contains a survey on air passenger satisfaction survey.Need to predict Airline passenger satisfaction level:1.Satisfaction 2.Neutral or dissatisfied.
-
Select the best predictive models for predicting passengers satisfaction.
-
This is a binary classification problem,it is necessary to predict which of the two levels of satisfaction with the airline the passenger belongs to:Satisfaction, Neutral or dissatisfied
-
Before diving into the data, thinking intuitively and being an avid traveller myself, from my experience, the main factors should be:
-
Delays in the flight
-
Staff efficiency to address customer needs
-
Services provided in the flight
## Data Analysis packages
import numpy as np
import pandas as pd
## Data Visualization packages
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
import matplotlib
%matplotlib inline
from pylab import rcParams
import missingno as msno
## General Tools
import os
import re
import joblib
import json
import warnings
# sklearn library
import sklearn
### sklearn preprocessing tools
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import StratifiedKFold,train_test_split
from sklearn.metrics import classification_report,confusion_matrix,roc_curve,auc,accuracy_score,roc_auc_score
from sklearn.preprocessing import StandardScaler, RobustScaler, QuantileTransformer, PowerTransformer,FunctionTransformer,OneHotEncoder
# Error Metrics
from sklearn.metrics import r2_score #r2 square
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score, precision_score,recall_score,f1_score
### Machine learning classification Models
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import SGDClassifier #stacstic gradient descent clasifeier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost.sklearn import XGBClassifier
from sklearn.naive_bayes import GaussianNB
import lightgbm as lgb
from sklearn.ensemble import AdaBoostClassifier
#crossvalidation
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import LeaveOneOut
#from sklearn.metrics import plot_confusion_matrix
#hyper parameter tunning
from sklearn.model_selection import GridSearchCV,cross_val_score,RandomizedSearchCV- The dataset is from Kaggle. it provides cutting-edge data science, faster and better than most people ever thought possible. Kaggle offers both public and private data science competitions and on-demand consulting by an elite global talent pool.
- When you execute od.download, you will be asked to provide your Kaggle username and API key. Follow these instructions to create an API key: http://bit.ly/kaggle-creds
- Dataset link https://www.kaggle.com/datasets/teejmahal20/airline-passenger-satisfaction
There is the following information about the passengers of some airline:
- Gender: male or female
- Customer type: regular or non-regular airline customer
- Age: the actual age of the passenger
- Type of travel: the purpose of the passenger's flight (personal or business travel)
- Class: business, economy, economy plus
- Flight distance
- Inflight wifi service: satisfaction level with Wi-Fi service on board (0: not rated; 1-5)
- Departure/Arrival time convenient: departure/arrival time satisfaction level (0: not rated; 1-5)
- Ease of Online booking: online booking satisfaction rate (0: not rated; 1-5)
- Gate location: level of satisfaction with the gate location (0: not rated; 1-5)
- Food and drink: food and drink satisfaction level (0: not rated; 1-5)
- Online boarding: satisfaction level with online boarding (0: not rated; 1-5)
- Seat comfort: seat satisfaction level (0: not rated; 1-5)
- Inflight entertainment: satisfaction with inflight entertainment (0: not rated; 1-5)
- On-board service: level of satisfaction with on-board service (0: not rated; 1-5)
- Leg room service: level of satisfaction with leg room service (0: not rated; 1-5)
- Baggage handling: level of satisfaction with baggage handling (0: not rated; 1-5)
- Checkin service: level of satisfaction with checkin service (0: not rated; 1-5)
- Inflight service: level of satisfaction with inflight service (0: not rated; 1-5)
- Cleanliness: level of satisfaction with cleanliness (0: not rated; 1-5)
- Departure delay in minutes:
- Arrival delay in minutes:
- Satisfaction: Airline satisfaction level(Satisfaction, neutral or dissatisfaction).
Train Dataset
train_df = pd.read_csv("./data/train.csv")
train_df.head()| Unnamed: 0 | id | Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | ... | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 70172 | Male | Loyal Customer | 13 | Personal Travel | Eco Plus | 460 | 3 | 4 | ... | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 | neutral or dissatisfied |
| 1 | 1 | 5047 | Male | disloyal Customer | 25 | Business travel | Business | 235 | 3 | 2 | ... | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 | neutral or dissatisfied |
| 2 | 2 | 110028 | Female | Loyal Customer | 26 | Business travel | Business | 1142 | 2 | 2 | ... | 5 | 4 | 3 | 4 | 4 | 4 | 5 | 0 | 0.0 | satisfied |
| 3 | 3 | 24026 | Female | Loyal Customer | 25 | Business travel | Business | 562 | 2 | 5 | ... | 2 | 2 | 5 | 3 | 1 | 4 | 2 | 11 | 9.0 | neutral or dissatisfied |
| 4 | 4 | 119299 | Male | Loyal Customer | 61 | Business travel | Business | 214 | 3 | 3 | ... | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 0 | 0.0 | satisfied |
5 rows × 25 columns
## Initial Statistical description
train_df.describe()| Unnamed: 0 | id | Age | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103904.000000 | 103594.000000 |
| mean | 51951.500000 | 64924.210502 | 39.379706 | 1189.448375 | 2.729683 | 3.060296 | 2.756901 | 2.976883 | 3.202129 | 3.250375 | 3.439396 | 3.358158 | 3.382363 | 3.351055 | 3.631833 | 3.304290 | 3.640428 | 3.286351 | 14.815618 | 15.178678 |
| std | 29994.645522 | 37463.812252 | 15.114964 | 997.147281 | 1.327829 | 1.525075 | 1.398929 | 1.277621 | 1.329533 | 1.349509 | 1.319088 | 1.332991 | 1.288354 | 1.315605 | 1.180903 | 1.265396 | 1.175663 | 1.312273 | 38.230901 | 38.698682 |
| min | 0.000000 | 1.000000 | 7.000000 | 31.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 25975.750000 | 32533.750000 | 27.000000 | 414.000000 | 2.000000 | 2.000000 | 2.000000 | 2.000000 | 2.000000 | 2.000000 | 2.000000 | 2.000000 | 2.000000 | 2.000000 | 3.000000 | 3.000000 | 3.000000 | 2.000000 | 0.000000 | 0.000000 |
| 50% | 51951.500000 | 64856.500000 | 40.000000 | 843.000000 | 3.000000 | 3.000000 | 3.000000 | 3.000000 | 3.000000 | 3.000000 | 4.000000 | 4.000000 | 4.000000 | 4.000000 | 4.000000 | 3.000000 | 4.000000 | 3.000000 | 0.000000 | 0.000000 |
| 75% | 77927.250000 | 97368.250000 | 51.000000 | 1743.000000 | 4.000000 | 4.000000 | 4.000000 | 4.000000 | 4.000000 | 4.000000 | 5.000000 | 4.000000 | 4.000000 | 4.000000 | 5.000000 | 4.000000 | 5.000000 | 4.000000 | 12.000000 | 13.000000 |
| max | 103903.000000 | 129880.000000 | 85.000000 | 4983.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 1592.000000 | 1584.000000 |
Observations
- The average delay in flights are 15 minutes, with a deviation of 38
- Median of the delays are 0, which means 50% of the flights from this data, were not delayed
## removing the first two columns
train_df.drop(["Unnamed: 0", 'id'], axis=1, inplace=True)train_df.head(2)| Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | ... | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Male | Loyal Customer | 13 | Personal Travel | Eco Plus | 460 | 3 | 4 | 3 | 1 | ... | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 | neutral or dissatisfied |
| 1 | Male | disloyal Customer | 25 | Business travel | Business | 235 | 3 | 2 | 3 | 3 | ... | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 | neutral or dissatisfied |
2 rows × 23 columns
## shape of the train dataset
train_df.shape(103904, 23)
train_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 103904 entries, 0 to 103903
Data columns (total 23 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Gender 103904 non-null object
1 Customer Type 103904 non-null object
2 Age 103904 non-null int64
3 Type of Travel 103904 non-null object
4 Class 103904 non-null object
5 Flight Distance 103904 non-null int64
6 Inflight wifi service 103904 non-null int64
7 Departure/Arrival time convenient 103904 non-null int64
8 Ease of Online booking 103904 non-null int64
9 Gate location 103904 non-null int64
10 Food and drink 103904 non-null int64
11 Online boarding 103904 non-null int64
12 Seat comfort 103904 non-null int64
13 Inflight entertainment 103904 non-null int64
14 On-board service 103904 non-null int64
15 Leg room service 103904 non-null int64
16 Baggage handling 103904 non-null int64
17 Checkin service 103904 non-null int64
18 Inflight service 103904 non-null int64
19 Cleanliness 103904 non-null int64
20 Departure Delay in Minutes 103904 non-null int64
21 Arrival Delay in Minutes 103594 non-null float64
22 satisfaction 103904 non-null object
dtypes: float64(1), int64(17), object(5)
memory usage: 18.2+ MB
- Only Arrival Delay in Minutes has null values. Lets visualize to see any patterns in the missing values
msno.matrix(train_df)
Observations
- There are 103904 rows for 23 features in our data
- we see in the training data, that all the datatypes belongs to a numeric class that is int, float and object
- only arrival delay in minutes have some null values
# percentage of null values
train_df.isnull().sum()Gender 0
Customer Type 0
Age 0
Type of Travel 0
Class 0
Flight Distance 0
Inflight wifi service 0
Departure/Arrival time convenient 0
Ease of Online booking 0
Gate location 0
Food and drink 0
Online boarding 0
Seat comfort 0
Inflight entertainment 0
On-board service 0
Leg room service 0
Baggage handling 0
Checkin service 0
Inflight service 0
Cleanliness 0
Departure Delay in Minutes 0
Arrival Delay in Minutes 310
satisfaction 0
dtype: int64
- The number of null values is 310 in "Arrival Delay in Minutes" column
- The percentage of null values is ~ 0.3%
round(train_df.describe().T, 2)| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Age | 103904.0 | 39.38 | 15.11 | 7.0 | 27.0 | 40.0 | 51.0 | 85.0 |
| Flight Distance | 103904.0 | 1189.45 | 997.15 | 31.0 | 414.0 | 843.0 | 1743.0 | 4983.0 |
| Inflight wifi service | 103904.0 | 2.73 | 1.33 | 0.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| Departure/Arrival time convenient | 103904.0 | 3.06 | 1.53 | 0.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| Ease of Online booking | 103904.0 | 2.76 | 1.40 | 0.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| Gate location | 103904.0 | 2.98 | 1.28 | 0.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| Food and drink | 103904.0 | 3.20 | 1.33 | 0.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| Online boarding | 103904.0 | 3.25 | 1.35 | 0.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| Seat comfort | 103904.0 | 3.44 | 1.32 | 0.0 | 2.0 | 4.0 | 5.0 | 5.0 |
| Inflight entertainment | 103904.0 | 3.36 | 1.33 | 0.0 | 2.0 | 4.0 | 4.0 | 5.0 |
| On-board service | 103904.0 | 3.38 | 1.29 | 0.0 | 2.0 | 4.0 | 4.0 | 5.0 |
| Leg room service | 103904.0 | 3.35 | 1.32 | 0.0 | 2.0 | 4.0 | 4.0 | 5.0 |
| Baggage handling | 103904.0 | 3.63 | 1.18 | 1.0 | 3.0 | 4.0 | 5.0 | 5.0 |
| Checkin service | 103904.0 | 3.30 | 1.27 | 0.0 | 3.0 | 3.0 | 4.0 | 5.0 |
| Inflight service | 103904.0 | 3.64 | 1.18 | 0.0 | 3.0 | 4.0 | 5.0 | 5.0 |
| Cleanliness | 103904.0 | 3.29 | 1.31 | 0.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| Departure Delay in Minutes | 103904.0 | 14.82 | 38.23 | 0.0 | 0.0 | 0.0 | 12.0 | 1592.0 |
| Arrival Delay in Minutes | 103594.0 | 15.18 | 38.70 | 0.0 | 0.0 | 0.0 | 13.0 | 1584.0 |
# Duplicate values
train_df.duplicated().sum()0
# target variable
train_df.satisfaction.value_counts()[1]/len(train_df.satisfaction)*10043.333269171542966
- This problem is a binary classification problem of classes 0 or 1 denoting customer satisfaction, The class 1 has 43.33% of total values. Hence, this is a balanced learning problem. hence will not be requiring any resampling techniques to tackle this
train_df.columns[:-1]Index(['Gender', 'Customer Type', 'Age', 'Type of Travel', 'Class',
'Flight Distance', 'Inflight wifi service',
'Departure/Arrival time convenient', 'Ease of Online booking',
'Gate location', 'Food and drink', 'Online boarding', 'Seat comfort',
'Inflight entertainment', 'On-board service', 'Leg room service',
'Baggage handling', 'Checkin service', 'Inflight service',
'Cleanliness', 'Departure Delay in Minutes',
'Arrival Delay in Minutes'],
dtype='object')
Before training a machine learning model, it's always a good idea to explore the distributions of various columns and see how they are related to the target column. Let's explore and visualize the data using the Plotly, Matplotlib and Seaborn libraries.
train_df.corr(numeric_only= True)| Age | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Age | 1.000000 | 0.099461 | 0.017859 | 0.038125 | 0.024842 | -0.001330 | 0.023000 | 0.208939 | 0.160277 | 0.076444 | 0.057594 | 0.040583 | -0.047529 | 0.035482 | -0.049427 | 0.053611 | -0.010152 | -0.012147 |
| Flight Distance | 0.099461 | 1.000000 | 0.007131 | -0.020043 | 0.065717 | 0.004793 | 0.056994 | 0.214869 | 0.157333 | 0.128740 | 0.109526 | 0.133916 | 0.063184 | 0.073072 | 0.057540 | 0.093149 | 0.002158 | -0.002426 |
| Inflight wifi service | 0.017859 | 0.007131 | 1.000000 | 0.343845 | 0.715856 | 0.336248 | 0.134718 | 0.456970 | 0.122658 | 0.209321 | 0.121500 | 0.160473 | 0.120923 | 0.043193 | 0.110441 | 0.132698 | -0.017402 | -0.019095 |
| Departure/Arrival time convenient | 0.038125 | -0.020043 | 0.343845 | 1.000000 | 0.436961 | 0.444757 | 0.004906 | 0.070119 | 0.011344 | -0.004861 | 0.068882 | 0.012441 | 0.072126 | 0.093333 | 0.073318 | 0.014292 | 0.001005 | -0.000864 |
| Ease of Online booking | 0.024842 | 0.065717 | 0.715856 | 0.436961 | 1.000000 | 0.458655 | 0.031873 | 0.404074 | 0.030014 | 0.047032 | 0.038833 | 0.107601 | 0.038762 | 0.011081 | 0.035272 | 0.016179 | -0.006371 | -0.007984 |
| Gate location | -0.001330 | 0.004793 | 0.336248 | 0.444757 | 0.458655 | 1.000000 | -0.001159 | 0.001688 | 0.003669 | 0.003517 | -0.028373 | -0.005873 | 0.002313 | -0.035427 | 0.001681 | -0.003830 | 0.005467 | 0.005143 |
| Food and drink | 0.023000 | 0.056994 | 0.134718 | 0.004906 | 0.031873 | -0.001159 | 1.000000 | 0.234468 | 0.574556 | 0.622512 | 0.059073 | 0.032498 | 0.034746 | 0.087299 | 0.033993 | 0.657760 | -0.029926 | -0.032524 |
| Online boarding | 0.208939 | 0.214869 | 0.456970 | 0.070119 | 0.404074 | 0.001688 | 0.234468 | 1.000000 | 0.420211 | 0.285066 | 0.155443 | 0.123950 | 0.083280 | 0.204462 | 0.074573 | 0.331517 | -0.018982 | -0.021949 |
| Seat comfort | 0.160277 | 0.157333 | 0.122658 | 0.011344 | 0.030014 | 0.003669 | 0.574556 | 0.420211 | 1.000000 | 0.610590 | 0.131971 | 0.105559 | 0.074542 | 0.191854 | 0.069218 | 0.678534 | -0.027898 | -0.029900 |
| Inflight entertainment | 0.076444 | 0.128740 | 0.209321 | -0.004861 | 0.047032 | 0.003517 | 0.622512 | 0.285066 | 0.610590 | 1.000000 | 0.420153 | 0.299692 | 0.378210 | 0.120867 | 0.404855 | 0.691815 | -0.027489 | -0.030703 |
| On-board service | 0.057594 | 0.109526 | 0.121500 | 0.068882 | 0.038833 | -0.028373 | 0.059073 | 0.155443 | 0.131971 | 0.420153 | 1.000000 | 0.355495 | 0.519134 | 0.243914 | 0.550782 | 0.123220 | -0.031569 | -0.035227 |
| Leg room service | 0.040583 | 0.133916 | 0.160473 | 0.012441 | 0.107601 | -0.005873 | 0.032498 | 0.123950 | 0.105559 | 0.299692 | 0.355495 | 1.000000 | 0.369544 | 0.153137 | 0.368656 | 0.096370 | 0.014363 | 0.011843 |
| Baggage handling | -0.047529 | 0.063184 | 0.120923 | 0.072126 | 0.038762 | 0.002313 | 0.034746 | 0.083280 | 0.074542 | 0.378210 | 0.519134 | 0.369544 | 1.000000 | 0.233122 | 0.628561 | 0.095793 | -0.005573 | -0.008542 |
| Checkin service | 0.035482 | 0.073072 | 0.043193 | 0.093333 | 0.011081 | -0.035427 | 0.087299 | 0.204462 | 0.191854 | 0.120867 | 0.243914 | 0.153137 | 0.233122 | 1.000000 | 0.237197 | 0.179583 | -0.018453 | -0.020369 |
| Inflight service | -0.049427 | 0.057540 | 0.110441 | 0.073318 | 0.035272 | 0.001681 | 0.033993 | 0.074573 | 0.069218 | 0.404855 | 0.550782 | 0.368656 | 0.628561 | 0.237197 | 1.000000 | 0.088779 | -0.054813 | -0.059196 |
| Cleanliness | 0.053611 | 0.093149 | 0.132698 | 0.014292 | 0.016179 | -0.003830 | 0.657760 | 0.331517 | 0.678534 | 0.691815 | 0.123220 | 0.096370 | 0.095793 | 0.179583 | 0.088779 | 1.000000 | -0.014093 | -0.015774 |
| Departure Delay in Minutes | -0.010152 | 0.002158 | -0.017402 | 0.001005 | -0.006371 | 0.005467 | -0.029926 | -0.018982 | -0.027898 | -0.027489 | -0.031569 | 0.014363 | -0.005573 | -0.018453 | -0.054813 | -0.014093 | 1.000000 | 0.965481 |
| Arrival Delay in Minutes | -0.012147 | -0.002426 | -0.019095 | -0.000864 | -0.007984 | 0.005143 | -0.032524 | -0.021949 | -0.029900 | -0.030703 | -0.035227 | 0.011843 | -0.008542 | -0.020369 | -0.059196 | -0.015774 | 0.965481 | 1.000000 |
plt.figure(figsize=(20, 10))
sns.heatmap(train_df.corr(numeric_only= True), annot=True, vmax=1, cmap='coolwarm')
plt.show()
- departure delay in minutes and arrival dalay in minutes are highly co-related!
sns.set(rc={
"font.size":15,
"axes.titlesize":10,
"axes.labelsize":15},
style="darkgrid")
fig, axs = plt.subplots(6, 3, figsize=(20,30))
fig.tight_layout(pad=4.0)
for f, ax in zip(train_df, axs.ravel()):
sns.set(font_scale = 2)
ax = sns.histplot(ax=ax, data=train_df, x=train_df[f], kde=True, color='purple')
ax.set_title(f)
new_train_df = train_df.copy()new_train_df.drop(['Age','Flight Distance','Departure Delay in Minutes', 'Arrival Delay in Minutes','satisfaction'], axis=1, inplace=True)sns.set(rc={
"font.size":10,
"axes.titlesize":10,
"axes.labelsize":13},
style="darkgrid")
fig, axes = plt.subplots(6, 3, figsize = (20, 30))
for i, col in enumerate(new_train_df):
column_values = new_train_df[col].value_counts()
labels = column_values.index
sizes = column_values.values
axes[i//3, i%3].pie(sizes,labels = labels, colors = sns.color_palette("RdGy_r"),autopct = '%1.0f%%', startangle = 90)
axes[i//3, i%3].axis('equal')
axes[i//3, i%3].set_title(col)
plt.show()
Observations:
- The number of men and women in this sample is approximately the same
- The vast majority of the airline's customers are repeat customers
- Most of the clients flew for business rather than personal reasons
- About half of the passengers were in business class
- More than 60% of passengers were satisfied with the luggage transportation service(rated 4-5 out of 5)
- More than 50% of pessengers were compfortable sitting in thier seats(rated 4-5 out of 5)
## Satisfactiontrain_df.satisfaction.value_counts()neutral or dissatisfied 58879
satisfied 45025
Name: satisfaction, dtype: int64
fig, (ax1,ax2) = plt.subplots(1,2,figsize=(15,6))
train_df.satisfaction.value_counts().plot.pie(explode=(0, 0.05), colors=sns.color_palette("RdYlBu"),autopct='%1.1f%%',ax=ax1)
ax1.set_title("Percentage of Satisfaction")
sns.countplot(x= "satisfaction", data=train_df, ax=ax2, palette='RdYlBu')
ax2.set_title("Distribution of Satisfaction")Text(0.5, 1.0, 'Distribution of Satisfaction')

