Important
This Markdown file is optimized for use with the GitHub. However, certain content such as equations or citations may not display or function correctly on other platforms.
 Source: UCI Machine Learning
Source: UCI Machine Learning
Domain yang dipilih dalam proyek ini adalah Ekonomi dan Bisnis, dengan judul proyek Predictive Analytics: Red Wine Quality Classification.
Red wine merupakan minuman beralkohol yang terbuat dari anggur merah. Wine sudah sangat populer untuk dikonsumsi secara global dan konsumsi wine dalam jumlah tertentu juga memberikan manfaat kesehatan 1^. Saat ini, beredar berbagaim macam jenis red wine dengan kandungan yang berbeda-beda. Untuk dapat mengkategorikan kualitas red wine dalam jumlah yang banyak secara cepat dan efisien, diperlukan sebuah pendekatan berbasis machine learning.
Salah satu keunggulan utama dari pendekatan machine learning adalah kemampuannya untuk memproses dan menganalisis volume data yang besar dan beragam dengan kecepatan yang tinggi. Dengan memanfaatkan machine learning, diharapkan akan mampu mengidentifikasi pola yang rumit dan hubungan antar fitur dari bahan-bahan red wine yang mungkin tidak terlihat oleh metode analisis secara manual atau tradisional. Sehingga diharapkan dengan menggunakan machine learning, akan mampu meningkatkan nilai tambah dalam penjualan wine karena perusahaan dapat dengan mudah mengenali kualitas wine dengan cepat dan akurat.
Beberapa penelitian terdahulu telah melakukan klasifikasi wine menggunakan machine learning, salah satunya menggunakan metode SVM, Naive Bayes, dan Random Forest 2^. Penelitian lainnya juga menggunakan metode Random Forest 3^. Pada proyek ini akan dilakukan klasifikasi kualitas red wine menggunakan perbandingan metode KNN, SVM, dan Random Forest.
Kualitas wine menjadi salah satu hal yang paling utama dari wine. Perusahaan atau pembuat wine tentu ingin meningkatkan dan menjual produksi red wine berkualitas dan pembeli juga ingin mendapatkan wine yang berkualitas. Dengan menentukan kualitas dari wine secara cepat dan tepat, tentu perusahaan dapat menjual wine dengan kualitas baik dengan lebih cepat sehingga dapat meningkatkan pemasaran dan penjualan, sementara itu pembeli juga dapat memperoleh wine dengan kualitas yang sudah tentu baik dari penjual. Ini akan menjadi potensi untuk meningkatkan keuntungan bagi perusahaan maupun pembuat wine.
Berdasarkan latar belakang di atas, adapun rumusan masalah dalam proyek ini adalah:
- Bagaimana tahapan pemrosesan data dalam mengambangkan model machine learning untuk melakukan klasifikasi terhadap kualitas red wine?
- Bagaimana mengembangkan model machine learning dengan metode KNN, SVM, dan Random Forest dalam melakukan klasifikasi terhadap kualitas red wine?
- Model apakah yang menghasilkan performa terbaik (dengan metrics accuracy, precision, recall, dan F1) dalam melakukan klasifikasi terhadap kualitas red wine?
Menjelaskan tujuan dari pernyataan masalah:
- Untuk mengetahui tahapan pemrosesan data dalam mengambangkan model machine learning untuk melakukan klasifikasi terhadap kualitas red wine
- Untuk mengetahui cara mengembangkan model machine learning dengan metode KNN, SVM, dan Random Forest dalam melakukan klasifikasi terhadap kualitas red wine
- Untuk mengetahui model yang memiliki performa terbaik (dengan metrics accuracy, precision, recall, dan F1) dalam melakukan klasifikasi terhadap kualitas red wine
Dataset yang digunakan dalam proyek ini adalah Red Wine Quality yang disediakan oleh UCI Machine Learning pada platform Kaggle.
Dataset tersebut terdiri atas 1599 data dengan 12 fitur (termasuk 1 fitur target). Adapun penjelasan dari fitur-fitur tersebut adalah:
-
Fixed Acidity: Konsentrasi asam tartarat dalam anggur, diukur dalam gram per liter.
-
Volatile Acidity: Konsentrasi asam asetat dalam anggur, diukur dalam gram per liter.
-
Citric Acid: Konsentrasi asam sitrat dalam anggur, diukur dalam gram per liter.
-
Residual Sugar: Jumlah gula yang tersisa setelah fermentasi selesai, diukur dalam gram per liter.
-
Chlorides: Konsentrasi garam dalam anggur, diukur dalam gram per liter.
-
Free Sulfur Dioxide: Jumlah SO2 bebas yang hadir dalam anggur, diukur dalam miligram per liter.
-
Total Sulfur Dioxide: Jumlah total SO2 dalam anggur, termasuk bentuk bebas dan terikat, diukur dalam miligram per liter.
-
Density: Massa per volume dari anggur, diukur dalam gram per mililiter.
-
pH: Ukuran tingkat keasaman atau kebasaan dalam anggur. Skala pH berkisar dari 0 (sangat asam) hingga 14 (sangat basa), dengan 7 menunjukkan keadaan netral.
-
Sulphates: Konsentrasi garam sulfat dalam anggur, diukur dalam gram per liter.
-
Alcohol: Persentase volume alkohol dalam anggur.
Target fitur:
- Quality: kualitas red wine dalam rentang 0 sampai 10.
