The code in this repo can be used as a starting point for integrating with different types of Kafka PaaS offerings:
The ingestion notebooks for each platform have their own particularities due to the different libraries used for integrating with the Schema Registry (AWS Glue for MSK and Confluent Schema Registry for Confluent Kafka). There are also separate notebooks for Confluent and MSK which act as random event producers in order to facilitate simulations.
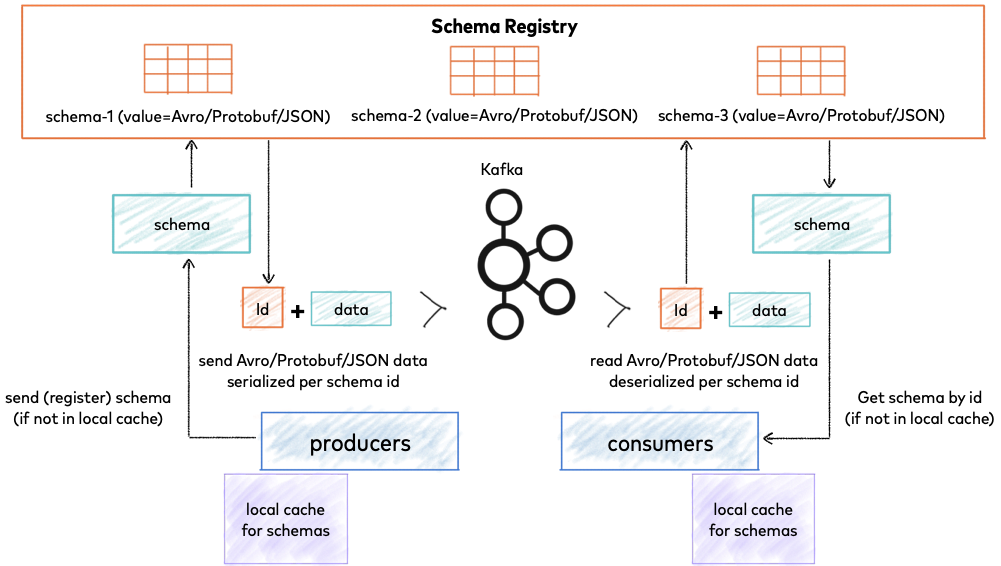
Kafka Streaming has some challenges when it comes to Avro Evolving Schemas with multiple versions. It might be complex to deal with this scenario when developing Databricks Spark Structured Streaming applications. In these notebooks, we present basic examples of integrating with Kafka Schema Registries in both MSK and Confluent, in a fictitious scenario where there are multiple Avro Schema versions.
- An AWS MSK or Confluent Kafka broker
- Make sure to store the relevant configurations and authentication info in Databricks Secret Scopes
- For AWS MSK, make sure that there is an instance profile attached to the cluster which gives the necessary permissions to integrate with MSK and Glue
- Maven Dependencies
- For AWS MSK:
- org.jetbrains.kotlinx:kotlinx-coroutines-core:1.5.2
- software.amazon.glue:schema-registry-serde:1.1.4
- software.amazon.glue:schema-registry-common:1.1.4
- org.apache.kafka:kafka-clients:3.0.0
- For Confluent:
- kafka_schema_registry_client_5_3_1.jar
- kafka_clients_2_6_0.jar
- It is really important that these exact versions are used, otherwise it won't work.
- Highly recommended to upload the jar files into DBFS and install from there, so that they can be quickly installed when job clusters are created
- If you plan on running examples for both MSK and Confluent, make sure to use separate clusters, so that there is not conflict amongst the dependencies
- For AWS MSK:
- Copy the Avro schemas in the schemas folder into a location in DBFS
- Reference that location in the notebooks
- Configure secret scopes for the Kafka authentication and Schema Registry parameters
- Start the producer notebook - random events will be generated and published into your Kafka broker(s)
- You can then:
- Manually start the ingestion, bronze, silver and gold notebooks, or
- Deploy Databricks Jobs/Workflows with Terraform
- Make sure to replace the necessary parameters in the TF files prior to deploying the jobs
Terraform IaC scripts for deploying Databricks Jobs into Workspaces