Observation:
- As per the given data, 56.7% people are dissatisfied and neutral
- And 43.3 people are satisfied
To analyse and visualise the data lets divide data columns into categorical and numerical columns.
# numerical and categorical features
numerical_cols = train_df.select_dtypes(include=np.number).columns.to_list()
categorical_cols = train_df.select_dtypes('object').columns.to_list()#numerical columns
print("Total number of columns are:",len(numerical_cols))
print(numerical_cols)Total number of columns are: 18
['Age', 'Flight Distance', 'Inflight wifi service', 'Departure/Arrival time convenient', 'Ease of Online booking', 'Gate location', 'Food and drink', 'Online boarding', 'Seat comfort', 'Inflight entertainment', 'On-board service', 'Leg room service', 'Baggage handling', 'Checkin service', 'Inflight service', 'Cleanliness', 'Departure Delay in Minutes', 'Arrival Delay in Minutes']
#Categorical Columns
print("Total number of columns are:",len(categorical_cols))
print(categorical_cols)Total number of columns are: 5
['Gender', 'Customer Type', 'Type of Travel', 'Class', 'satisfaction']
categorical_cols.remove('satisfaction')sns.set(rc={
"font.size":10,
"axes.titlesize":10,
"axes.labelsize":15},
style="darkgrid",
)
fig, axs = plt.subplots(6, 3, figsize=(15, 30))
fig.tight_layout(pad=3.0)
for f, ax in zip(numerical_cols, axs.ravel()):
sns.set(font_scale=2)
ax= sns.boxplot(ax=ax, data=train_df, y=train_df[f], palette='BuGn')
Observations:
Flight distance, checkin service, Departure Delay in minutes, Arrival delay in minutes has some outliers
sns.set(rc={'figure.figsize':(8,6),
"font.size":10,
"axes.titlesize":10,
"axes.labelsize":15},
style="darkgrid")
for col in numerical_cols:
sns.barplot(data=train_df, x="satisfaction", y=col, palette='BuGn')
plt.show()

