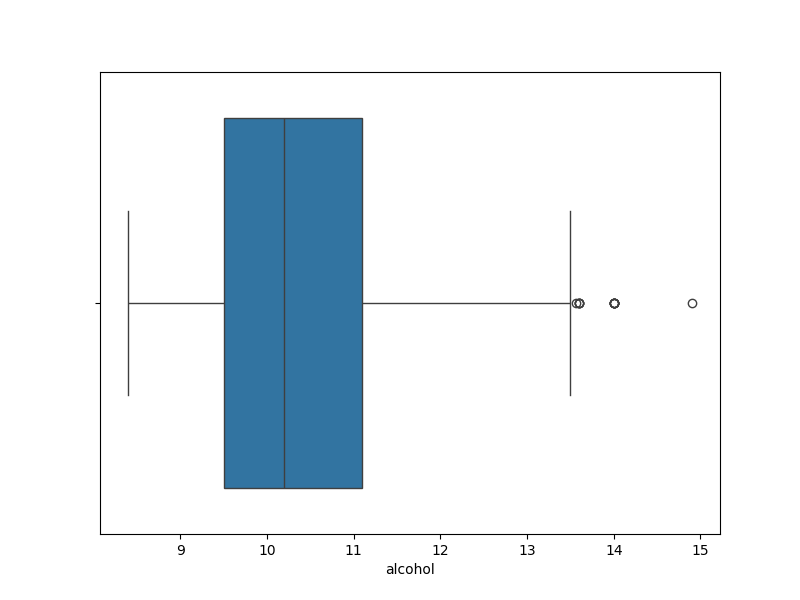 Gambar 1. Visualisasi Fitur Alcohol dengan Boxplot
Gambar 1. Visualisasi Fitur Alcohol dengan Boxplot
Berdasarkan Gambar 1. dapat diketahui bahwa pada fitur alcohol terdapat beberapa outlier karena terdapat data points yang nilainya lebih besar dari nilai Q3.
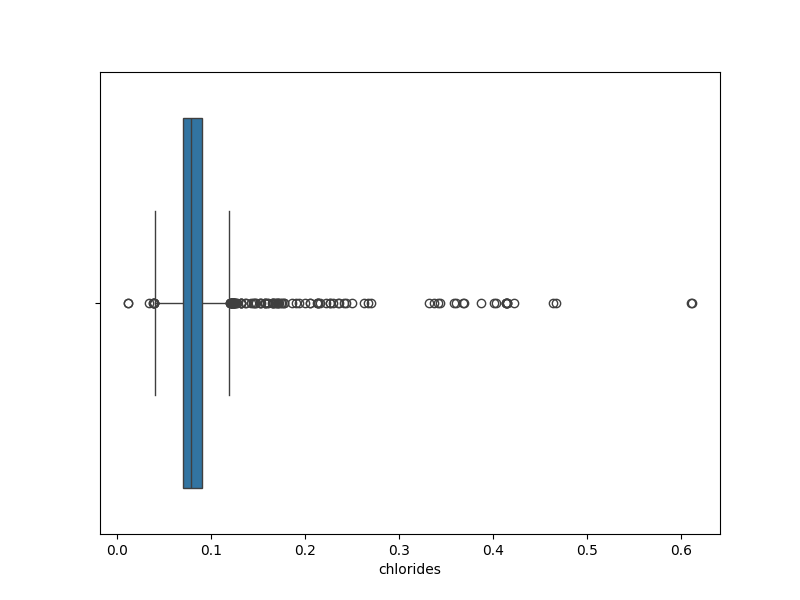 Gambar 2. Visualisasi Fitur Chlorides dengan Boxplot
Gambar 2. Visualisasi Fitur Chlorides dengan Boxplot
Berdasarkan Gambar 2. dapat diketahui bahwa pada fitur chlorides terdapat beberapa outlier karena terdapat data points yang nilainya lebih besar dari nilai Q3 dan ada data points yang nilainya kurang dari nilai Q1.
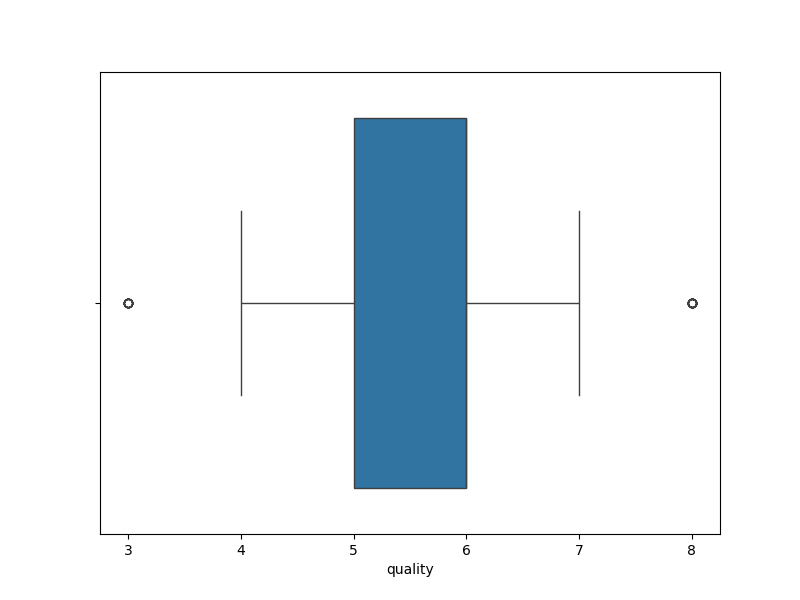 Gambar 3. Visualisasi Fitur Quality dengan Boxplot
Gambar 3. Visualisasi Fitur Quality dengan Boxplot
Berdasarkan Gambar 3. dapat diketahui bahwa pada fitur quality terdapat beberapa outlier karena terdapat data points yang nilainya lebih besar dari nilai Q3 dan ada data points yang nilainya kurang dari nilai Q1.
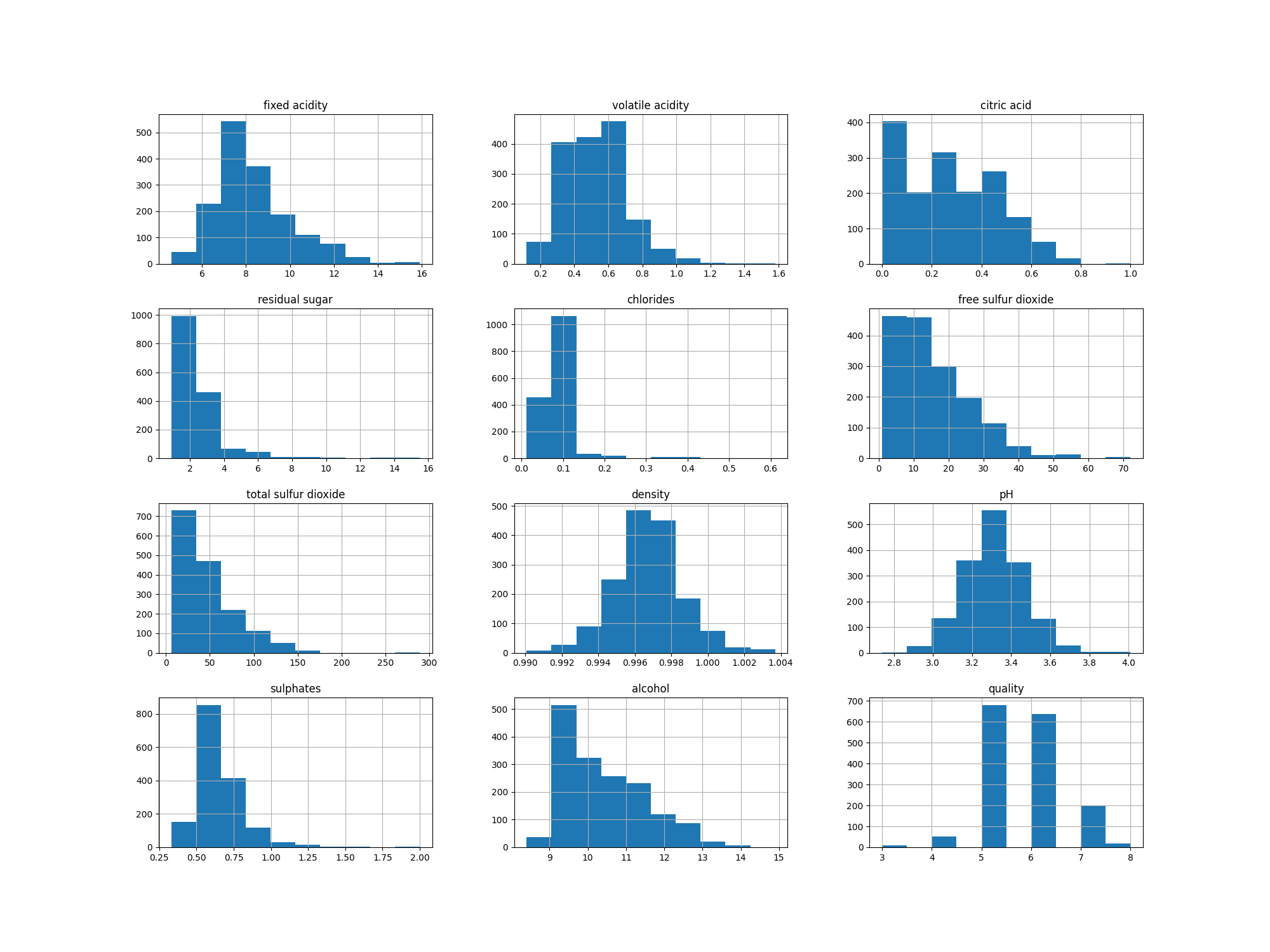 Gambar 4. Univariate Analysis pada Seluruh Fitur
Gambar 4. Univariate Analysis pada Seluruh Fitur
Berdasarkan Gambar 4. dapat diketahui bahwa kualitas berada pada rentang 3 sampai 8, kemudian untuk pH juga berada pada rentang dibawah 4 sementara kadar alkohol berada dibawah 15%.
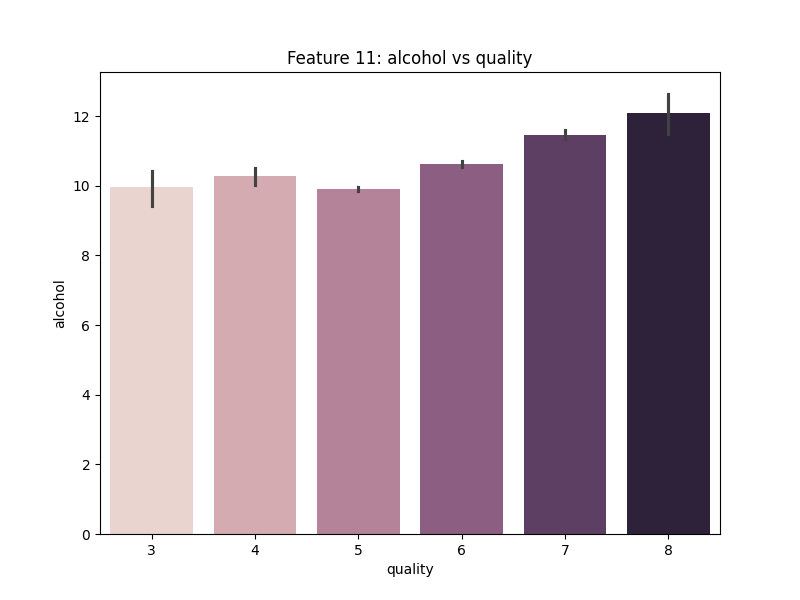 Gambar 5. Multivariate Analysis antara Fitur Alcohol dengan Quality
Gambar 5. Multivariate Analysis antara Fitur Alcohol dengan Quality
Berdasarkan Gambar 5. dapat diketahui bahwa semakin tinggi kualitas wine maka fitur alcohol cenderung semakin tinggi pula.