Observations:
- From above graphs,it is clear that the age and Gate location, does not play a huge role in flight satisfaction.
- And also the gender does not tell us mush as seen in the earlier plot. hence we can rop these values
sns.set(rc={'figure.figsize':(11.7,8.27),
"font.size":10,
"axes.titlesize":10,
"axes.labelsize":15},
style="darkgrid",
)
for col in categorical_cols:
plt.figure(figsize=(8, 6))
sns.countplot(data=train_df,x=col, hue='satisfaction', palette='PuRd_r')
plt.legend(loc=(1.05,0.5))




Observations:
- Gender doesn't play an important role in the satisfaction, as men and women seems to equally concerned about the same factors
- Number of loyal customers for this airline is high, however, the dissatisfaction level is high irrespective of the loyalty. Airline will have to work on maintaining the loyal customers
- Business Travellers seems to be more satisfied with the flight, than the personal travellers
- People in business class seems to be the most satisfied lot, and those in economy class are least satisfied
train_df.groupby('satisfaction')['Arrival Delay in Minutes'].mean()satisfaction
neutral or dissatisfied 17.127536
satisfied 12.630799
Name: Arrival Delay in Minutes, dtype: float64
sns.set(rc={
"font.size":10,
"axes.titlesize":10,
"axes.labelsize":13},
style="darkgrid")
plt.figure(figsize=(10, 5), dpi=100)
sns.scatterplot(data=train_df, x="Arrival Delay in Minutes", y= "Departure Delay in Minutes", hue='satisfaction', palette="magma_r",alpha=0.8)<Axes: xlabel='Arrival Delay in Minutes', ylabel='Departure Delay in Minutes'>

Observations:
The arrival and departure delay seems to have a linear relationship, which makes complete sense! And well, there is 1 customer who was satisfied even after a delay of 1300 minutes!!
sns.set(rc={
"font.size":10,
"axes.titlesize":10,
"axes.labelsize":13},
style="darkgrid")
plt.figure(figsize=(10, 5), dpi=100)
sns.scatterplot(data=train_df, x="Flight Distance", y= "Departure Delay in Minutes", hue='satisfaction', palette="magma_r",alpha=0.8)
plt.ylim(0,1000)(0.0, 1000.0)

Observations:
- The most important takeaway here is the longer the flight distance, most passengers are okay with flight delay in departure, which is strance finding from this plot!
- So departure delay is less of a factor for a long distance flight, comparitively, however, short distance travellers does not seem to be excited about the departure delays, which also makes sense
f, ax = plt.subplots(1,2, figsize=(15, 5))
sns.boxplot(data=train_df, x="Customer Type", y= "Age",palette = "gnuplot2_r", ax=ax[0])
sns.histplot(data=train_df, x="Age", hue="Customer Type", multiple="stack", palette = "gnuplot2_r",edgecolor = ".3", linewidth = .5, ax = ax[1])<Axes: xlabel='Age', ylabel='Count'>

Observations:
- From above we can conclude that most of the airline's regular customers are between the ages of 30 and 50(their average age is slightly above 40)
- The age range of non-regular customers is slightly smaller (from 25 to 40 years old, on average - a little less than 30).
f, ax =plt.subplots(1,2,figsize=(15,5))
sns.boxplot(data=train_df, x="Class", y="Age",palette = "gnuplot2_r", ax=ax[0])
sns.histplot(data=train_df, x="Age", hue="Class", multiple="stack", palette="gnuplot2_r",edgecolor = ".3", linewidth = .5, ax = ax[1])<Axes: xlabel='Age', ylabel='Count'>