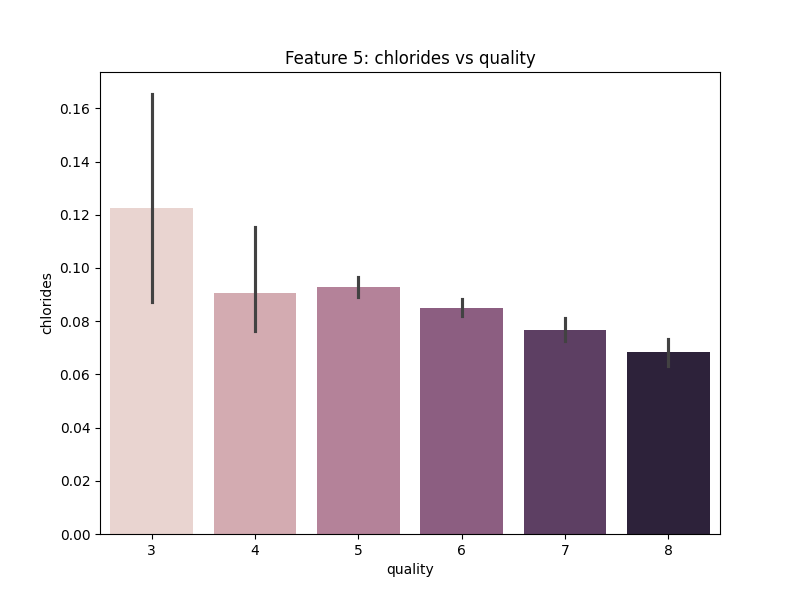 Gambar 6. Multivariate Analysis antara Fitur Chlorides dengan Quality
Gambar 6. Multivariate Analysis antara Fitur Chlorides dengan Quality
Berdasarkan Gambar 6. dapat diketahui bahwa semakin tinggi kualitas wine maka fitur chlorides cenderung semakin rendah.
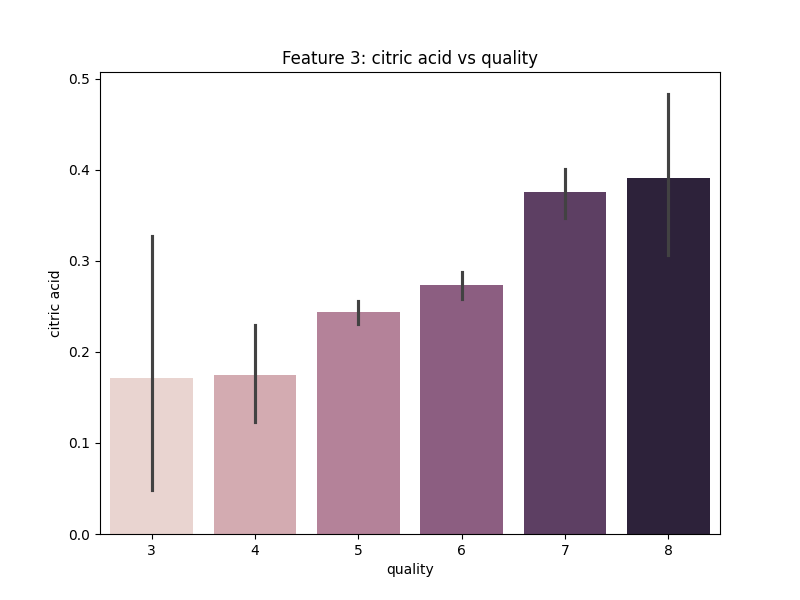 Gambar 7. Multivariate Analysis antara Fitur Citric Acid dengan Quality
Gambar 7. Multivariate Analysis antara Fitur Citric Acid dengan Quality
Berdasarkan Gambar 7. dapat diketahui bahwa semakin tinggi kualitas wine maka fitur Citric Acid cenderung ikut semakin tinggi pula.
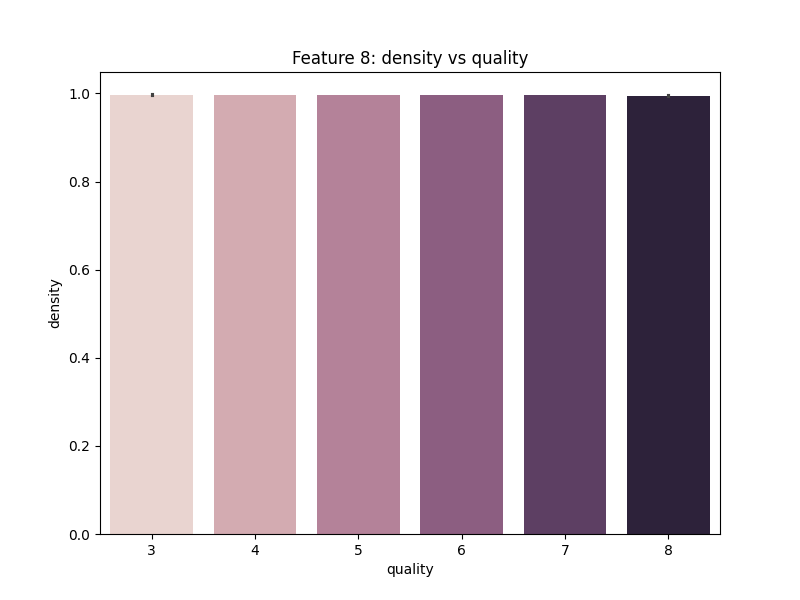 Gambar 8. Multivariate Analysis antara Fitur Density dengan Quality
Gambar 8. Multivariate Analysis antara Fitur Density dengan Quality
Berdasarkan Gambar 8. dapat diketahui bahwa fitur density tidak memberikan pengaruh yang signifikan terhadap kualitas wine.
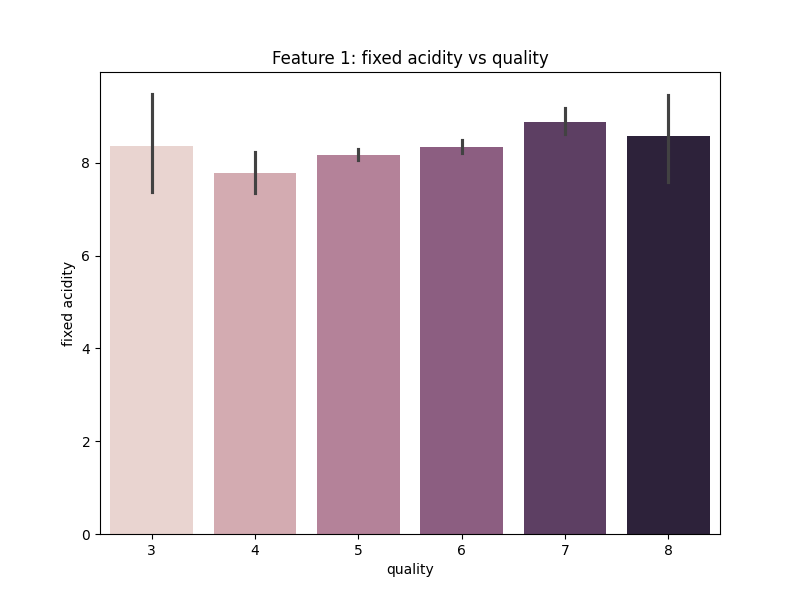 Gambar 9. Multivariate Analysis antara Fitur Fixed Acidity dengan Quality
Gambar 9. Multivariate Analysis antara Fitur Fixed Acidity dengan Quality
Berdasarkan Gambar 9. dapat diketahui bahwa fitur Fixed Acidity tidak memberikan pengaruh yang signifikan terhadap kualitas wine.