- It can be seen that, on average, the age range of those customers who travel in business class is the same (according to the previous box chart) as the age range of regular customers. Based on this observation, it can be assumed that regular customers mainly buy business class for themselves.
f, ax = plt.subplots(1, 2, figsize = (15,5))
sns.boxplot(x = "Class", y = "Flight Distance", palette = "gnuplot2_r", data = train_df, ax = ax[0])
sns.histplot(train_df, x = "Flight Distance", hue = "Class", multiple = "stack", palette = "gnuplot2_r", edgecolor = ".3", linewidth = .5, ax = ax[1])<Axes: xlabel='Flight Distance', ylabel='Count'>

Observations:
- customers whose flight distance is long, mostly fly in business class.
f,ax = plt.subplots(2,2, figsize=(15, 8))
sns.boxplot(x = "Inflight entertainment", y = "Flight Distance", palette = "gnuplot2_r", data = train_df, ax = ax[0, 0])
sns.histplot(train_df, x = "Flight Distance", hue = "Inflight entertainment", multiple = "stack", palette = "gnuplot2_r", edgecolor = ".3", linewidth = .5, ax = ax[0, 1])
sns.boxplot(x = "Leg room service", y = "Flight Distance", palette = "gnuplot2_r", data = train_df, ax = ax[1, 0])
sns.histplot(train_df, x = "Flight Distance", hue = "Leg room service", multiple = "stack", palette = "gnuplot2_r", edgecolor = ".3", linewidth = .5, ax = ax[1, 1])<Axes: xlabel='Flight Distance', ylabel='Count'>

Observations:
- The more distance an aircraft passenger travels (respectively, the longer they are in flight)
- The more they are satisfied with the entertainment in flight and the extra legroom (on average).
input_cols = list(train_df.iloc[:, :-1])
target_cols = "satisfaction"pd.options.display.max_columns=30train_df.head()| Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Male | Loyal Customer | 13 | Personal Travel | Eco Plus | 460 | 3 | 4 | 3 | 1 | 5 | 3 | 5 | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 | neutral or dissatisfied |
| 1 | Male | disloyal Customer | 25 | Business travel | Business | 235 | 3 | 2 | 3 | 3 | 1 | 3 | 1 | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 | neutral or dissatisfied |
| 2 | Female | Loyal Customer | 26 | Business travel | Business | 1142 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 4 | 3 | 4 | 4 | 4 | 5 | 0 | 0.0 | satisfied |
| 3 | Female | Loyal Customer | 25 | Business travel | Business | 562 | 2 | 5 | 5 | 5 | 2 | 2 | 2 | 2 | 2 | 5 | 3 | 1 | 4 | 2 | 11 | 9.0 | neutral or dissatisfied |
| 4 | Male | Loyal Customer | 61 | Business travel | Business | 214 | 3 | 3 | 3 | 3 | 4 | 5 | 5 | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 0 | 0.0 | satisfied |
train_df["Gender"] = pd.get_dummies(train_df["Gender"], drop_first=True, dtype="int")train_df["Customer Type"]= pd.get_dummies(train_df["Customer Type"], drop_first=True, dtype="int")train_df["Type of Travel"]= pd.get_dummies(train_df["Type of Travel"], drop_first=True, dtype="int")from sklearn.preprocessing import LabelEncoderle = LabelEncoder()train_df["Class"]=le.fit_transform(train_df["Class"])train_df["Class"]0 2
1 0
2 0
3 0
4 0
..
103899 1
103900 0
103901 0
103902 1
103903 0
Name: Class, Length: 103904, dtype: int32
train_df["Arrival Delay in Minutes"]0 18.0
1 6.0
2 0.0
3 9.0
4 0.0
...
103899 0.0
103900 0.0
103901 14.0
103902 0.0
103903 0.0
Name: Arrival Delay in Minutes, Length: 103904, dtype: float64
from sklearn.impute import SimpleImputermedian=train_df["Arrival Delay in Minutes"].median()train_df["Arrival Delay in Minutes"].fillna(median, inplace=True)train_df.isnull().sum()Gender 0
Customer Type 0
Age 0
Type of Travel 0
Class 0
Flight Distance 0
Inflight wifi service 0
Departure/Arrival time convenient 0
Ease of Online booking 0
Gate location 0
Food and drink 0
Online boarding 0
Seat comfort 0
Inflight entertainment 0
On-board service 0
Leg room service 0
Baggage handling 0
Checkin service 0
Inflight service 0
Cleanliness 0
Departure Delay in Minutes 0
Arrival Delay in Minutes 0
satisfaction 0
dtype: int64
train_df| Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 13 | 1 | 2 | 460 | 3 | 4 | 3 | 1 | 5 | 3 | 5 | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 | neutral or dissatisfied |
| 1 | 1 | 1 | 25 | 0 | 0 | 235 | 3 | 2 | 3 | 3 | 1 | 3 | 1 | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 | neutral or dissatisfied |
| 2 | 0 | 0 | 26 | 0 | 0 | 1142 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 4 | 3 | 4 | 4 | 4 | 5 | 0 | 0.0 | satisfied |
| 3 | 0 | 0 | 25 | 0 | 0 | 562 | 2 | 5 | 5 | 5 | 2 | 2 | 2 | 2 | 2 | 5 | 3 | 1 | 4 | 2 | 11 | 9.0 | neutral or dissatisfied |
| 4 | 1 | 0 | 61 | 0 | 0 | 214 | 3 | 3 | 3 | 3 | 4 | 5 | 5 | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 0 | 0.0 | satisfied |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 103899 | 0 | 1 | 23 | 0 | 1 | 192 | 2 | 1 | 2 | 3 | 2 | 2 | 2 | 2 | 3 | 1 | 4 | 2 | 3 | 2 | 3 | 0.0 | neutral or dissatisfied |
| 103900 | 1 | 0 | 49 | 0 | 0 | 2347 | 4 | 4 | 4 | 4 | 2 | 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 4 | 0 | 0.0 | satisfied |
| 103901 | 1 | 1 | 30 | 0 | 0 | 1995 | 1 | 1 | 1 | 3 | 4 | 1 | 5 | 4 | 3 | 2 | 4 | 5 | 5 | 4 | 7 | 14.0 | neutral or dissatisfied |
| 103902 | 0 | 1 | 22 | 0 | 1 | 1000 | 1 | 1 | 1 | 5 | 1 | 1 | 1 | 1 | 4 | 5 | 1 | 5 | 4 | 1 | 0 | 0.0 | neutral or dissatisfied |
| 103903 | 1 | 0 | 27 | 0 | 0 | 1723 | 1 | 3 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | 3 | 1 | 0 | 0.0 | neutral or dissatisfied |
103904 rows × 23 columns
train_df["satisfaction"] = le.fit_transform(train_df["satisfaction"])train_df| Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 13 | 1 | 2 | 460 | 3 | 4 | 3 | 1 | 5 | 3 | 5 | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 | 0 |
| 1 | 1 | 1 | 25 | 0 | 0 | 235 | 3 | 2 | 3 | 3 | 1 | 3 | 1 | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 | 0 |
| 2 | 0 | 0 | 26 | 0 | 0 | 1142 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 4 | 3 | 4 | 4 | 4 | 5 | 0 | 0.0 | 1 |
| 3 | 0 | 0 | 25 | 0 | 0 | 562 | 2 | 5 | 5 | 5 | 2 | 2 | 2 | 2 | 2 | 5 | 3 | 1 | 4 | 2 | 11 | 9.0 | 0 |
| 4 | 1 | 0 | 61 | 0 | 0 | 214 | 3 | 3 | 3 | 3 | 4 | 5 | 5 | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 0 | 0.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 103899 | 0 | 1 | 23 | 0 | 1 | 192 | 2 | 1 | 2 | 3 | 2 | 2 | 2 | 2 | 3 | 1 | 4 | 2 | 3 | 2 | 3 | 0.0 | 0 |
| 103900 | 1 | 0 | 49 | 0 | 0 | 2347 | 4 | 4 | 4 | 4 | 2 | 4 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 4 | 0 | 0.0 | 1 |
| 103901 | 1 | 1 | 30 | 0 | 0 | 1995 | 1 | 1 | 1 | 3 | 4 | 1 | 5 | 4 | 3 | 2 | 4 | 5 | 5 | 4 | 7 | 14.0 | 0 |
| 103902 | 0 | 1 | 22 | 0 | 1 | 1000 | 1 | 1 | 1 | 5 | 1 | 1 | 1 | 1 | 4 | 5 | 1 | 5 | 4 | 1 | 0 | 0.0 | 0 |
| 103903 | 1 | 0 | 27 | 0 | 0 | 1723 | 1 | 3 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | 3 | 1 | 0 | 0.0 | 0 |
103904 rows × 23 columns
train_df.to_csv(path_or_buf="processed_data/train_df.csv", index=False)train_df = pd.read_csv('processed_data/train_df.csv')train_df.head()| Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 13 | 1 | 2 | 460 | 3 | 4 | 3 | 1 | 5 | 3 | 5 | 5 | 4 | 3 | 4 | 4 | 5 | 5 | 25 | 18.0 | 0 |
| 1 | 1 | 1 | 25 | 0 | 0 | 235 | 3 | 2 | 3 | 3 | 1 | 3 | 1 | 1 | 1 | 5 | 3 | 1 | 4 | 1 | 1 | 6.0 | 0 |
| 2 | 0 | 0 | 26 | 0 | 0 | 1142 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 4 | 3 | 4 | 4 | 4 | 5 | 0 | 0.0 | 1 |
| 3 | 0 | 0 | 25 | 0 | 0 | 562 | 2 | 5 | 5 | 5 | 2 | 2 | 2 | 2 | 2 | 5 | 3 | 1 | 4 | 2 | 11 | 9.0 | 0 |
| 4 | 1 | 0 | 61 | 0 | 0 | 214 | 3 | 3 | 3 | 3 | 4 | 5 | 5 | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 0 | 0.0 | 1 |
from sklearn.model_selection import train_test_splittrain_val_df, test_df = train_test_split(train_df, test_size=0.2, random_state=42)train_df, val_df = train_test_split(train_val_df, test_size=0.25, random_state=42)print(train_df.shape)
print(val_df.shape)
print(test_df.shape)(62342, 23)
(20781, 23)
(20781, 23)
# train_df['satisfaction'] = train_df['satisfaction'].map({'neutral or dissatisfied':0 , 'satisfied':1})
# val_df['satisfaction'] = val_df['satisfaction'].map({'neutral or dissatisfied':0 , 'satisfied':1})
# test_df['satisfaction'] = test_df['satisfaction'].map({'neutral or dissatisfied':0 , 'satisfied':1})train_df| Gender | Customer Type | Age | Type of Travel | Class | Flight Distance | Inflight wifi service | Departure/Arrival time convenient | Ease of Online booking | Gate location | Food and drink | Online boarding | Seat comfort | Inflight entertainment | On-board service | Leg room service | Baggage handling | Checkin service | Inflight service | Cleanliness | Departure Delay in Minutes | Arrival Delay in Minutes | satisfaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 83488 | 0 | 0 | 51 | 1 | 0 | 366 | 2 | 1 | 2 | 3 | 3 | 3 | 3 | 4 | 4 | 2 | 1 | 4 | 4 | 4 | 0 | 0.0 | 0 |
| 31648 | 0 | 0 | 38 | 1 | 1 | 109 | 4 | 3 | 4 | 4 | 5 | 4 | 5 | 5 | 1 | 1 | 4 | 5 | 1 | 5 | 0 | 2.0 | 1 |
| 22340 | 1 | 0 | 50 | 1 | 1 | 78 | 3 | 5 | 3 | 3 | 5 | 3 | 4 | 5 | 3 | 1 | 3 | 3 | 4 | 5 | 0 | 0.0 | 0 |
| 68992 | 0 | 0 | 43 | 0 | 0 | 1770 | 5 | 5 | 5 | 5 | 5 | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 3 | 17 | 8.0 | 1 |
| 100108 | 1 | 0 | 19 | 1 | 1 | 762 | 3 | 5 | 3 | 3 | 2 | 3 | 4 | 2 | 4 | 3 | 5 | 4 | 5 | 2 | 0 | 0.0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 44593 | 1 | 0 | 54 | 0 | 2 | 989 | 4 | 3 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 5 | 4 | 3 | 4 | 4 | 25 | 17.0 | 0 |
| 59278 | 1 | 0 | 60 | 0 | 0 | 3358 | 0 | 4 | 0 | 2 | 2 | 5 | 4 | 5 | 5 | 5 | 5 | 3 | 5 | 5 | 0 | 0.0 | 1 |
| 29978 | 1 | 0 | 58 | 1 | 2 | 787 | 3 | 4 | 3 | 2 | 4 | 3 | 3 | 4 | 3 | 5 | 5 | 5 | 4 | 4 | 0 | 0.0 | 0 |
| 92224 | 0 | 0 | 57 | 1 | 1 | 431 | 0 | 5 | 0 | 2 | 2 | 5 | 5 | 5 | 5 | 0 | 5 | 3 | 5 | 5 | 0 | 0.0 | 1 |
| 67702 | 0 | 0 | 36 | 1 | 1 | 227 | 1 | 5 | 1 | 1 | 1 | 1 | 1 | 1 | 4 | 2 | 5 | 5 | 5 | 1 | 0 | 0.0 | 0 |
62342 rows × 23 columns
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()# select the columns to be used for training/prediction
# training dataset
X_train_ = train_df.drop("satisfaction", axis=1)
X_train = scaler.fit_transform(X_train_) ##scaled
y_train = train_df.satisfactionX_val_ = val_df.drop("satisfaction", axis=1)
X_val = scaler.transform(X_val_) ##scaled
y_val = val_df.satisfactionX_test_ = test_df.drop("satisfaction", axis=1)
X_test = scaler.transform(X_test_) ##scaled
y_test = test_df.satisfactiondef plot_roc_curve(y_true,y_prob_preds,ax):
"""
To plot the ROC curve for the given predictions and model
"""
fpr,tpr,threshold = roc_curve(y_true,y_prob_preds)
roc_auc = auc(fpr,tpr)
ax.plot(fpr,tpr,"b",label="AUC = %0.2f" % roc_auc)
ax.set_title("Receiver Operating Characteristic")
ax.legend(loc='lower right')
ax.plot([0,1],[0,1],'r--')
ax.set_xlim([0,1])
ax.set_ylim([0,1])
ax.set_xlabel("False Positive Rate")
ax.set_ylabel("True Positive Rate");
plt.show();def plot_confustion_matrix(y_true,y_preds,axes,name=''):
"""
To plot the Confusion Matrix for the given predictions
"""
cm = confusion_matrix(y_true, y_preds)
group_names = ['TN','FP','FN','TP']
group_percentages = ["{0:.2%}".format(value) for value in cm.flatten()/np.sum(cm)]
group_counts = ["{0:0.0f}".format(value) for value in cm.flatten()]
labels = [f"{v1}\n{v2}\n{v3}" for v1, v2, v3 in zip(group_names,group_counts,group_percentages)]
labels = np.asarray(labels).reshape(2,2)
sns.heatmap(cm, annot=labels, fmt='', cmap='Blues',ax=axes)
axes.set_ylim([2,0])
axes.set_xlabel('Prediction')
axes.set_ylabel('Actual')
axes.set_title(f'{name} Confusion Matrix');def make_classification_report(model,inputs,targets,model_name=None,record=False):
"""
To Generate the classification report with all the metrics of a given model with confusion matrix as well as ROC AUC curve.
"""
### Getting the model name from model object
if model_name is None:
model_name = str(type(model)).split(".")[-1][0:-2]
### Making the predictions for the given model
preds = model.predict(inputs)
if model_name in ["LinearSVC"]:
prob_preds = model.decision_function(inputs)
else:
prob_preds = model.predict_proba(inputs)[:,1]
### printing the ROC AUC score
auc_score = roc_auc_score(targets,prob_preds)
print("ROC AUC Score : {:.2f}%\n".format(auc_score * 100.0))
### Plotting the Confusion Matrix and ROC AUC Curve
fig, axes = plt.subplots(1, 2, figsize=(18,6))
plot_confustion_matrix(targets,preds,axes[0],model_name)
plot_roc_curve(targets,prob_preds,axes[1])
This type of statistical model (also known as logit model) is often used for classification and predictive analytics. Logistic regression estimates the probability of an event occurring, such as voted or didn’t vote, based on a given dataset of independent variables. Since the outcome is a probability, the dependent variable is bounded between 0 and 1.
In logistic regression, a logit transformation is applied on the odds—that is, the probability of success divided by the probability of failure. This is also commonly known as the log odds, or the natural logarithm of odds, and this logistic function is represented by the following formulas:
Logit(pi) = 1/(1+ exp(-pi))
ln(pi/(1-pi)) = Beta_0 + Beta_1X_1 + … + B_kK_k

In this logistic regression equation, logit(pi) is the dependent or response variable and x is the independent variable. The beta parameter, or coefficient, in this model is commonly estimated via maximum likelihood estimation (MLE). This method tests different values of beta through multiple iterations to optimize for the best fit of log odds. All of these iterations produce the log likelihood function, and logistic regression seeks to maximize this function to find the best parameter estimate. Once the optimal coefficient (or coefficients if there is more than one independent variable) is found, the conditional probabilities for each observation can be calculated, logged, and summed together to yield a predicted probability.
For binary classification, a probability less than .5 will predict 0 while a probability greater than 0 will predict 1. After the model has been computed, it’s best practice to evaluate the how well the model predicts the dependent variable, which is called goodness of fit.