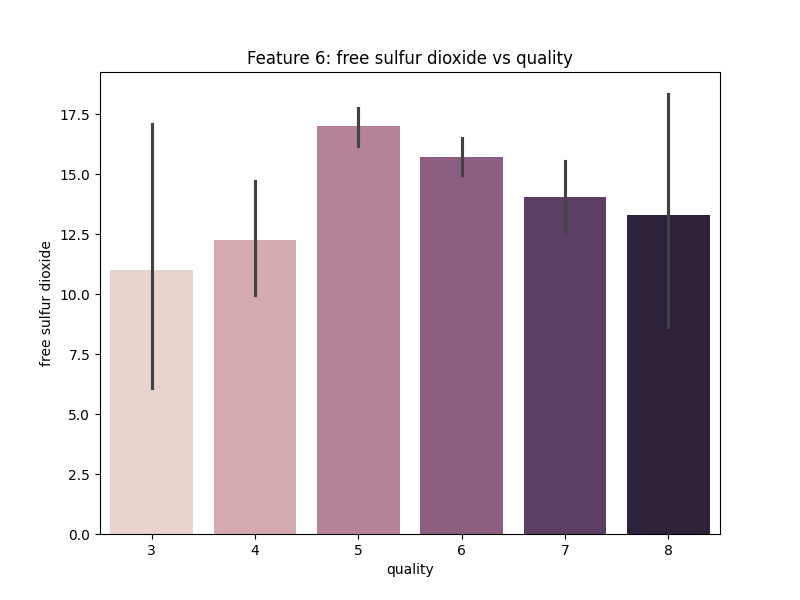 Gambar 10. Multivariate Analysis antara Fitur Free Sulfur Dioxide dengan Quality
Gambar 10. Multivariate Analysis antara Fitur Free Sulfur Dioxide dengan Quality
Berdasarkan Gambar 10. dapat diketahui bahwa fitur Free Sulfur Dioxide tidak memberikan pengaruh yang signifikan terhadap kualitas wine. Akan tetapi wine dengan kualitas sedang cenderung memiliki free sulfur dioxide yang tinggi.
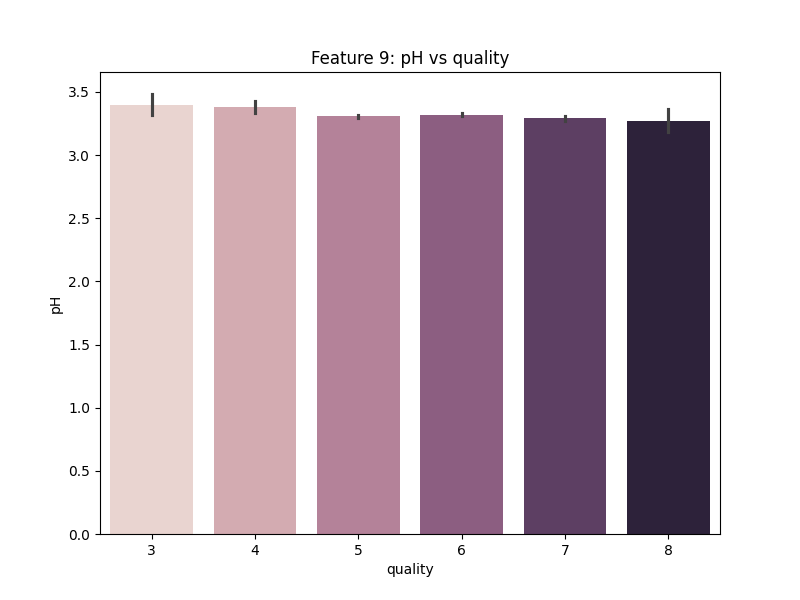 Gambar 11. Multivariate Analysis antara Fitur pH dengan Quality
Gambar 11. Multivariate Analysis antara Fitur pH dengan Quality
Berdasarkan Gambar 11. dapat diketahui bahwa fitur pH tidak memberikan pengaruh yang signifikan terhadap kualitas wine.
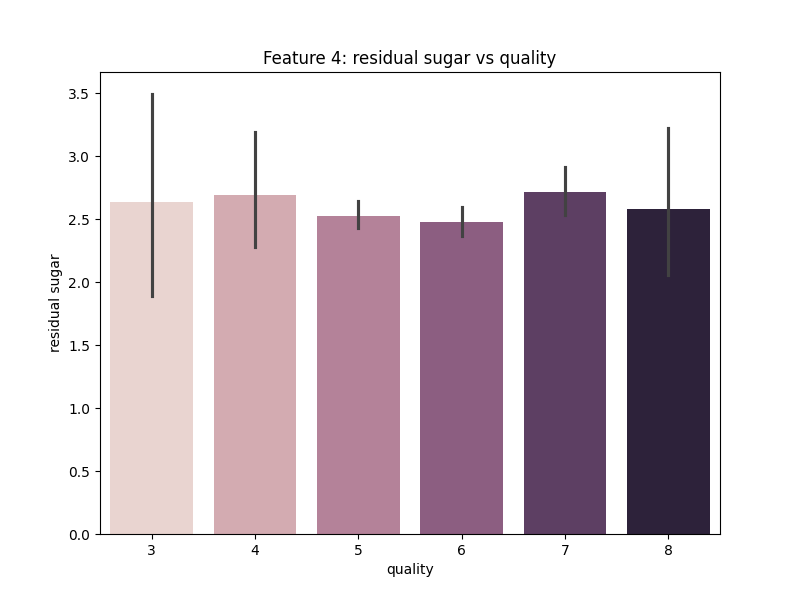 Gambar 12. Multivariate Analysis antara Fitur Residual Sugar dengan Quality
Gambar 12. Multivariate Analysis antara Fitur Residual Sugar dengan Quality
Berdasarkan Gambar 12. dapat diketahui bahwa fitur Residual Sugar tidak memberikan pengaruh yang signifikan terhadap kualitas wine.