# Import the model
from sklearn.linear_model import LogisticRegression
#fit the model
model = LogisticRegression()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_test)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) LOGISTICREGRESSION MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.88 0.90 0.89 35308
satisfaction 0.87 0.83 0.85 27034
accuracy 0.87 62342
macro avg 0.87 0.87 0.87 62342
weighted avg 0.87 0.87 0.87 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.57 0.58 0.58 11858
satisfaction 0.43 0.42 0.43 8923
accuracy 0.51 20781
macro avg 0.50 0.50 0.50 20781
weighted avg 0.51 0.51 0.51 20781
Accuracy score for training dataset 0.874161881235764
Accuracy score for validation dataset 0.5129685770655887
ROC AUC Score : 92.65%

Observations
- The auc roc score is 92.65 %
- But this model is not working good with validation data. And also not predecting the True Positives.
Naive Bayes classifiers are a collection of classification algorithms based on Bayes’ Theorem. It is not a single algorithm but a family of algorithms where all of them share a common principle, i.e. every pair of features being classified is independent of each other.
Note: The assumptions made by Naive Bayes are not generally correct in real-world situations. In-fact, the independence assumption is never correct but often works well in practice.
Bayes’ Theorem
Bayes’ Theorem finds the probability of an event occurring given the probability of another event that has already occurred. Bayes’ theorem is stated mathematically as the following equation:

where A and B are events and P(B) ≠ 0.
Basically, we are trying to find the probability of event A, given the event B is true. Event B is also termed as evidence.
- P(A) is the priori of A (the prior probability, i.e. Probability of event before evidence is seen). The evidence is an attribute value of an unknown instance(here, it is event B).
- P(A|B) is a posteriori probability of B, i.e. probability of event after evidence is seen.
Now, with regards to our dataset, we can apply Bayes’ theorem in following way:

where, y is class variable and X is a dependent feature vector (of size n)

After substituting and solving the above equation we get the below

Now, To create a classifier model. we need to find the probability of given set of inputs for all possible values of the class variable y and pick up the output with maximum probability. This can be expressed mathematically as:

So, finally, we are left with the task of calculating P(y) and P(xi | y).
Please note that P(y) is also called class probability and P(xi | y) is called conditional probability.
The different naive Bayes classifiers differ mainly by the assumptions they make regarding the distribution of P(xi | y).
Gaussian Naive Bayes classifier
In Gaussian Naive Bayes, continuous values associated with each feature are assumed to be distributed according to a Gaussian distribution. A Gaussian distribution is also called Normal distribution. When plotted, it gives a bell shaped curve which is symmetric about the mean of the feature values as shown below:
The likelihood of the features is assumed to be Gaussian, hence, conditional probability is given by:

# import the model
from sklearn.naive_bayes import GaussianNB
#fit the model
model =GaussianNB()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) GAUSSIANNB MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.87 0.90 0.88 35308
satisfaction 0.86 0.82 0.84 27034
accuracy 0.86 62342
macro avg 0.86 0.86 0.86 62342
weighted avg 0.86 0.86 0.86 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.87 0.90 0.88 11858
satisfaction 0.86 0.82 0.84 8923
accuracy 0.86 20781
macro avg 0.86 0.86 0.86 20781
weighted avg 0.86 0.86 0.86 20781
Accuracy score for training dataset 0.8636874017516282
Accuracy score for validation dataset 0.8641066358693037
ROC AUC Score: 92.33%

Observations
- The ROC AUC score is 92.33%. But the Recall and F1 scores are low. Thus we can say our model is failing to predict the True Positives
- The Recall and F1 Score of the GaussianNB is more less than Logistic Regresssion.
- This model working better with validation data.
Support Vector Machine, or SVM, is one of the most popular supervised learning algorithms, and it can be used both for classification as well as regression problems. However, in machine learning, it is primarily used for classification problems.
-
In the SVM algorithm, each data item is plotted as a point in n-dimensional space, where n is the number of features we have at hand, and the value of each feature is the value of a particular coordinate.
-
The goal of the SVM algorithm is to create the best line, or decision boundary, that can segregate the n-dimensional space into distinct classes, so that we can easily put any new data point in the correct category, in the future. This best decision boundary is called a hyperplane.
-
The best separation is achieved by the hyperplane that has the largest distance to the nearest training-data point of any class. Indeed, there are many hyperplanes that might classify the data. Aas reasonable choice for the best hyperplane is the one that represents the largest separation, or margin, between the two classes.
The SVM algorithm chooses the extreme points that help in creating the hyperplane. These extreme cases are called support vectors, while the SVM classifier is the frontier, or hyperplane, that best segregates the distinct classes.
The diagram below shows two distinct classes, denoted respectively with blue and green points.
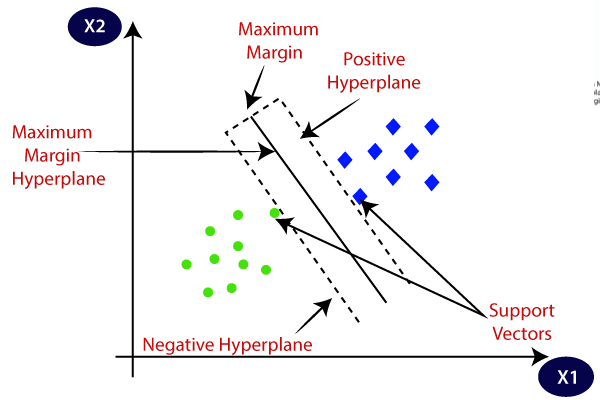
Support Vector Machine can be of two types:
- Linear SVM: A linear SVM is used for linearly separable data, which is the case of a dataset that can be classified into two distinct classes by using a single straight line.
- Non-linear SVM: A non-linear SVM is used for non-linearly separated data, which means that a dataset cannot be classified by using a straight line.
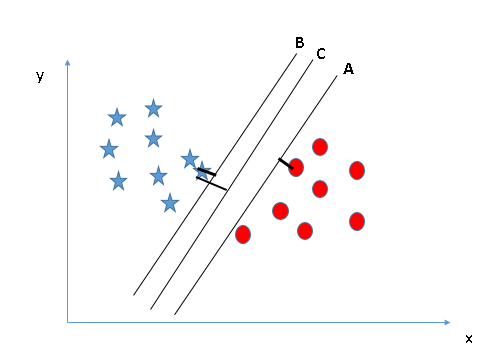
|
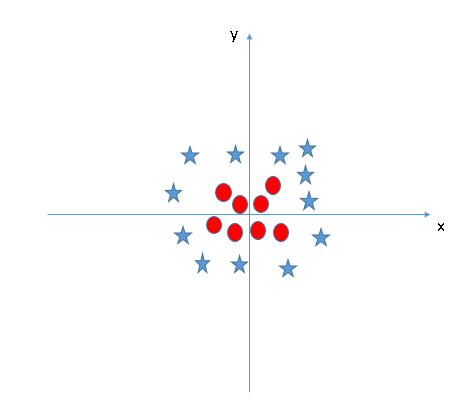
|
| LinearSVM | Non-linear SVM |
We need to choose the best Kernel according to our need.
- The linear kernel is mostly preferred for text classification problems as it performs well for large datasets.
- Gaussian kernels tend to give good results when there is no additional information regarding data that is not available.
- Rbf kernel is also a kind of Gaussian kernel which projects the high dimensional data and then searches a linear separation for it.
- Polynomial kernels give good results for problems where all the training data is normalized.
# import the model
from sklearn.svm import LinearSVC
#fit the model
model =LinearSVC()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val)C:\Users\prajw\anaconda3\Lib\site-packages\sklearn\svm\_classes.py:32: FutureWarning: The default value of `dual` will change from `True` to `'auto'` in 1.5. Set the value of `dual` explicitly to suppress the warning.
warnings.warn(
LINEARSVC MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.88 0.91 0.89 35308
satisfaction 0.87 0.83 0.85 27034
accuracy 0.87 62342
macro avg 0.87 0.87 0.87 62342
weighted avg 0.87 0.87 0.87 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.88 0.90 0.89 11858
satisfaction 0.87 0.84 0.85 8923
accuracy 0.87 20781
macro avg 0.87 0.87 0.87 20781
weighted avg 0.87 0.87 0.87 20781
Accuracy score for training dataset 0.8734721375637612
Accuracy score for validation dataset 0.8743082623550359
ROC AUC Score : 92.59%