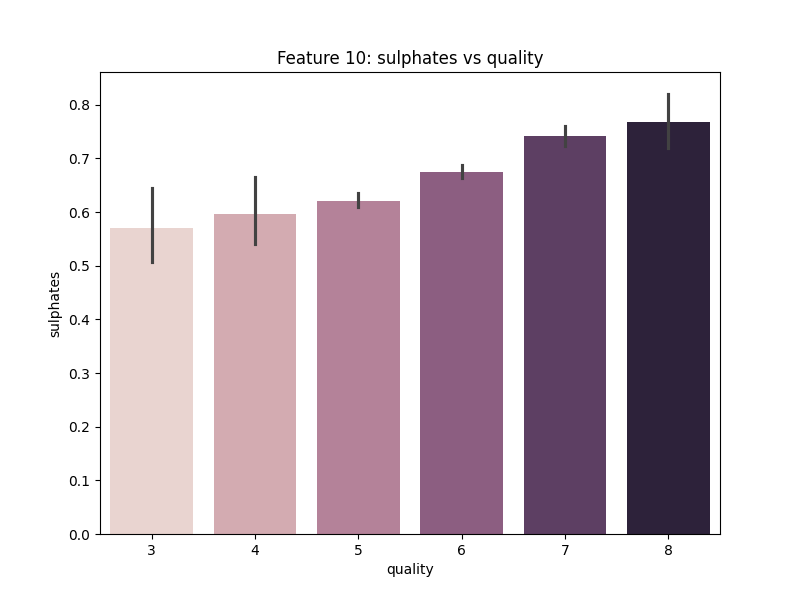 Gambar 13. Multivariate Analysis antara Fitur Sulphates dengan Quality
Gambar 13. Multivariate Analysis antara Fitur Sulphates dengan Quality
Berdasarkan Gambar 13. dapat diketahui bahwa fitur Sulphates yang lebih tinggi cenderung menyebabkan kualitas wine juga ikut menjadi lebih tinggi.
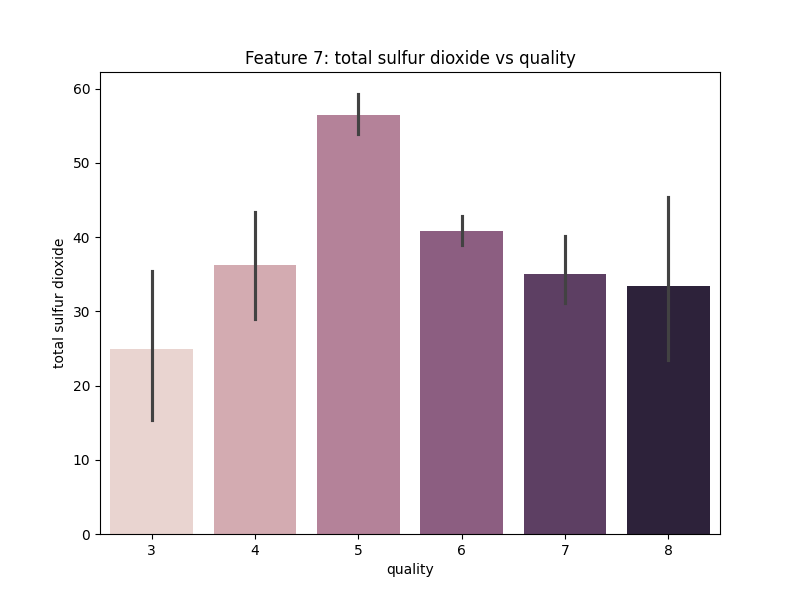 Gambar 14. Multivariate Analysis antara Fitur Total Sulfur Dioxide dengan Quality
Gambar 14. Multivariate Analysis antara Fitur Total Sulfur Dioxide dengan Quality
Berdasarkan Gambar 14. dapat diketahui bahwa fitur Total Sulfur Dioxide tidak berpengaruh secara signifikan terhadap kualitas wine, tetapi wine dengan kualitas menengah (5-6) cenderung memiliki total sulfur dioxide dengan kandungan yang tinggi.
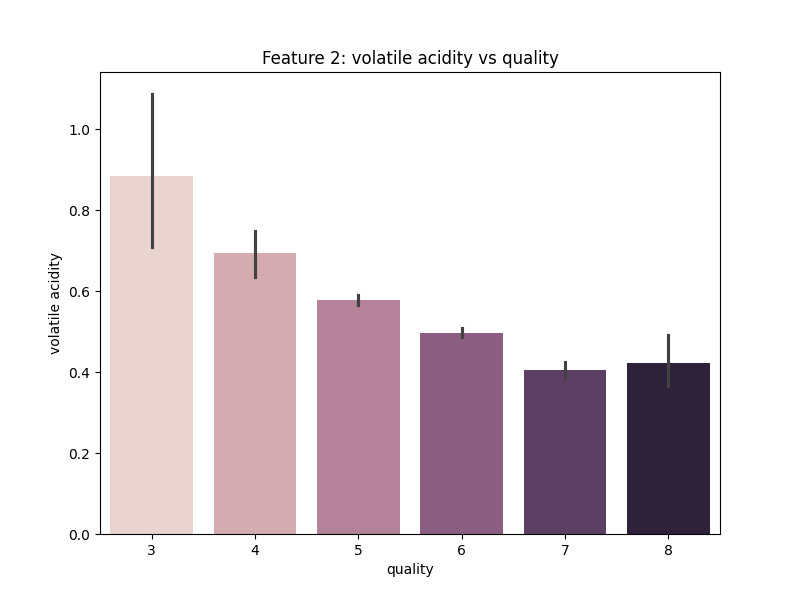 Gambar 14. Multivariate Analysis antara Fitur Volatile Acidity dengan Quality
Gambar 14. Multivariate Analysis antara Fitur Volatile Acidity dengan Quality
Berdasarkan Gambar 14. dapat diketahui bahwa kualitas wine cenderung semakin baik jika memiliki volatile acidity yang semakin rendah.
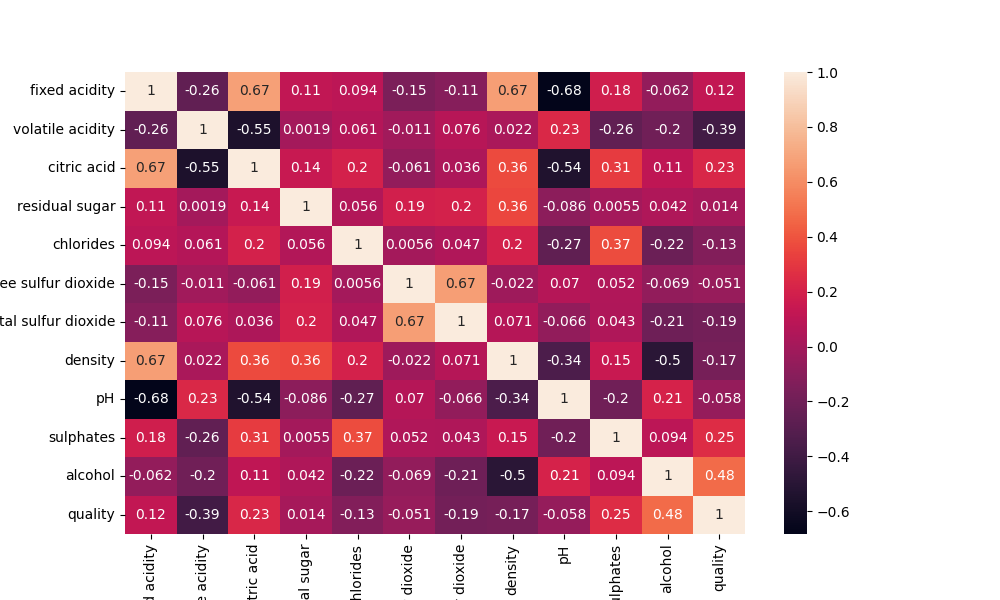 Gambar 15. Heatmap Seluruh Fitur
Gambar 15. Heatmap Seluruh Fitur
Berdasarkan Gambar 15. dapat diketahui bahwa fitur-fitur yang memiliki pengaruh atau korelasi yang signifikan terhadap kualitas wine adalah alcohol, sulphates, citric acid, dan volatile acidity.
Adapun proses data preparation yang telah dilakukan yaitu:
- Menghilangkan nilai yang duplikat pada dataset. Tahapan ini diperlukan untuk mengurangi bias dan mencegah overfitting dari model.
- Menghilangkan outlier pada fitur-fitur penting seperti
alcohol,sulphates,citric acid, danvolatile acidity. Outlier dihilangkan pada fitur dengan nilai absolute korelasi diatas 0.2. - Melakukan konversi fitur target dari rentang 0-10 menjadi data kategorikal yaitu
bad,medium, dangood, dan kemudian di encode kembali. Tahapan ini dilakukan karena tujuan dari proyek ini adalah melakukan klasifikasi multi-kelas dengan 3 kelas dan agar lebih mudah dalam menggeneralisasi kualitas red wine. - Melakukan split untuk data testing (20%) dan data training (80%). Tahapan ini diperlukan untuk menyediakan data latih kepada model dan proporsi data testing sekitar 20% karena total data berjumlah 1268 sehingga diperlukan data testing dengan persentase yang cukup.
- Melakukan normalisasi dan transformasi data training dengan Standard Scaler. Transformasi ini bertujuan agar setiap fitur memiliki skala yang sama dan juga penting bagi beberapa model ML seperti KNN dan SVM.
Dalam tahap modeling, terdapat 3 metode model ML yang digunakan, yaitu K-Nearest Neighbors (KNN), Support Vector Machine (SVM), dan Random Forest. Adapun parameter yang digunakan adalah hyperparameter bawaan dari scikit-learn.
Adapun kelebihan dan kekurangan dari setiap algoritma atau metode tersebut adalah:
- KNN
- Kelebihan: Memiliki implementasi yang sederhana dan mudah dimengerti, selain itu juga cukup robust terhadap noise dan outlier pada data.
- Kekurangan: Memiliki waktu komputasi yang cukup lama dan lemah terhadap data dengan dimensi tinggi, selain itu juga sensitif terhadap fitur yang kurang relevan karena hanya bergantung pada jarak.
- Parameter yang digunakan adalah:
- n_neighbors: jumlah neighbors atau ketetanggaan yang digunakan.
- SVM
- Kelebihan: Memiliki efisiensi yang baik terhadap data dengan dimensi tinggi. Memiliki kernel yang dapat digunakan untuk berbagai keperluan data dan cukup robust terhadap overfitting pada data dengan dimensi tinggi.
- Kekurangan: Memiliki waktu komputasi dan penggunaan memori yang besar pada dataset yang sangat besar, selain itu tuning hyperparameter untuk C (regularization parameter) cukup memakan waktu.
- Parameter yang digunakan adalah:
- C: regularization parameter
- kernel: tipe kernel yang digunakan pada algoritma, bisa berupa linear, poly, rbf, maupun sigmoid.
- gamma: kernel koefisien untuk tipe kernel rbf, poly, dan sigmoid.
- Random Forest
- Kelebihan: Cukup robust karena pada dasarnya terdiri dari kombinasi decision tree, selain itu juga mampu menangani fitur dengan missing value dan dapat digunakan baik untuk klasifikasi maupun regresi.