Observations
- The ROC AUC score is 92.59%.
- But the Recall and F1 scores are low. Thus we can say our model is failing to predict the True Positives
K-nearest neighbors is a supervised machine learning algorithm for classification and regression. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-nearest neighbors are used for classification or regression.
The main idea behind K-NN is to find the K nearest data points, or neighbors, to a given data point and then predict the label or value of the given data point based on the labels or values of its K nearest neighbors.
K can be any positive integer, but in practice, K is often small, such as 3 or 5. The “K” in K-nearest neighbors refers to the number of items that the algorithm uses to make its prediction whether its a classification problem or a regression problem.
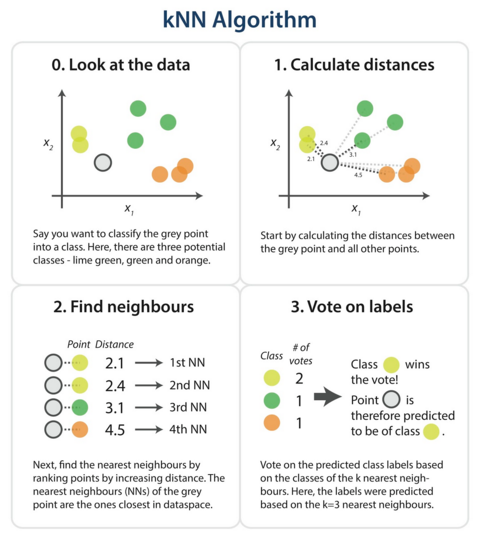
Once K and distance metric are selected, K-NN algorithm goes through the following steps:
- Calculate distance: The K-NN algorithm calculates the distance between a new data point and all training data points. This is done using the selected distance metric.
- Find nearest neighbors: Once distances are calculated, K-nearest neighbors are determined based on a set value of K.
- Predict target class label: After finding out K nearest neighbors, we can then predict the target class label for a new data point by taking majority vote from its K neighbors (in case of classification) or by taking average from its K neighbors (in case of regression).
Below are the different distance functions to calculate the nearest neighbours

# import the model
from sklearn.neighbors import KNeighborsClassifier
#fit the model
model =KNeighborsClassifier()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) KNEIGHBORSCLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.93 0.98 0.95 35308
satisfaction 0.97 0.90 0.94 27034
accuracy 0.95 62342
macro avg 0.95 0.94 0.94 62342
weighted avg 0.95 0.95 0.95 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.91 0.96 0.94 11858
satisfaction 0.95 0.88 0.91 8923
accuracy 0.93 20781
macro avg 0.93 0.92 0.92 20781
weighted avg 0.93 0.93 0.93 20781
Accuracy score for training dataset 0.9460075069776395
Accuracy score for validation dataset 0.9263750541359896
ROC AUC Score: 96.69%

Observations:
- The ROC AUC score is 96.69%.
- The Recall and F1 scores are good.
- But the model is failing to predict the True Positives.
Gradient Descent is a generic optimization algorithm capable of finding optimal solutions to a wide range of problems.
- The general idea is to tweak parameters iteratively in order to minimize the cost function.
- An important parameter of Gradient Descent (GD) is the size of the steps, determined by the learning rate hyperparameters. If the learning rate is too small, then the algorithm will have to go through many iterations to converge, which will take a long time, and if it is too high we may jump the optimal value.
Note: When using Gradient Descent, we should ensure that all features have a similar scale (e.g. using Scikit-Learn’s StandardScaler class), or else it will take much longer to converge.
Types of Gradient Descent: There are three types of Gradient Descent:
- Batch Gradient Descent
- Stochastic Gradient Descent
- Mini-batch Gradient Descent
Stochastic Gradient Descent
-
The word 'stochastic' means a system or process linked with a random probability. Hence, in Stochastic Gradient Descent, a few samples are selected randomly instead of the whole data set for each iteration.
-
If the sample size is very large, it becomes computationally very expensive to find the golbal minima over the entire dataset. With SGD a random sample is selected to perform each iteration. This sample is randomly shuffled and selected for performing the iteration.

In SGDClassifier from scikit learn implements regularized linear models with stochastic gradient descent (SGD) learning. The model it fits can be controlled with the loss parameter; by default, it fits a linear support vector machine (SVM). The various loss function supported is
-
'hinge' gives a linear SVM.
-
'log_loss’ gives logistic regression, a probabilistic classifier.
-
'modified_huber' is another smooth loss that brings tolerance to outliers as well as probability estimates.
-
'squared_hinge' is like a hinge but is quadratically penalized.
-
'perceptron' is the linear loss used by the perceptron algorithm.
# import the model
from sklearn.linear_model import SGDClassifier
#fit the model
model =SGDClassifier(loss='modified_huber',n_jobs=-1,random_state=42)
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) SGDCLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.91 0.80 0.85 35308
satisfaction 0.77 0.89 0.83 27034
accuracy 0.84 62342
macro avg 0.84 0.84 0.84 62342
weighted avg 0.85 0.84 0.84 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.91 0.79 0.85 11858
satisfaction 0.76 0.90 0.83 8923
accuracy 0.84 20781
macro avg 0.84 0.84 0.84 20781
weighted avg 0.85 0.84 0.84 20781
Accuracy score for training dataset 0.837781912675243
Accuracy score for validation dataset 0.8373514267840816
ROC AUC Score : 92.37%

Observations:
- The ROC AUC score is 92.37%. But the Recall and F1 scores are low.
A decision tree is a non-parametric supervised learning algorithm, which is utilized for both classification and regression tasks. A decision tree starts at a single point (or ‘node’) which then branches (or ‘splits’) in two or more directions. Each branch offers different possible outcomes, incorporating a variety of decisions and chance events until a final outcome is achieved.

While there are multiple ways to select the best attribute at each node, two methods, information gain and Gini impurity, act as popular splitting criteria for decision tree models. They help to evaluate the quality of each test condition and how well it will be able to classify samples into a class.
Entropy and Information Gain
- Entropy is a concept that stems from information theory, which measures the impurity of the sample values. It is defined by the following formula, where:

| S - Set of all instances |
| N - Number of distinct class values |
| Pi - Event probablity |
- Information gain indicates how much information a particular variable or feature gives us about the final outcome. It can be found out by subtracting the entropy of a particular attribute inside the data set from the entropy of the whole data set.

| H(S) - entropy of whole data set S |
| |Sj| - number of instances with j value of an attribute A |
| |S| - total number of instances in the dataset |
| v - set of distinct values of an attribute A |
| H(Sj) - entropy of subset of instances for attribute A |
| H(A, S) - entropy of an attribute A |
# import the model
from sklearn.tree import DecisionTreeClassifier
#fit the model
model =DecisionTreeClassifier(random_state=42)
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) DECISIONTREECLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 1.00 1.00 1.00 35308
satisfaction 1.00 1.00 1.00 27034
accuracy 1.00 62342
macro avg 1.00 1.00 1.00 62342
weighted avg 1.00 1.00 1.00 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.96 0.95 0.95 11858
satisfaction 0.94 0.94 0.94 8923
accuracy 0.95 20781
macro avg 0.95 0.95 0.95 20781
weighted avg 0.95 0.95 0.95 20781
Accuracy score for the training dataset is 1.0
Accuracy score for validation dataset 0.9486069005341418
ROC AUC Score: 94.79%

Observations:
- The ROC AUC score is 94.79%.
- The Recall and F1 scores are good.
- But the model will cause overfitting. as the accuracy score for the training dataset is 1.
Random Forest Classifier is an Ensemble algorithm. Random forest classifier creates a set of decision trees from randomly selected subset of the training set. It then aggregates the votes from different decision trees to decide the final class of the test object.
This works well because a single decision tree may be prone to noise, but the aggregate of many decision trees reduces the effect of noise giving more accurate results.

Random forest algorithms have three main hyperparameters, which need to be set before training. These include node size, the number of trees, and the number of features sampled. From there, the random forest classifier can be used to solve for regression or classification problems.
- The random forest algorithm is made up of a collection of decision trees, and each tree in the ensemble is comprised of a data sample drawn from a training set with replacement, called the bootstrap sample.
- Of that training sample, one-third of it is set aside as test data, known as the out-of-bag (oob) sample.
- Another instance of randomness is then injected through feature bagging, adding more diversity to the dataset and reducing the correlation among decision trees.
- Depending on the type of problem, the determination of the prediction will vary. For a regression task, the individual decision trees will be averaged, and for a classification task, a majority vote—i.e. the most frequent categorical variable—will yield the predicted class.
- Finally, the oob sample is then used for cross-validation, finalizing that prediction.
#import the model
from sklearn.ensemble import RandomForestClassifier
#fit the model
model =RandomForestClassifier(random_state=42)
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) RANDOMFORESTCLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 1.00 1.00 1.00 35308
satisfaction 1.00 1.00 1.00 27034
accuracy 1.00 62342
macro avg 1.00 1.00 1.00 62342
weighted avg 1.00 1.00 1.00 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.96 0.98 0.97 11858
satisfaction 0.97 0.94 0.95 8923
accuracy 0.96 20781
macro avg 0.96 0.96 0.96 20781
weighted avg 0.96 0.96 0.96 20781
Accuracy score for training dataset 1.0
Accuracy score for validation dataset 0.9609739666041095
ROC AUC Score: 99.34%

Observations:
- The ROC AUC score is 99.37%.
- The Recall and F1 scores are good.
- But model can cause overfitting, as the accuracy score for training dataset is 1,
- But after hypertunning we can train this model model is working much better with the validation dataset set as compared to other trained model.
AdaBoost is an ensemble learning method (also known as “meta-learning”) which was initially created to increase the efficiency of binary classifiers. AdaBoost uses an iterative approach to learn from the mistakes of weak classifiers, and turn them into strong ones.
Rather than being a model in itself, AdaBoost can be applied on top of any classifier to learn from its shortcomings and propose a more accurate model. It is usually called the “best out-of-the-box classifier” for this reason.
Stumps have one node and two leaves. AdaBoost uses a forest of such stumps rather than trees.
Adaboost works in the following steps:
-
Initially, Adaboost selects a training subset randomly. It iteratively trains the AdaBoost machine learning model by selecting the training set based on the accurate prediction of the last training. It assigns the higher weight to wrong classified observations so that in the next iteration these observations will get the high probability for classification.
-
Also, It assigns the weight to the trained classifier in each iteration according to the accuracy of the classifier. The more accurate classifier will get high weight.
-
This process iterate until the complete training data fits without any error or until reached to the specified maximum number of estimators. To classify, perform a "vote" across all of the learning algorithms you built.
Pros of Aaboost
AdaBoost is easy to implement. It iteratively corrects the mistakes of the weak classifier and improves accuracy by combining weak learners. You can use many base classifiers with AdaBoost. AdaBoost is not prone to overfitting. This can be found out via experiment results, but there is no concrete reason available.
Cons of Aaboost AdaBoost is sensitive to noise data. It is highly affected by outliers because it tries to fit each point perfectly. AdaBoost is slower compared to XGBoost.
#import the model
from sklearn.ensemble import AdaBoostClassifier
#fit the model
model =AdaBoostClassifier()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val)
ADABOOSTCLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.93 0.94 0.94 35308
satisfaction 0.92 0.91 0.92 27034
accuracy 0.93 62342
macro avg 0.93 0.93 0.93 62342
weighted avg 0.93 0.93 0.93 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.94 0.94 0.94 11858
satisfaction 0.92 0.92 0.92 8923
accuracy 0.93 20781
macro avg 0.93 0.93 0.93 20781
weighted avg 0.93 0.93 0.93 20781
Accuracy score for training dataset 0.9275929549902152
Accuracy score for validation dataset 0.9282517684423272
ROC AUC Score : 97.74%

Observations:
- The ROC AUC score is 97.74%.
- The Recall and F1 scores are good but comparatively lower than the random forest.
Gradient boosting classifiers are a group of machine learning algorithms that combine many weak learning models together to create a strong predictive model. Decision trees are usually used when doing gradient boosting. Gradient boosting models are becoming popular because of their effectiveness at classifying complex datasets.
The gradient boosting algorithm is one of the most powerful algorithms in the field of machine learning. As we know that the errors in machine learning algorithms are broadly classified into two categories i.e. Bias Error and Variance Error. As gradient boosting is one of the boosting algorithms it is used to minimize bias error of the model.
Gradient Boosting has three main components:
1.Loss Function - The role of the loss function is to estimate how good the model is at making predictions with the given data. This could vary depending on the problem at hand. For example, if we're trying to predict the weight of a person depending on some input variables (a regression problem), then the loss function would be something that helps us find the difference between the predicted weights and the observed weights. On the other hand, if we're trying to categorize if a person will like a certain movie based on their personality, we'll require a loss function that helps us understand how accurate our model is at classifying people who did or didn't like certain movies.
2.Weak Learner - A weak learner is one that classifies our data but does so poorly, perhaps no better than random guessing. In other words, it has a high error rate. These are typically decision trees (also called decision stumps, because they are less complicated than typical decision trees).
3.Additive Model - This is the iterative and sequential approach of adding the trees (weak learners) one step at a time. After each iteration, we need to be closer to our final model. In other words, each iteration should reduce the value of our loss function.
#import the model
from sklearn.ensemble import GradientBoostingClassifier
#fit the model
model =GradientBoostingClassifier()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) GRADIENTBOOSTINGCLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.94 0.96 0.95 35308
satisfaction 0.95 0.92 0.93 27034
accuracy 0.94 62342
macro avg 0.94 0.94 0.94 62342
weighted avg 0.94 0.94 0.94 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.94 0.96 0.95 11858
satisfaction 0.94 0.92 0.93 8923
accuracy 0.94 20781
macro avg 0.94 0.94 0.94 20781
weighted avg 0.94 0.94 0.94 20781
Accuracy score for traing dataset 0.942735234673254
Accuracy score for validation dataset 0.9418218565035369
ROC AUC Score : 98.71%

Observations:
- The ROC AUC score is 98.71%.
- The Recall and F1 scores are good.
- We can choose this dataset to train our model.
XgBoost stands for Extreme Gradient Boosting. It implements machine learning algorithms under the Gradient Boosting framework.
- In this algorithm, decision trees are created in sequential form. Weights play an important role in XGBoost.
- Weights are assigned to all the independent variables which are then fed into the decision tree which predicts results.
- The weight of variables predicted wrong by the tree is increased and these variables are then fed to the second decision tree. These individual classifiers/predictors then ensemble to give a strong and more precise model.
- It can work on regression, classification, ranking, and user-defined prediction problems.
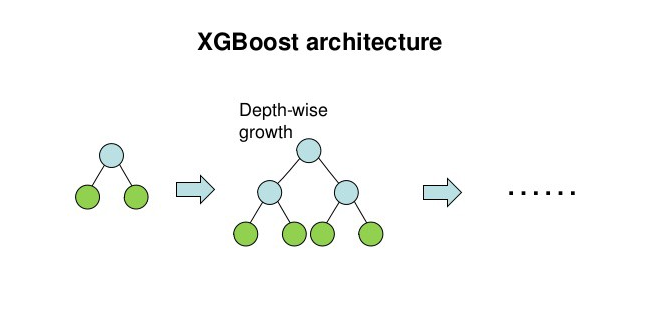
#import the model
from xgboost import XGBClassifier
#fit the model
model =XGBClassifier()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for training dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val) XGBCLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.98 0.99 0.98 35308
satisfaction 0.99 0.97 0.98 27034
accuracy 0.98 62342
macro avg 0.98 0.98 0.98 62342
weighted avg 0.98 0.98 0.98 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.96 0.98 0.97 11858
satisfaction 0.97 0.94 0.96 8923
accuracy 0.96 20781
macro avg 0.96 0.96 0.96 20781
weighted avg 0.96 0.96 0.96 20781
Accuracy score for training dataset 0.9802861634211286
Accuracy score for validation dataset 0.9622732303546508
ROC AUC Score: 99.51%

Observations:
- The ROC AUC score is 99.51%.slightly higher than gradient Boosting.
- The Recall and F1 scores are good.
- We can choose this dataset to train our model. Ans can also improve our model with Hyperparameter tuning.
LightGBM is a gradient boosting framework that uses tree-based learning algorithms. It is designed to be distributed and efficient with the following advantages:
- Faster training speed and higher efficiency.
- Lower memory usage.
- Better accuracy.
- Support of parallel, distributed, and GPU learning.
- Capable of handling large-scale data.
LightGBM uses histogram-based algorithms, which bucket continuous feature (attribute) values into discrete bins. This speeds up training and reduces memory usage.
LightGBM grows trees leaf-wise (best-first). It will choose the leaf with max delta loss to grow. Holding #leaf fixed, leaf-wise algorithms tend to achieve lower loss than level-wise algorithms.
Leaf-wise may cause over-fitting when #data is small, so LightGBM includes the max_depth parameter to limit tree depth. However, trees still grow leaf-wise even when max_depth is specified.
#import the model
import lightgbm as lgb
#fit the model
model =lgb.LGBMClassifier()
model.fit(X_train,y_train)
# prediction
pred_train = model.predict(X_train)
pred_val = model.predict(X_val)
# model name
model_name = str(type(model)).split(".")[-1][0:-2]
print(f"\t\t{model_name.upper()} MODEL\n")
print('Training part:')
print(classification_report(y_train, pred_train,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print('validation part:')
print(classification_report(y_val, pred_val,
target_names=['neutral or dissatisfaction', 'satisfaction']))
print("Accuracy score for traing dataset",accuracy_score(y_train, pred_train))
print("Accuracy score for validation dataset",accuracy_score(y_val, pred_val))
make_classification_report(model,X_val,y_val)[LightGBM] [Info] Number of positive: 27034, number of negative: 35308
[LightGBM] [Warning] Auto-choosing row-wise multi-threading, the overhead of testing was 0.002503 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 929
[LightGBM] [Info] Number of data points in the train set: 62342, number of used features: 22
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.433640 -> initscore=-0.267014
[LightGBM] [Info] Start training from score -0.267014
LGBMCLASSIFIER MODEL
Training part:
precision recall f1-score support
neutral or dissatisfaction 0.96 0.98 0.97 35308
satisfaction 0.98 0.94 0.96 27034
accuracy 0.97 62342
macro avg 0.97 0.96 0.97 62342
weighted avg 0.97 0.97 0.97 62342
validation part:
precision recall f1-score support
neutral or dissatisfaction 0.96 0.98 0.97 11858
satisfaction 0.97 0.94 0.96 8923
accuracy 0.96 20781
macro avg 0.96 0.96 0.96 20781
weighted avg 0.96 0.96 0.96 20781
Accuracy score for training dataset 0.9671970742035867
Accuracy score for validation dataset 0.9630431644290458
ROC AUC Score: 99.49%

Observations:
- this model is performing best with our Dataset.
- The ROC AUC score is 99.49%.
- The Recall and F1 scores are Very good.
- We can choose this dataset to train our model.