- Kekurangan: Membutuhkan lebih banyak memori untuk komputasi dibandingkan decision tree, selain itu juga sulit untuk menangani dataset dengan kelas yang tidak seimbang.
- Parameter yang digunakan adalah:
- n_estimator: jumlah decision tree yang ada pada forest.
Berdasarkan ketiga model tersebut, model yang paling baik untuk dipilih adalah SVM, mengingat SVM bersifat robust atau handal, dan cukup cepat terhadap data yang tidak terlalu banyak, serta tetap mampu mempertahankan performa dalam data pada dimensi tinggi.
Dalam tahap evaluasi, metrik yang digunakan adalah accuracy, precision, recall, dan F1-score.
Adapun cara untuk menghitung atau mendapatkan setiap metriks tersebut adalah sebagai berikut:
- Accuracy didapatkan dengan menghitung persentase dari jumlah prediksi yang benar dibagi dengan jumlah seluruh prediksi. Formula:
Memiliki kelebihan yaitu mudah dimengerti dan cocok untuk klasifikasi biner, tetapi tidak efektif untuk klasifikasi kengan kelas yang timpang atau imbalance.
- Precision didapatkan dengan menghitung persentase dari jumlah prediksi benar positif dari keseluruhan hasil yang diprediksi positif. Formula:
Memiliki kelebihan yaitu memberikan informasi seberapa baik model memprediksi positif benar dan berguna untuk menghindari FP yang tinggi. Kelemahan adalah tidak mempertimbangkan FN.
- Recall didapatkan dengan menghitung persentase dari jumlah prediksi benar positif dibandingkan dengan keseluruhan data yang benar positif. Formula:
Memiliki kelebihan yaitu memberikan informasi seberapa baik model memprediksi positif benar dengan semua data yang sebenarnya positif. Memiliki kelemahan karena tidak mempertimbangkan FP.
- F1-Score didapatkan dengan menghitung perbandingan antara rata-rata precision dan recall yang dibobotkan. Formula:
Memiliki kelebihan karena menggabungkan metriks precision dan recall sehingga mendapatkan keseimbangan dari kedua metriks tersebut. Memiliki kelemahan tidak memberikan informasi terhadap kinerja model pada setiap kelas atau kategori secara terpisah.
Berdasarkan hasil pengujian terhadap data testing, didapatkan hasil sebagai berikut:
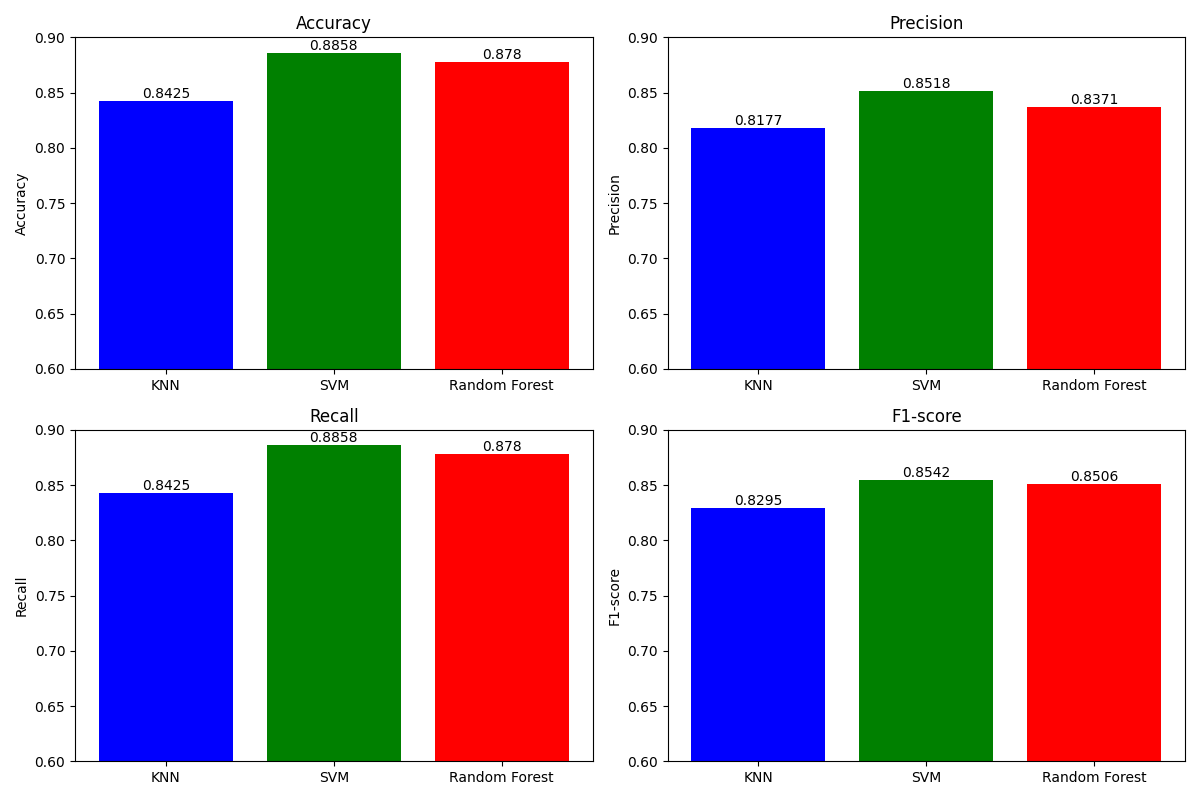
Adapun model KNN mendapatkan hasil accuracy, precision, recall, dan F1-score secara berturut-turut adalah 84.25%, 81.77%, 84.25%, dan 82.95%. Sementara SVM mendapatkan hasil accuracy, precision, recall, dan F1-score secara berturut-turut adalah 88.58%, 85.18%, 88.58%, dan 85.42%. Sedangkan Random Forest mendapatkan hasil accuracy, precision, recall, dan F1-score secara berturut-turut adalah 87.8%, 83.71%, 87.8%, dan 85.06%.
Dapat disimpulkan bahwa model dengan performa terbaik disemua metriks yang diberikan adalah SVM (Support Vector Machine).